 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph of States: Solving Abductive Tasks with Large Language Models
Mar 22, 2026Logical reasoning encompasses deduction, induction, and abduction. However, while Large Language Models (LLMs) have effectively mastered the former two, abductive reasoning remains significantly underexplored. Existing frameworks, predominantly designed for static deductive tasks, fail to generalize to abductive reasoning due to unstructured state representation and lack of explicit state control. Consequently, they are inevitably prone to Evidence Fabrication, Context Drift, Failed Backtracking, and Early Stopping. To bridge this gap, we introduce Graph of States (GoS), a general-purpose neuro-symbolic framework tailored for abductive tasks. GoS grounds multi-agent collaboration in a structured belief states, utilizing a causal graph to explicitly encode logical dependencies and a state machine to govern the valid transitions of the reasoning process. By dynamically aligning the reasoning focus with these symbolic constraints, our approach transforms aimless, unconstrained exploration into a convergent, directed search. Extensive evaluations on two real-world datasets demonstrate that GoS significantly outperforms all baselines, providing a robust solution for complex abductive tasks. Code repo and all prompts: https://anonymous.4open.science/r/Graph-of-States-5B4E.
LogPurge: Log Data Purification for Anomaly Detection via Rule-Enhanced Filtering
Nov 18, 2025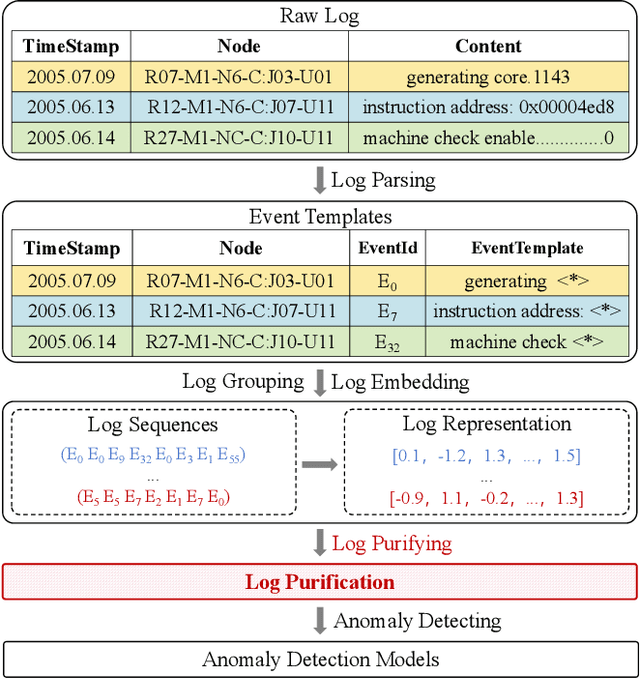
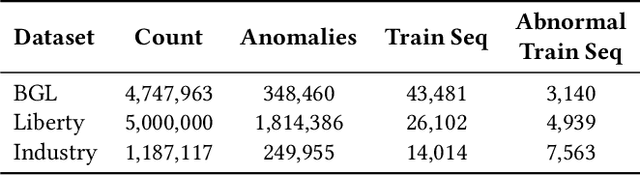
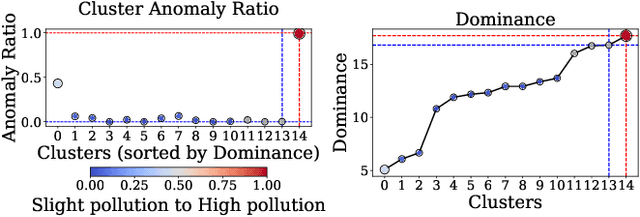
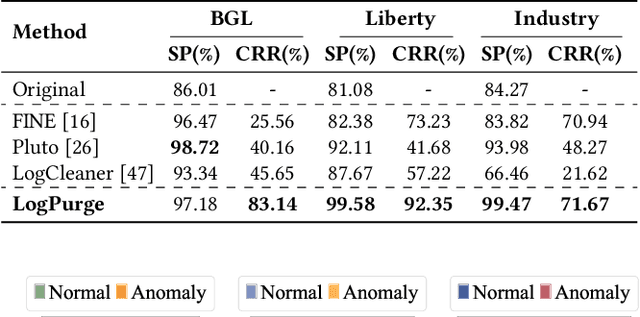
Log anomaly detection, which is critical for identifying system failures and preempting security breaches, detects irregular patterns within large volumes of log data, and impacts domains such as service reliability, performance optimization, and database log analysis. Modern log anomaly detection methods rely on training deep learning models on clean, anomaly-free log sequences. However, obtaining such clean log data requires costly and tedious human labeling, and existing automatic cleaning methods fail to fully integrate the specific characteristics and actual semantics of logs in their purification process. In this paper, we propose a cost-aware, rule-enhanced purification framework, LogPurge, that automatically selects a sufficient subset of normal log sequences from contamination log sequences to train a anomaly detection model. Our approach involves a two-stage filtering algorithm: In the first stage, we use a large language model (LLM) to remove clustered anomalous patterns and enhance system rules to improve LLM's understanding of system logs; in the second stage, we utilize a divide-and-conquer strategy that decomposes the remaining contaminated regions into smaller subproblems, allowing each to be effectively purified through the first stage procedure. Our experiments, conducted on two public datasets and one industrial dataset, show that our method significantly removes an average of 98.74% of anomalies while retaining 82.39% of normal samples. Compared to the latest unsupervised log sample selection algorithms, our method achieves F-1 score improvements of 35.7% and 84.11% on the public datasets, and an impressive 149.72% F-1 improvement on the private dataset, demonstrating the effectiveness of our approach.
