 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistically Efficient Advantage Learning for Offline Reinforcement Learning in Infinite Horizons
Paper and Code
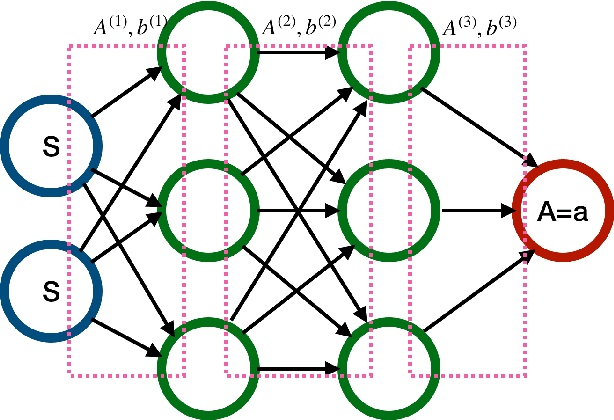
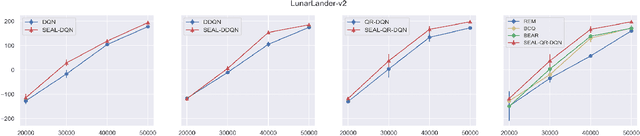
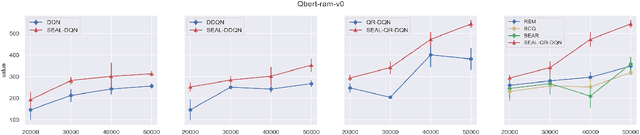

We consider reinforcement learning (RL) methods in offline domains without additional online data collection, such as mobile health applications. Most of existing policy optimization algorithms in the computer science literature are developed in online settings where data are easy to collect or simulate. Their generalizations to mobile health applications with a pre-collected offline dataset remain unknown. The aim of this paper is to develop a novel advantage learning framework in order to efficiently use pre-collected data for policy optimization. The proposed method takes an optimal Q-estimator computed by any existing state-of-the-art RL algorithms as input, and outputs a new policy whose value is guaranteed to converge at a faster rate than the policy derived based on the initial Q-estimator. Extensive numerical experiments are conducted to back up our theoretical findings.