 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantile Off-Policy Evaluation via Deep Conditional Generative Learning
Paper and Code
Dec 29, 2022

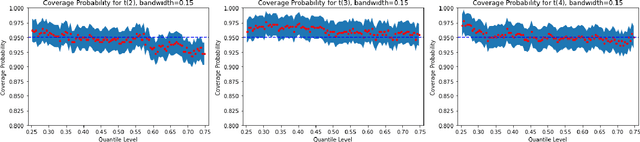

Off-Policy evaluation (OPE) is concerned with evaluating a new target policy using offline data generated by a potentially different behavior policy. It is critical in a number of sequential decision making problems ranging from healthcare to technology industries. Most of the work in existing literature is focused on evaluating the mean outcome of a given policy, and ignores the variability of the outcome. However, in a variety of applications, criteria other than the mean may be more sensible. For example, when the reward distribution is skewed and asymmetric, quantile-based metrics are often preferred for their robustness. In this paper, we propose a doubly-robust inference procedure for quantile OPE in sequential decision making and study its asymptotic properties. In particular, we propose utilizing state-of-the-art deep conditional generative learning methods to handle parameter-dependent nuisance function estimation. We demonstrate the advantages of this proposed estimator through both simulations and a real-world dataset from a short-video platform. In particular, we find that our proposed estimator outperforms classical OPE estimators for the mean in settings with heavy-tailed reward distributions.