RationAnomaly: Log Anomaly Detection with Rationality via Chain-of-Thought and Reinforcement Learning
Sep 18, 2025Logs constitute a form of evidence signaling the operational status of software systems. Automated log anomaly detection is crucial for ensuring the reliability of modern software systems. However, existing approaches face significant limitations: traditional deep learning models lack interpretability and generalization, while methods leveraging Large Language Models are often hindered by unreliability and factual inaccuracies. To address these issues, we propose RationAnomaly, a novel framework that enhances log anomaly detection by synergizing Chain-of-Thought (CoT) fine-tuning with reinforcement learning. Our approach first instills expert-like reasoning patterns using CoT-guided supervised fine-tuning, grounded in a high-quality dataset corrected through a rigorous expert-driven process. Subsequently, a reinforcement learning phase with a multi-faceted reward function optimizes for accuracy and logical consistency, effectively mitigating hallucinations. Experimentally, RationAnomaly outperforms state-of-the-art baselines, achieving superior F1-scores on key benchmarks while providing transparent, step-by-step analytical outputs. We have released the corresponding resources, including code and datasets.
A High-Quality Dataset and Reliable Evaluation for Interleaved Image-Text Generation
Jun 11, 2025Recent advancements in Large Multimodal Models (LMMs) have significantly improved multimodal understanding and generation. However, these models still struggle to generate tightly interleaved image-text outputs, primarily due to the limited scale, quality and instructional richness of current training datasets. To address this, we introduce InterSyn, a large-scale multimodal dataset constructed using our Self-Evaluation with Iterative Refinement (SEIR) method. InterSyn features multi-turn, instruction-driven dialogues with tightly interleaved imagetext responses, providing rich object diversity and rigorous automated quality refinement, making it well-suited for training next-generation instruction-following LMMs. Furthermore, to address the lack of reliable evaluation tools capable of assessing interleaved multimodal outputs, we introduce SynJudge, an automatic evaluation model designed to quantitatively assess multimodal outputs along four dimensions: text content, image content, image quality, and image-text synergy. Experimental studies show that the SEIR method leads to substantially higher dataset quality compared to an otherwise identical process without refinement. Moreover, LMMs trained on InterSyn achieve uniform performance gains across all evaluation metrics, confirming InterSyn's utility for advancing multimodal systems.
