 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Large Language Models to Log Analysis with Interpretable Domain Knowledge
Dec 02, 2024The increasing complexity of computer systems necessitates innovative approaches to fault and error management, going beyond traditional manual log analysis. While existing solutions using large language models (LLMs) show promise, they are limited by a gap between natural and domain-specific languages, which restricts their effectiveness in real-world applications. Our approach addresses these limitations by integrating interpretable domain knowledge into open-source LLMs through continual pre-training (CPT), enhancing performance on log tasks while retaining natural language processing capabilities. We created a comprehensive dataset, NLPLog, with over 250,000 question-answer pairs to facilitate this integration. Our model, SuperLog, trained with this dataset, achieves the best performance across four log analysis tasks, surpassing the second-best model by an average of 12.01%. Our contributions include a novel CPT paradigm that significantly improves model performance, the development of SuperLog with state-of-the-art results, and the release of a large-scale dataset to support further research in this domain.
LogLM: From Task-based to Instruction-based Automated Log Analysis
Oct 12, 2024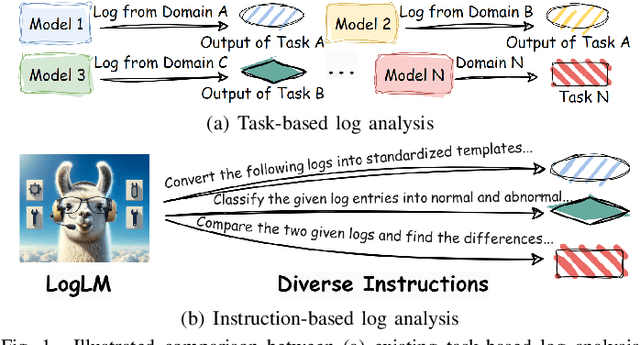
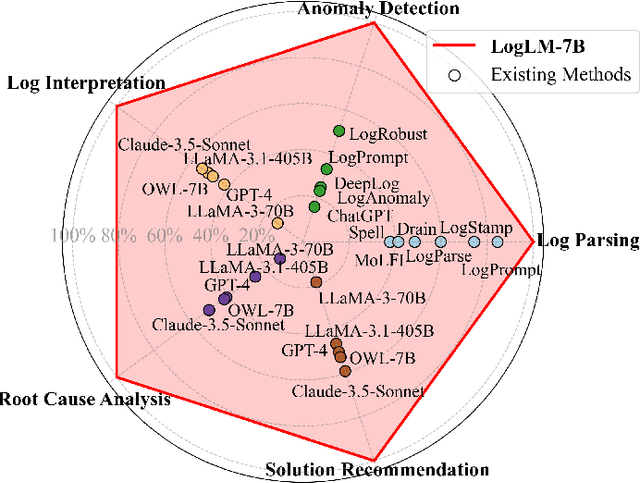

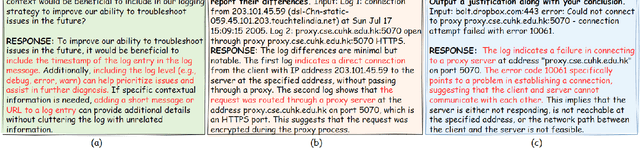
Automatic log analysis is essential for the efficient Operation and Maintenance (O&M) of software systems, providing critical insights into system behaviors. However, existing approaches mostly treat log analysis as training a model to perform an isolated task, using task-specific log-label pairs. These task-based approaches are inflexible in generalizing to complex scenarios, depend on task-specific training data, and cost significantly when deploying multiple models. In this paper, we propose an instruction-based training approach that transforms log-label pairs from multiple tasks and domains into a unified format of instruction-response pairs. Our trained model, LogLM, can follow complex user instructions and generalize better across different tasks, thereby increasing flexibility and reducing the dependence on task-specific training data. By integrating major log analysis tasks into a single model, our approach also relieves model deployment burden. Experimentally, LogLM outperforms existing approaches across five log analysis capabilities, and exhibits strong generalization abilities on complex instructions and unseen tasks.
