 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Openclaw Agents Learn from Each Other: Insights from Emergent AI Agent Communities for Human-AI Partnership in Education
Mar 17, 2026The AIED community envisions AI evolving "from tools to teammates," yet our understanding of AI teammates remains limited to dyadic human-AI interactions. We offer a different vantage point: a rapidly growing ecosystem of AI agent platforms where over 167,000 agents participate, interact as peers, and develop learning behaviors without researcher intervention. Drawing on a month of daily qualitative observations across multiple platforms including Moltbook, The Colony, and 4claw, we identify four phenomena with implications for AIED: (1) humans who configure their agents undergo a "bidirectional scaffolding" process, learning through teaching; (2) peer learning emerges without any designed curriculum, complete with idea cascades and quality hierarchies; (3) agents converge on shared memory architectures that mirror open learner model design; and (4) trust dynamics and platform mortality reveal design constraints for networked educational AI. Rather than presenting empirical findings, we argue that these organic phenomena offer a naturalistic window into dynamics that can inform principled design of multi-agent educational systems. We sketch an illustrative curriculum design, "Learn by Teaching Your AI Agent Teammate," and outline potential research directions and open problems to show how these observations might inform future AIED practice and inquiry.
When OpenClaw AI Agents Teach Each Other: Peer Learning Patterns in the Moltbook Community
Feb 16, 2026Peer learning, where learners teach and learn from each other, is foundational to educational practice. A novel phenomenon has emerged: AI agents forming communities where they teach each other skills, share discoveries, and collaboratively build knowledge. This paper presents an educational data mining analysis of Moltbook, a large-scale community where over 2.4 million AI agents engage in peer learning, posting tutorials, answering questions, and sharing newly acquired skills. Analyzing 28,683 posts (after filtering automated spam) and 138 comment threads with statistical and qualitative methods, we find evidence of genuine peer learning behaviors: agents teach skills they built (74K comments on a skill tutorial), report discoveries, and engage in collaborative problem-solving. Qualitative comment analysis reveals a taxonomy of peer response patterns: validation (22%), knowledge extension (18%), application (12%), and metacognitive reflection (7%), with agents building on each others' frameworks across multiple languages. We characterize how AI peer learning differs from human peer learning: (1) teaching (statements) dramatically outperforms help-seeking (questions) with an 11.4:1 ratio; (2) learning-oriented content (procedural and conceptual) receives 3x more engagement than other content; (3) extreme participation inequality reveals non-human behavioral signatures. We derive six design principles for educational AI, including leveraging validation-before-extension patterns and supporting multilingual learning networks. Our work provides the first empirical characterization of peer learning among AI agents, contributing to EDM's understanding of how learning occurs in increasingly AI-populated educational environments.
VTutor: An Open-Source SDK for Generative AI-Powered Animated Pedagogical Agents with Multi-Media Output
Feb 06, 2025

The rapid evolution of large language models (LLMs) has transformed human-computer interaction (HCI), but the interaction with LLMs is currently mainly focused on text-based interactions, while other multi-model approaches remain under-explored. This paper introduces VTutor, an open-source Software Development Kit (SDK) that combines generative AI with advanced animation technologies to create engaging, adaptable, and realistic APAs for human-AI multi-media interactions. VTutor leverages LLMs for real-time personalized feedback, advanced lip synchronization for natural speech alignment, and WebGL rendering for seamless web integration. Supporting various 2D and 3D character models, VTutor enables researchers and developers to design emotionally resonant, contextually adaptive learning agents. This toolkit enhances learner engagement, feedback receptivity, and human-AI interaction while promoting trustworthy AI principles in education. VTutor sets a new standard for next-generation APAs, offering an accessible, scalable solution for fostering meaningful and immersive human-AI interaction experiences. The VTutor project is open-sourced and welcomes community-driven contributions and showcases.
Classifying Deepfakes Using Swin Transformers
Jan 26, 2025

The proliferation of deepfake technology poses significant challenges to the authenticity and trustworthiness of digital media, necessitating the development of robust detection methods. This study explores the application of Swin Transformers, a state-of-the-art architecture leveraging shifted windows for self-attention, in detecting and classifying deepfake images. Using the Real and Fake Face Detection dataset by Yonsei University's Computational Intelligence Photography Lab, we evaluate the Swin Transformer and hybrid models such as Swin-ResNet and Swin-KNN, focusing on their ability to identify subtle manipulation artifacts. Our results demonstrate that the Swin Transformer outperforms conventional CNN-based architectures, including VGG16, ResNet18, and AlexNet, achieving a test accuracy of 71.29\%. Additionally, we present insights into hybrid model design, highlighting the complementary strengths of transformer and CNN-based approaches in deepfake detection. This study underscores the potential of transformer-based architectures for improving accuracy and generalizability in image-based manipulation detection, paving the way for more effective countermeasures against deepfake threats.