ARMOR v0.1: Empowering Autoregressive Multimodal Understanding Model with Interleaved Multimodal Generation via Asymmetric Synergy
Mar 09, 2025



Unified models (UniMs) for multimodal understanding and generation have recently received much attention in the area of vision and language. Existing UniMs are designed to simultaneously learn both multimodal understanding and generation capabilities, demanding substantial computational resources, and often struggle to generate interleaved text-image. We present ARMOR, a resource-efficient and pure autoregressive framework that achieves both understanding and generation by fine-tuning existing multimodal large language models (MLLMs). Specifically, ARMOR extends existing MLLMs from three perspectives: (1) For model architecture, an asymmetric encoder-decoder architecture with a forward-switching mechanism is introduced to unify embedding space integrating textual and visual modalities for enabling natural text-image interleaved generation with minimal computational overhead. (2) For training data, a meticulously curated, high-quality interleaved dataset is collected for fine-tuning MLLMs. (3) For the training algorithm, we propose a ``what or how to generate" algorithm to empower existing MLLMs with multimodal generation capabilities while preserving their multimodal understanding capabilities, through three progressive training stages based on the collected dataset. Experimental results demonstrate that ARMOR upgrades existing MLLMs to UniMs with promising image generation capabilities, using limited training resources. Our code will be released soon at https://armor.github.io.
LogLM: From Task-based to Instruction-based Automated Log Analysis
Oct 12, 2024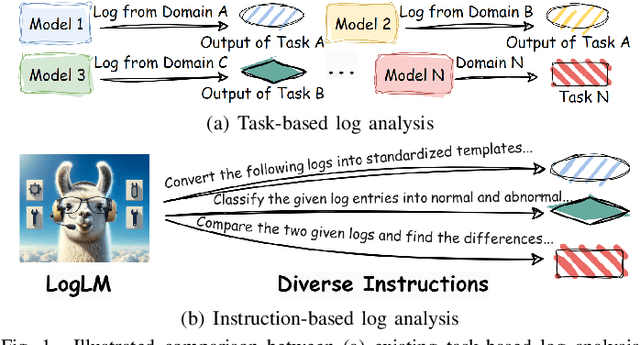
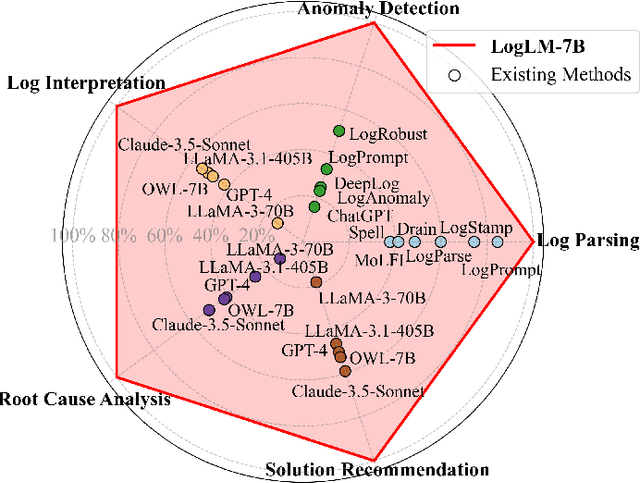

Automatic log analysis is essential for the efficient Operation and Maintenance (O&M) of software systems, providing critical insights into system behaviors. However, existing approaches mostly treat log analysis as training a model to perform an isolated task, using task-specific log-label pairs. These task-based approaches are inflexible in generalizing to complex scenarios, depend on task-specific training data, and cost significantly when deploying multiple models. In this paper, we propose an instruction-based training approach that transforms log-label pairs from multiple tasks and domains into a unified format of instruction-response pairs. Our trained model, LogLM, can follow complex user instructions and generalize better across different tasks, thereby increasing flexibility and reducing the dependence on task-specific training data. By integrating major log analysis tasks into a single model, our approach also relieves model deployment burden. Experimentally, LogLM outperforms existing approaches across five log analysis capabilities, and exhibits strong generalization abilities on complex instructions and unseen tasks.
