 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do You Want? User-centric Prompt Generation for Text-to-image Synthesis via Multi-turn Guidance
Paper and Code
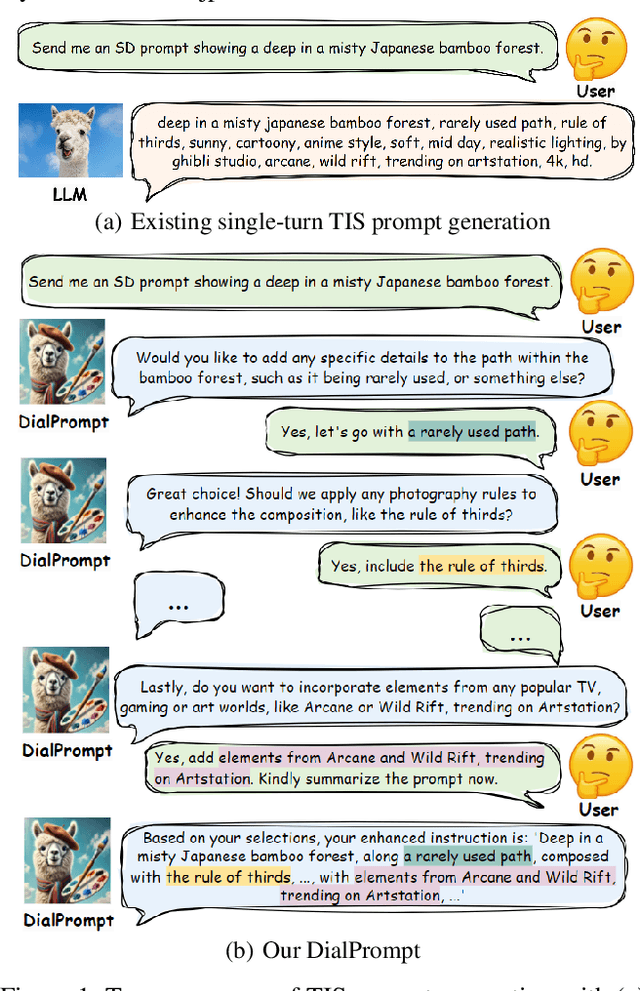
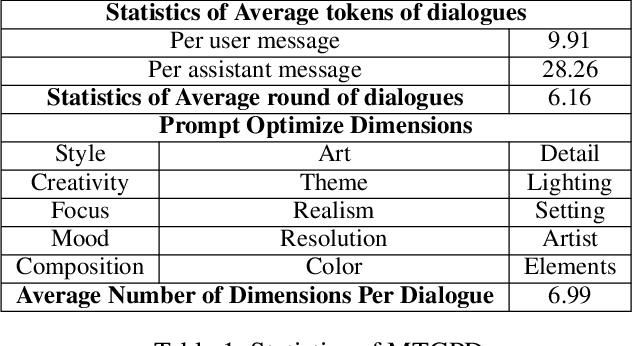
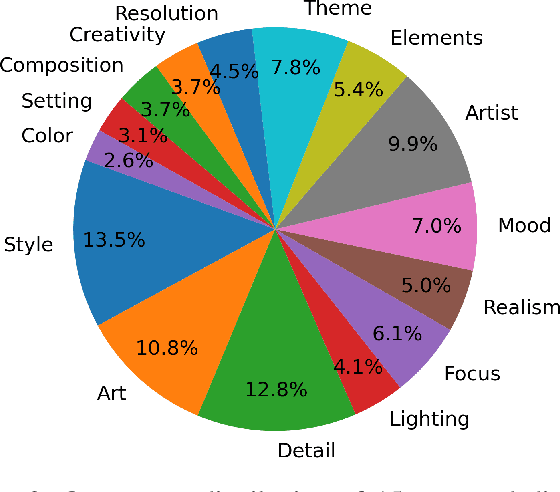
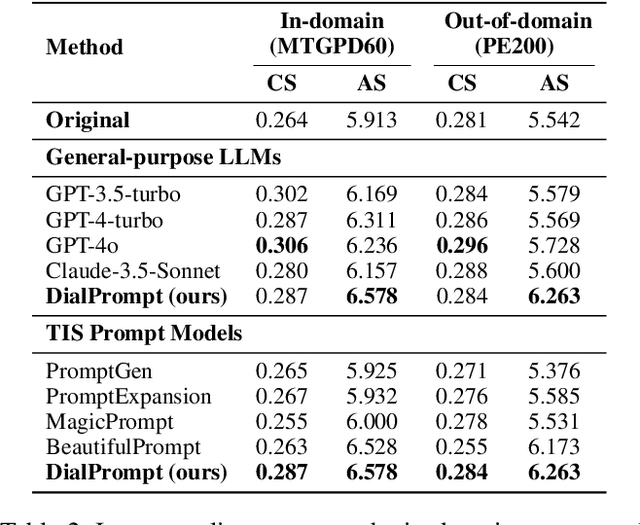
The emergence of text-to-image synthesis (TIS) models has significantly influenced digital image creation by producing high-quality visuals from written descriptions. Yet these models heavily rely on the quality and specificity of textual prompts, posing a challenge for novice users who may not be familiar with TIS-model-preferred prompt writing. Existing solutions relieve this via automatic model-preferred prompt generation from user queries. However, this single-turn manner suffers from limited user-centricity in terms of result interpretability and user interactivity. To address these issues, we propose DialPrompt, a multi-turn dialogue-based TIS prompt generation model that emphasises user-centricity. DialPrompt is designed to follow a multi-turn guidance workflow, where in each round of dialogue the model queries user with their preferences on possible optimization dimensions before generating the final TIS prompt. To achieve this, we mined 15 essential dimensions for high-quality prompts from advanced users and curated a multi-turn dataset. Through training on this dataset, DialPrompt can improve interpretability by allowing users to understand the correlation between specific phrases and image attributes. Additionally, it enables greater user control and engagement in the prompt generation process, leading to more personalized and visually satisfying outputs. Experiments indicate that DialPrompt achieves a competitive result in the quality of synthesized images, outperforming existing prompt engineering approaches by 5.7%. Furthermore, in our user evaluation, DialPrompt outperforms existing approaches by 46.5% in user-centricity score and is rated 7.9/10 by 19 human reviewers.