 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can I Improve? Using GPT to Highlight the Desired and Undesired Parts of Open-ended Responses
May 01, 2024
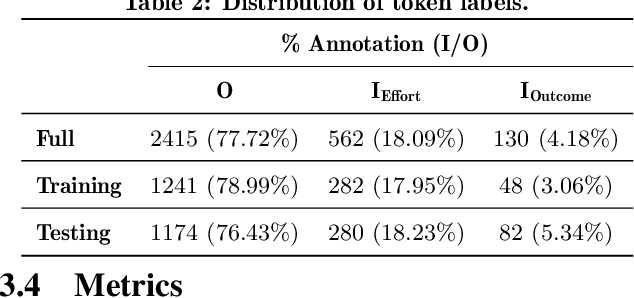
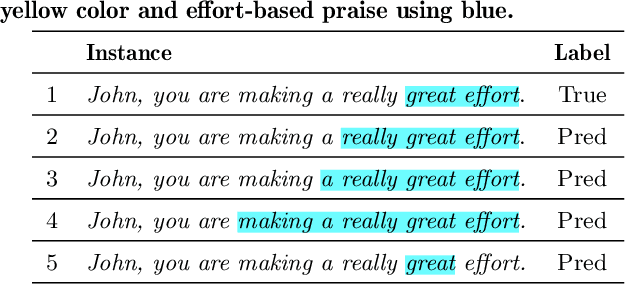
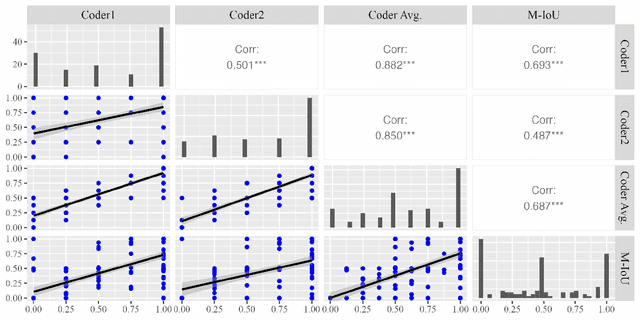
Automated explanatory feedback systems play a crucial role in facilitating learning for a large cohort of learners by offering feedback that incorporates explanations, significantly enhancing the learning process. However, delivering such explanatory feedback in real-time poses challenges, particularly when high classification accuracy for domain-specific, nuanced responses is essential. Our study leverages the capabilities of large language models, specifically Generative Pre-Trained Transformers (GPT), to explore a sequence labeling approach focused on identifying components of desired and less desired praise for providing explanatory feedback within a tutor training dataset. Our aim is to equip tutors with actionable, explanatory feedback during online training lessons. To investigate the potential of GPT models for providing the explanatory feedback, we employed two commonly-used approaches: prompting and fine-tuning. To quantify the quality of highlighted praise components identified by GPT models, we introduced a Modified Intersection over Union (M-IoU) score. Our findings demonstrate that: (1) the M-IoU score effectively correlates with human judgment in evaluating sequence quality; (2) using two-shot prompting on GPT-3.5 resulted in decent performance in recognizing effort-based (M-IoU of 0.46) and outcome-based praise (M-IoU of 0.68); and (3) our optimally fine-tuned GPT-3.5 model achieved M-IoU scores of 0.64 for effort-based praise and 0.84 for outcome-based praise, aligning with the satisfaction levels evaluated by human coders. Our results show promise for using GPT models to provide feedback that focuses on specific elements in their open-ended responses that are desirable or could use improvement.