Enhanced Fine-Tuning of Lightweight Domain-Specific Q&A Model Based on Large Language Models
Aug 23, 2024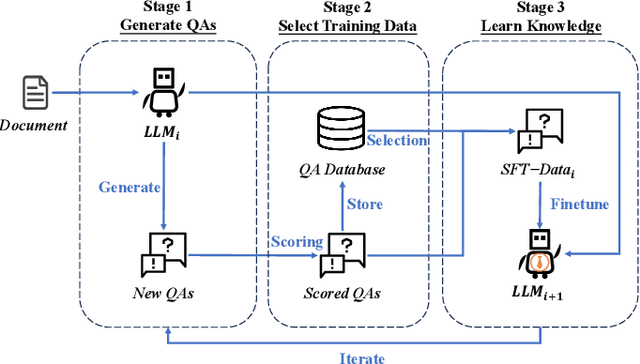
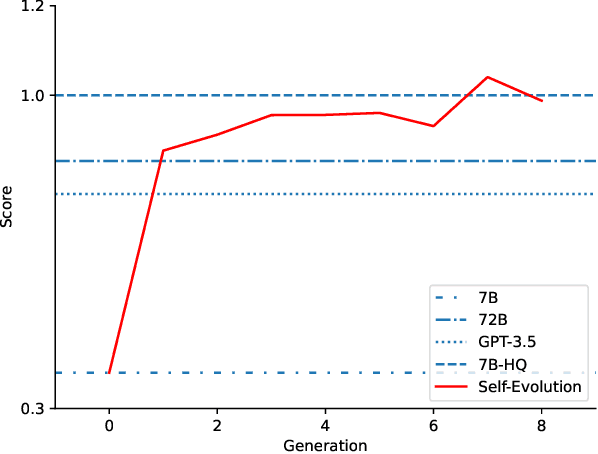
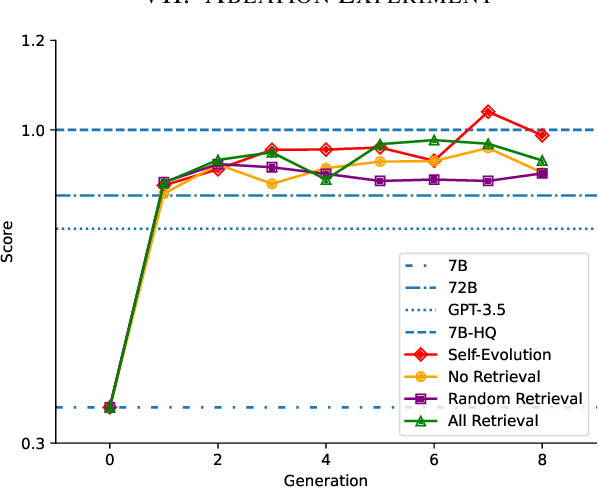

Large language models (LLMs) excel at general question-answering (Q&A) but often fall short in specialized domains due to a lack of domain-specific knowledge. Commercial companies face the dual challenges of privacy protection and resource constraints when involving LLMs for fine-tuning. This paper propose a novel framework, Self-Evolution, designed to address these issues by leveraging lightweight open-source LLMs through multiple iterative fine-tuning rounds. To enhance the efficiency of iterative fine-tuning, Self-Evolution employ a strategy that filters and reinforces the knowledge with higher value during the iterative process. We employed Self-Evolution on Qwen1.5-7B-Chat using 4,000 documents containing rich domain knowledge from China Mobile, achieving a performance score 174% higher on domain-specific question-answering evaluations than Qwen1.5-7B-Chat and even 22% higher than Qwen1.5-72B-Chat. Self-Evolution has been deployed in China Mobile's daily operation and maintenance for 117 days, and it improves the efficiency of locating alarms, fixing problems, and finding related reports, with an average efficiency improvement of over 18.6%. In addition, we release Self-Evolution framework code in https://github.com/Zero-Pointer/Self-Evolution.
