 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-in-the-Loop Forensics: Agentic Tool Use for Image Forgery Detection
Dec 18, 2025
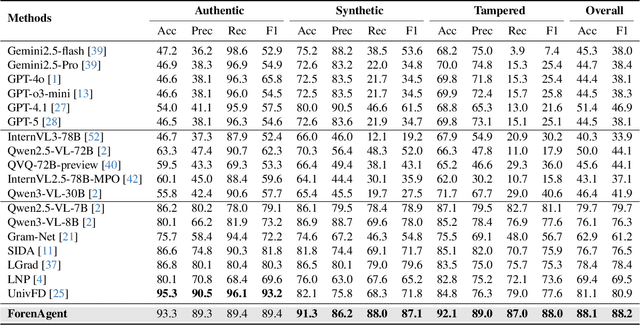
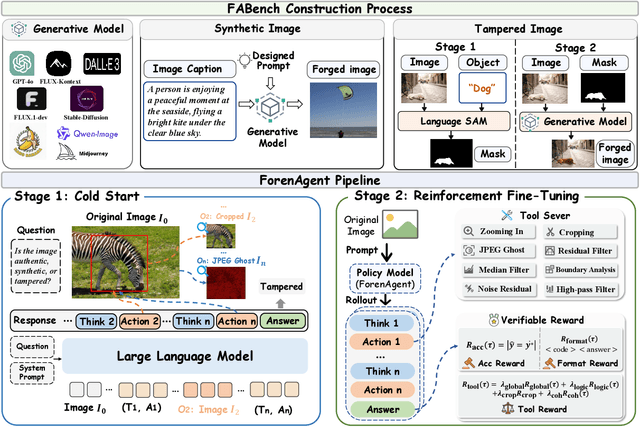
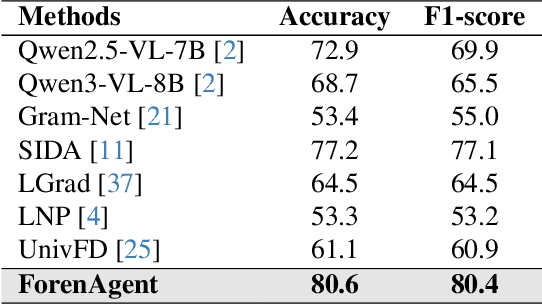
Existing image forgery detection (IFD) methods either exploit low-level, semantics-agnostic artifacts or rely on multimodal large language models (MLLMs) with high-level semantic knowledge. Although naturally complementary, these two information streams are highly heterogeneous in both paradigm and reasoning, making it difficult for existing methods to unify them or effectively model their cross-level interactions. To address this gap, we propose ForenAgent, a multi-round interactive IFD framework that enables MLLMs to autonomously generate, execute, and iteratively refine Python-based low-level tools around the detection objective, thereby achieving more flexible and interpretable forgery analysis. ForenAgent follows a two-stage training pipeline combining Cold Start and Reinforcement Fine-Tuning to enhance its tool interaction capability and reasoning adaptability progressively. Inspired by human reasoning, we design a dynamic reasoning loop comprising global perception, local focusing, iterative probing, and holistic adjudication, and instantiate it as both a data-sampling strategy and a task-aligned process reward. For systematic training and evaluation, we construct FABench, a heterogeneous, high-quality agent-forensics dataset comprising 100k images and approximately 200k agent-interaction question-answer pairs. Experiments show that ForenAgent exhibits emergent tool-use competence and reflective reasoning on challenging IFD tasks when assisted by low-level tools, charting a promising route toward general-purpose IFD. The code will be released after the review process is completed.
A High-Quality Dataset and Reliable Evaluation for Interleaved Image-Text Generation
Jun 11, 2025Recent advancements in Large Multimodal Models (LMMs) have significantly improved multimodal understanding and generation. However, these models still struggle to generate tightly interleaved image-text outputs, primarily due to the limited scale, quality and instructional richness of current training datasets. To address this, we introduce InterSyn, a large-scale multimodal dataset constructed using our Self-Evaluation with Iterative Refinement (SEIR) method. InterSyn features multi-turn, instruction-driven dialogues with tightly interleaved imagetext responses, providing rich object diversity and rigorous automated quality refinement, making it well-suited for training next-generation instruction-following LMMs. Furthermore, to address the lack of reliable evaluation tools capable of assessing interleaved multimodal outputs, we introduce SynJudge, an automatic evaluation model designed to quantitatively assess multimodal outputs along four dimensions: text content, image content, image quality, and image-text synergy. Experimental studies show that the SEIR method leads to substantially higher dataset quality compared to an otherwise identical process without refinement. Moreover, LMMs trained on InterSyn achieve uniform performance gains across all evaluation metrics, confirming InterSyn's utility for advancing multimodal systems.
ARMOR v0.1: Empowering Autoregressive Multimodal Understanding Model with Interleaved Multimodal Generation via Asymmetric Synergy
Mar 09, 2025



Unified models (UniMs) for multimodal understanding and generation have recently received much attention in the area of vision and language. Existing UniMs are designed to simultaneously learn both multimodal understanding and generation capabilities, demanding substantial computational resources, and often struggle to generate interleaved text-image. We present ARMOR, a resource-efficient and pure autoregressive framework that achieves both understanding and generation by fine-tuning existing multimodal large language models (MLLMs). Specifically, ARMOR extends existing MLLMs from three perspectives: (1) For model architecture, an asymmetric encoder-decoder architecture with a forward-switching mechanism is introduced to unify embedding space integrating textual and visual modalities for enabling natural text-image interleaved generation with minimal computational overhead. (2) For training data, a meticulously curated, high-quality interleaved dataset is collected for fine-tuning MLLMs. (3) For the training algorithm, we propose a ``what or how to generate" algorithm to empower existing MLLMs with multimodal generation capabilities while preserving their multimodal understanding capabilities, through three progressive training stages based on the collected dataset. Experimental results demonstrate that ARMOR upgrades existing MLLMs to UniMs with promising image generation capabilities, using limited training resources. Our code will be released soon at https://armor.github.io.