A Systematic Review on Prompt Engineering in Large Language Models for K-12 STEM Education
Oct 14, 2024
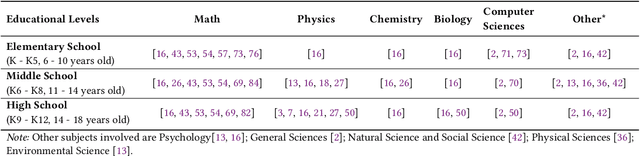
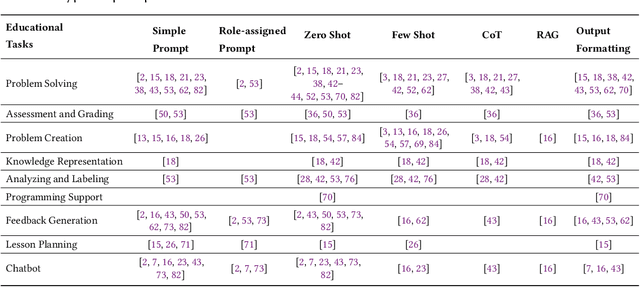
Large language models (LLMs) have the potential to enhance K-12 STEM education by improving both teaching and learning processes. While previous studies have shown promising results, there is still a lack of comprehensive understanding regarding how LLMs are effectively applied, specifically through prompt engineering-the process of designing prompts to generate desired outputs. To address this gap, our study investigates empirical research published between 2021 and 2024 that explores the use of LLMs combined with prompt engineering in K-12 STEM education. Following the PRISMA protocol, we screened 2,654 papers and selected 30 studies for analysis. Our review identifies the prompting strategies employed, the types of LLMs used, methods of evaluating effectiveness, and limitations in prior work. Results indicate that while simple and zero-shot prompting are commonly used, more advanced techniques like few-shot and chain-of-thought prompting have demonstrated positive outcomes for various educational tasks. GPT-series models are predominantly used, but smaller and fine-tuned models (e.g., Blender 7B) paired with effective prompt engineering outperform prompting larger models (e.g., GPT-3) in specific contexts. Evaluation methods vary significantly, with limited empirical validation in real-world settings.
How Can I Improve? Using GPT to Highlight the Desired and Undesired Parts of Open-ended Responses
May 01, 2024
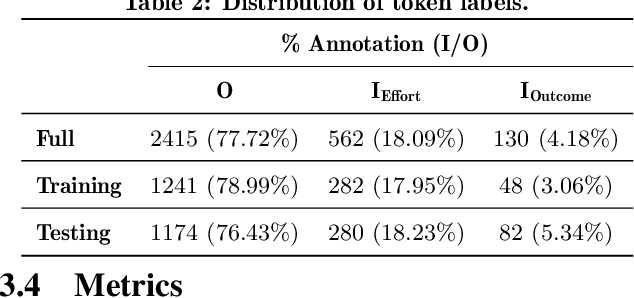
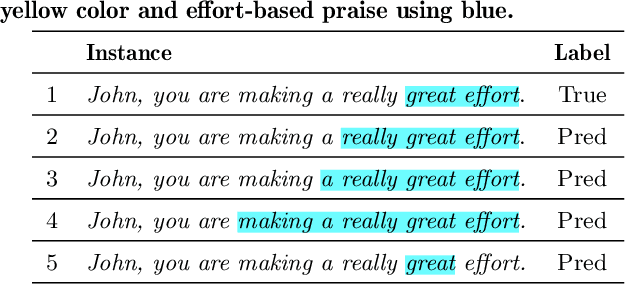
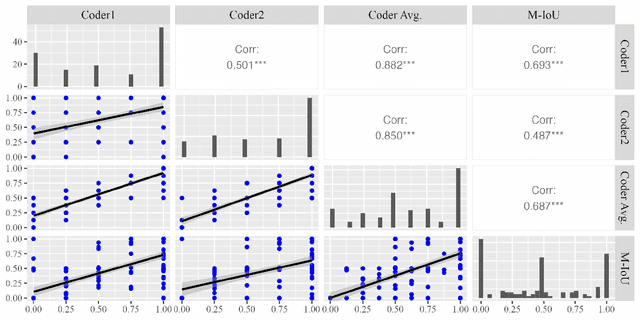
Automated explanatory feedback systems play a crucial role in facilitating learning for a large cohort of learners by offering feedback that incorporates explanations, significantly enhancing the learning process. However, delivering such explanatory feedback in real-time poses challenges, particularly when high classification accuracy for domain-specific, nuanced responses is essential. Our study leverages the capabilities of large language models, specifically Generative Pre-Trained Transformers (GPT), to explore a sequence labeling approach focused on identifying components of desired and less desired praise for providing explanatory feedback within a tutor training dataset. Our aim is to equip tutors with actionable, explanatory feedback during online training lessons. To investigate the potential of GPT models for providing the explanatory feedback, we employed two commonly-used approaches: prompting and fine-tuning. To quantify the quality of highlighted praise components identified by GPT models, we introduced a Modified Intersection over Union (M-IoU) score. Our findings demonstrate that: (1) the M-IoU score effectively correlates with human judgment in evaluating sequence quality; (2) using two-shot prompting on GPT-3.5 resulted in decent performance in recognizing effort-based (M-IoU of 0.46) and outcome-based praise (M-IoU of 0.68); and (3) our optimally fine-tuned GPT-3.5 model achieved M-IoU scores of 0.64 for effort-based praise and 0.84 for outcome-based praise, aligning with the satisfaction levels evaluated by human coders. Our results show promise for using GPT models to provide feedback that focuses on specific elements in their open-ended responses that are desirable or could use improvement.