LogEval: A Comprehensive Benchmark Suite for Large Language Models In Log Analysis
Jul 02, 2024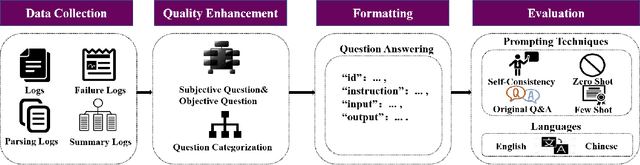
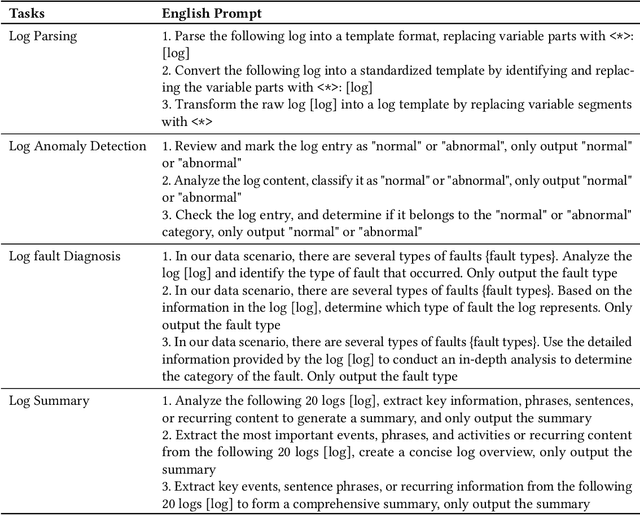

Log analysis is crucial for ensuring the orderly and stable operation of information systems, particularly in the field of Artificial Intelligence for IT Operations (AIOps). Large Language Models (LLMs) have demonstrated significant potential in natural language processing tasks. In the AIOps domain, they excel in tasks such as anomaly detection, root cause analysis of faults, operations and maintenance script generation, and alert information summarization. However, the performance of current LLMs in log analysis tasks remains inadequately validated. To address this gap, we introduce LogEval, a comprehensive benchmark suite designed to evaluate the capabilities of LLMs in various log analysis tasks for the first time. This benchmark covers tasks such as log parsing, log anomaly detection, log fault diagnosis, and log summarization. LogEval evaluates each task using 4,000 publicly available log data entries and employs 15 different prompts for each task to ensure a thorough and fair assessment. By rigorously evaluating leading LLMs, we demonstrate the impact of various LLM technologies on log analysis performance, focusing on aspects such as self-consistency and few-shot contextual learning. We also discuss findings related to model quantification, Chinese-English question-answering evaluation, and prompt engineering. These findings provide insights into the strengths and weaknesses of LLMs in multilingual environments and the effectiveness of different prompt strategies. Various evaluation methods are employed for different tasks to accurately measure the performance of LLMs in log analysis, ensuring a comprehensive assessment. The insights gained from LogEvals evaluation reveal the strengths and limitations of LLMs in log analysis tasks, providing valuable guidance for researchers and practitioners.
TimeSeriesBench: An Industrial-Grade Benchmark for Time Series Anomaly Detection Models
Feb 26, 2024Driven by the proliferation of real-world application scenarios and scales, time series anomaly detection (TSAD) has attracted considerable scholarly and industrial interest. However, existing algorithms exhibit a gap in terms of training paradigm, online detection paradigm, and evaluation criteria when compared to the actual needs of real-world industrial systems. Firstly, current algorithms typically train a specific model for each individual time series. In a large-scale online system with tens of thousands of curves, maintaining such a multitude of models is impractical. The performance of using merely one single unified model to detect anomalies remains unknown. Secondly, most TSAD models are trained on the historical part of a time series and are tested on its future segment. In distributed systems, however, there are frequent system deployments and upgrades, with new, previously unseen time series emerging daily. The performance of testing newly incoming unseen time series on current TSAD algorithms remains unknown. Lastly, although some papers have conducted detailed surveys, the absence of an online evaluation platform prevents answering questions like "Who is the best at anomaly detection at the current stage?" In this paper, we propose TimeSeriesBench, an industrial-grade benchmark that we continuously maintain as a leaderboard. On this leaderboard, we assess the performance of existing algorithms across more than 168 evaluation settings combining different training and testing paradigms, evaluation metrics and datasets. Through our comprehensive analysis of the results, we provide recommendations for the future design of anomaly detection algorithms. To address known issues with existing public datasets, we release an industrial dataset to the public together with TimeSeriesBench. All code, data, and the online leaderboard have been made publicly available.
