 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Fine-Tuning of Lightweight Domain-Specific Q&A Model Based on Large Language Models
Aug 23, 2024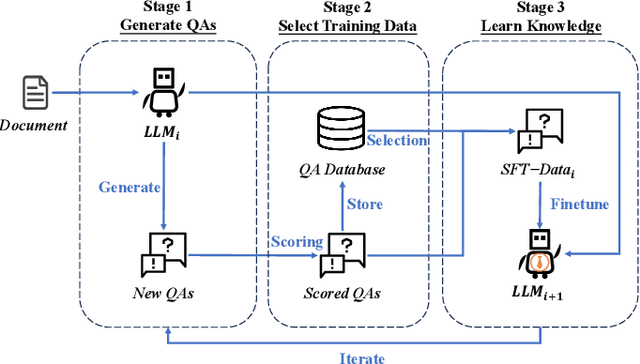
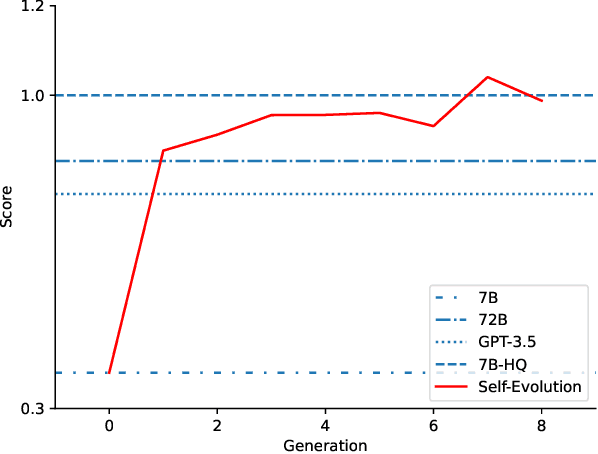
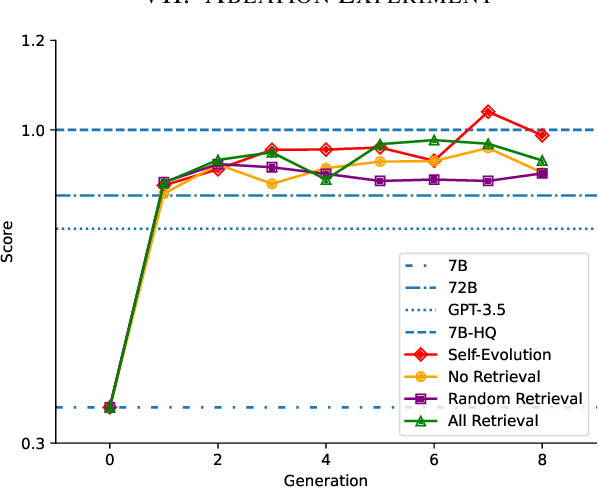

Large language models (LLMs) excel at general question-answering (Q&A) but often fall short in specialized domains due to a lack of domain-specific knowledge. Commercial companies face the dual challenges of privacy protection and resource constraints when involving LLMs for fine-tuning. This paper propose a novel framework, Self-Evolution, designed to address these issues by leveraging lightweight open-source LLMs through multiple iterative fine-tuning rounds. To enhance the efficiency of iterative fine-tuning, Self-Evolution employ a strategy that filters and reinforces the knowledge with higher value during the iterative process. We employed Self-Evolution on Qwen1.5-7B-Chat using 4,000 documents containing rich domain knowledge from China Mobile, achieving a performance score 174% higher on domain-specific question-answering evaluations than Qwen1.5-7B-Chat and even 22% higher than Qwen1.5-72B-Chat. Self-Evolution has been deployed in China Mobile's daily operation and maintenance for 117 days, and it improves the efficiency of locating alarms, fixing problems, and finding related reports, with an average efficiency improvement of over 18.6%. In addition, we release Self-Evolution framework code in https://github.com/Zero-Pointer/Self-Evolution.
GenAD: General Representations of Multivariate Time Seriesfor Anomaly Detection
Feb 09, 2022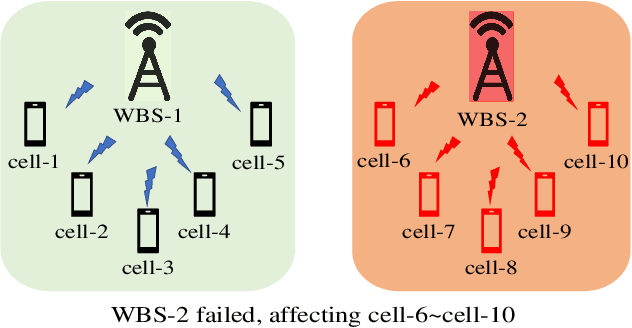
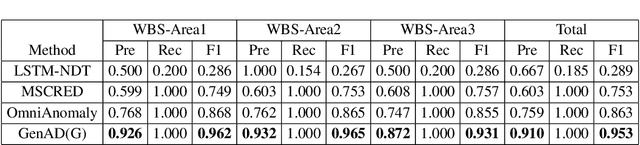
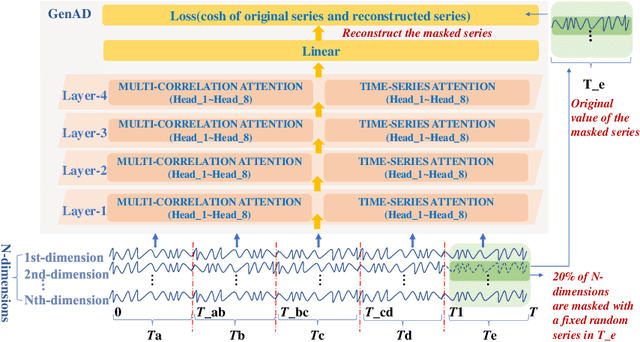

The reliability of wireless base stations in China Mobile is of vital importance, because the cell phone users are connected to the stations and the behaviors of the stations are directly related to user experience. Although the monitoring of the station behaviors can be realized by anomaly detection on multivariate time series, due to complex correlations and various temporal patterns of multivariate series in large-scale stations, building a general unsupervised anomaly detection model with a higher F1-score remains a challenging task. In this paper, we propose a General representation of multivariate time series for Anomaly Detection(GenAD). First, we pre-train a general model on large-scale wireless base stations with self-supervision, which can be easily transferred to a specific station anomaly detection with a small amount of training data. Second, we employ Multi-Correlation Attention and Time-Series Attention to represent the correlations and temporal patterns of the stations. With the above innovations, GenAD increases F1-score by total 9% on real-world datasets in China Mobile, while the performance does not significantly degrade on public datasets with only 10% of the training data.