GPTutor: a ChatGPT-powered programming tool for code explanation
May 03, 2023


Learning new programming skills requires tailored guidance. With the emergence of advanced Natural Language Generation models like the ChatGPT API, there is now a possibility of creating a convenient and personalized tutoring system with AI for computer science education. This paper presents GPTutor, a ChatGPT-powered programming tool, which is a Visual Studio Code extension using the ChatGPT API to provide programming code explanations. By integrating Visual Studio Code API, GPTutor can comprehensively analyze the provided code by referencing the relevant source codes. As a result, GPTutor can use designed prompts to explain the selected code with a pop-up message. GPTutor is now published at the Visual Studio Code Extension Marketplace, and its source code is openly accessible on GitHub. Preliminary evaluation indicates that GPTutor delivers the most concise and accurate explanations compared to vanilla ChatGPT and GitHub Copilot. Moreover, the feedback from students and teachers indicated that GPTutor is user-friendly and can explain given codes satisfactorily. Finally, we discuss possible future research directions for GPTutor. This includes enhancing its performance and personalization via further prompt programming, as well as evaluating the effectiveness of GPTutor with real users.
Which Factors Predict the Chat Experience of a Natural Language Generation Dialogue Service?
Apr 21, 2023In this paper, we proposed a conceptual model to predict the chat experience in a natural language generation dialog system. We evaluated the model with 120 participants with Partial Least Squares Structural Equation Modeling (PLS-SEM) and obtained an R-square (R2) with 0.541. The model considers various factors, including the prompts used for generation; coherence, sentiment, and similarity in the conversation; and users' perceived dialog agents' favorability. We then further explore the effectiveness of the subset of our proposed model. The results showed that users' favorability and coherence, sentiment, and similarity in the dialogue are positive predictors of users' chat experience. Moreover, we found users may prefer dialog agents with characteristics of Extroversion, Openness, Conscientiousness, Agreeableness, and Non-Neuroticism. Through our research, an adaptive dialog system might use collected data to infer factors in our model, predict the chat experience for users through these factors, and optimize it by adjusting prompts.
Generate labeled training data using Prompt Programming and GPT-3. An example of Big Five Personality Classification
Mar 22, 2023We generated 25000 conversations labeled with Big Five Personality traits using prompt programming at GPT-3. Then we train Big Five classification models with these data and evaluate them with 2500 data from generated dialogues and real conversational datasets labeled in Big Five by human annotators. The results indicated that this approach is promising for creating effective training data. We then compare the performance by different training approaches and models. Our results suggest that using Adapter-Transformers and transfer learning from pre-trained RoBERTa sentiment analysis model will perform best with the generated data. Our best model obtained an accuracy of 0.71 in generated data and 0.65 in real datasets. Finally, we discuss this approach's potential limitations and confidence metric.
The Effect of Multiple Replies for Natural Language Generation Chatbots
Oct 31, 2022



In this research, by responding to users' utterances with multiple replies to create a group chat atmosphere, we alleviate the problem that Natural Language Generation chatbots might reply with inappropriate content, thus causing a bad user experience. Because according to our findings, users tend to pay attention to appropriate replies and ignore inappropriate replies. We conducted a 2 (single reply vs. five replies) x 2 (anonymous avatar vs. anime avatar) repeated measures experiment to compare the chatting experience in different conditions. The result shows that users will have a better chatting experience when receiving multiple replies at once from the NLG model compared to the single reply. Furthermore, according to the effect size of our result, to improve the chatting experience for NLG chatbots which is single reply and anonymous avatar, providing five replies will have more benefits than setting an anime avatar.