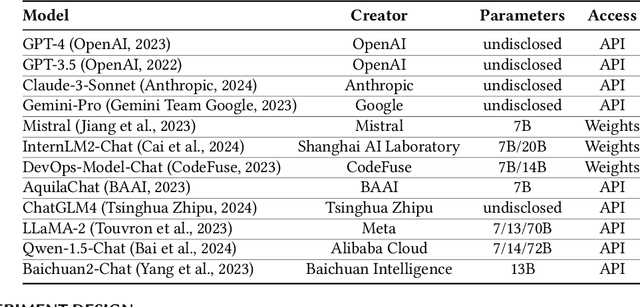
OpsEval: A Comprehensive Task-Oriented AIOps Benchmark for Large Language Models
Oct 12, 2023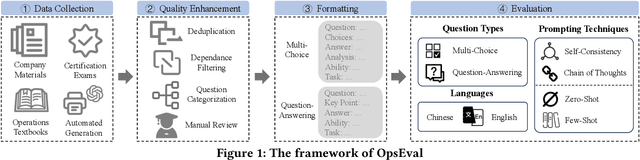
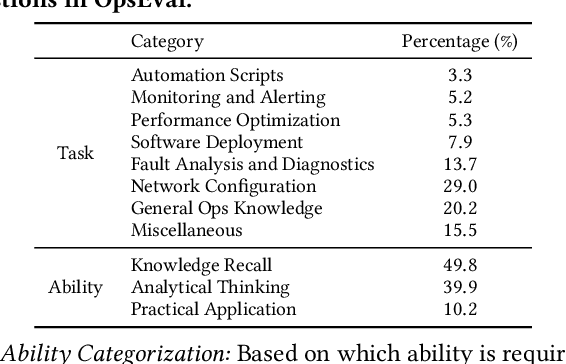

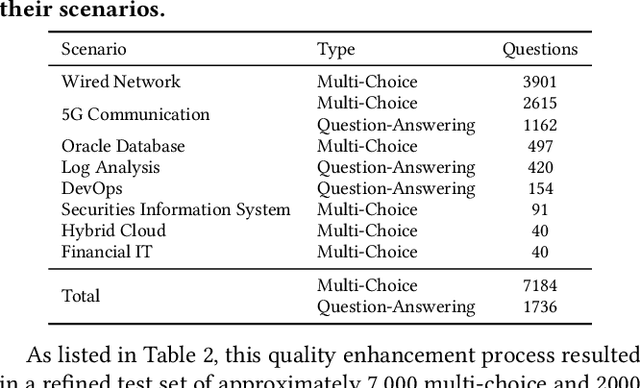
Large language models (LLMs) have exhibited remarkable capabilities in NLP-related tasks such as translation, summarizing, and generation. The application of LLMs in specific areas, notably AIOps (Artificial Intelligence for IT Operations), holds great potential due to their advanced abilities in information summarizing, report analyzing, and ability of API calling. Nevertheless, the performance of current LLMs in AIOps tasks is yet to be determined. Furthermore, a comprehensive benchmark is required to steer the optimization of LLMs tailored for AIOps. Compared with existing benchmarks that focus on evaluating specific fields like network configuration, in this paper, we present \textbf{OpsEval}, a comprehensive task-oriented AIOps benchmark designed for LLMs. For the first time, OpsEval assesses LLMs' proficiency in three crucial scenarios (Wired Network Operation, 5G Communication Operation, and Database Operation) at various ability levels (knowledge recall, analytical thinking, and practical application). The benchmark includes 7,200 questions in both multiple-choice and question-answer (QA) formats, available in English and Chinese. With quantitative and qualitative results, we show how various LLM tricks can affect the performance of AIOps, including zero-shot, chain-of-thought, and few-shot in-context learning. We find that GPT4-score is more consistent with experts than widely used Bleu and Rouge, which can be used to replace automatic metrics for large-scale qualitative evaluations.