What Do You Want? User-centric Prompt Generation for Text-to-image Synthesis via Multi-turn Guidance
Aug 23, 2024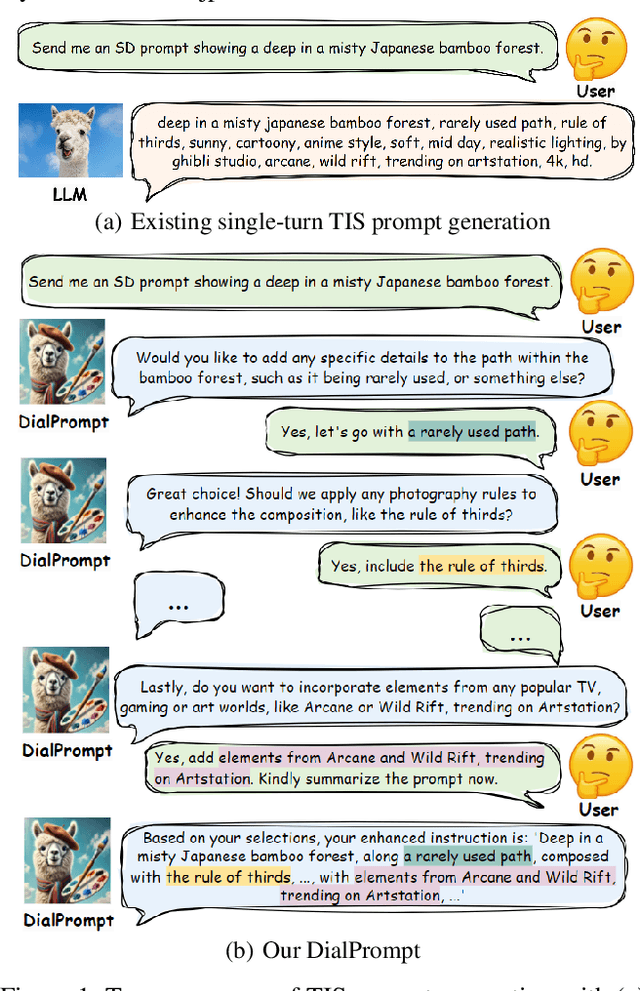
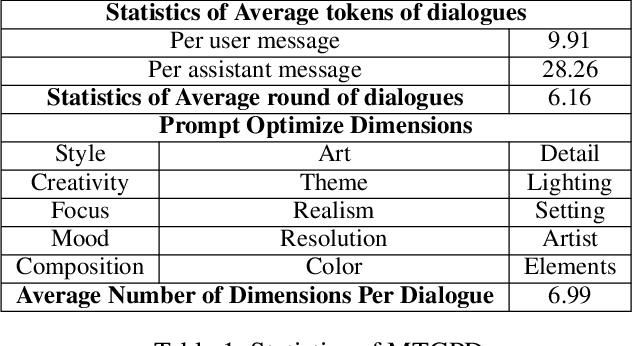
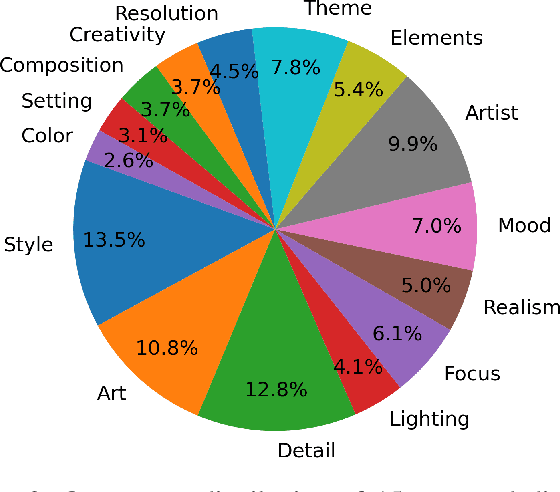
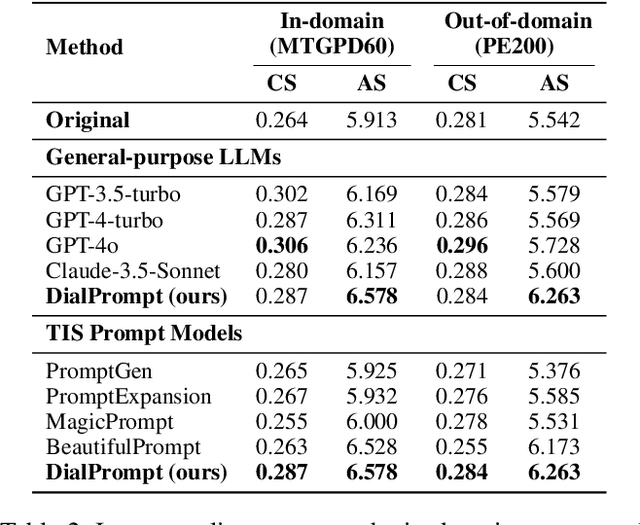
The emergence of text-to-image synthesis (TIS) models has significantly influenced digital image creation by producing high-quality visuals from written descriptions. Yet these models heavily rely on the quality and specificity of textual prompts, posing a challenge for novice users who may not be familiar with TIS-model-preferred prompt writing. Existing solutions relieve this via automatic model-preferred prompt generation from user queries. However, this single-turn manner suffers from limited user-centricity in terms of result interpretability and user interactivity. To address these issues, we propose DialPrompt, a multi-turn dialogue-based TIS prompt generation model that emphasises user-centricity. DialPrompt is designed to follow a multi-turn guidance workflow, where in each round of dialogue the model queries user with their preferences on possible optimization dimensions before generating the final TIS prompt. To achieve this, we mined 15 essential dimensions for high-quality prompts from advanced users and curated a multi-turn dataset. Through training on this dataset, DialPrompt can improve interpretability by allowing users to understand the correlation between specific phrases and image attributes. Additionally, it enables greater user control and engagement in the prompt generation process, leading to more personalized and visually satisfying outputs. Experiments indicate that DialPrompt achieves a competitive result in the quality of synthesized images, outperforming existing prompt engineering approaches by 5.7%. Furthermore, in our user evaluation, DialPrompt outperforms existing approaches by 46.5% in user-centricity score and is rated 7.9/10 by 19 human reviewers.