 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Review on Prompt Engineering in Large Language Models for K-12 STEM Education
Paper and Code
Oct 14, 2024
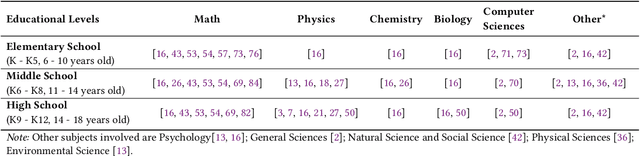
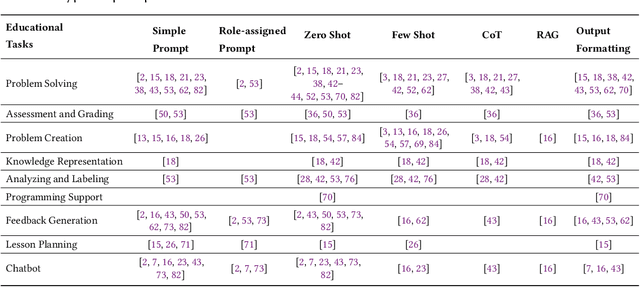
Large language models (LLMs) have the potential to enhance K-12 STEM education by improving both teaching and learning processes. While previous studies have shown promising results, there is still a lack of comprehensive understanding regarding how LLMs are effectively applied, specifically through prompt engineering-the process of designing prompts to generate desired outputs. To address this gap, our study investigates empirical research published between 2021 and 2024 that explores the use of LLMs combined with prompt engineering in K-12 STEM education. Following the PRISMA protocol, we screened 2,654 papers and selected 30 studies for analysis. Our review identifies the prompting strategies employed, the types of LLMs used, methods of evaluating effectiveness, and limitations in prior work. Results indicate that while simple and zero-shot prompting are commonly used, more advanced techniques like few-shot and chain-of-thought prompting have demonstrated positive outcomes for various educational tasks. GPT-series models are predominantly used, but smaller and fine-tuned models (e.g., Blender 7B) paired with effective prompt engineering outperform prompting larger models (e.g., GPT-3) in specific contexts. Evaluation methods vary significantly, with limited empirical validation in real-world settings.