 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for End-to-End Zero-Shot Biomedical Relation Extraction with LLMs: Experiments with OpenAI Models
Apr 05, 2025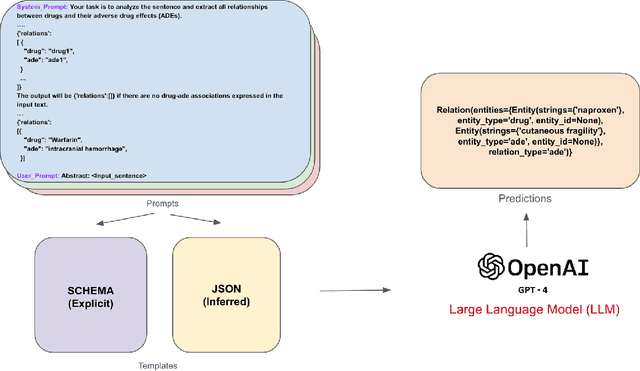
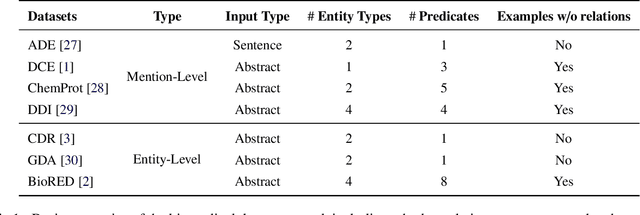
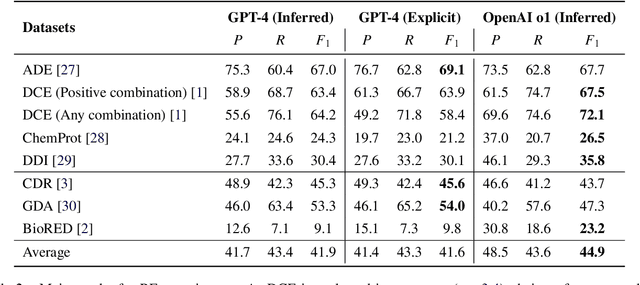
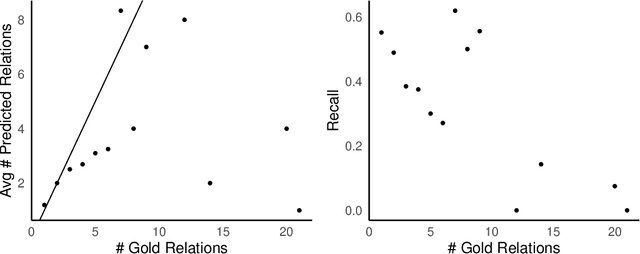
Objective: Zero-shot methodology promises to cut down on costs of dataset annotation and domain expertise needed to make use of NLP. Generative large language models trained to align with human goals have achieved high zero-shot performance across a wide variety of tasks. As of yet, it is unclear how well these models perform on biomedical relation extraction (RE). To address this knowledge gap, we explore patterns in the performance of OpenAI LLMs across a diverse sampling of RE tasks. Methods: We use OpenAI GPT-4-turbo and their reasoning model o1 to conduct end-to-end RE experiments on seven datasets. We use the JSON generation capabilities of GPT models to generate structured output in two ways: (1) by defining an explicit schema describing the structure of relations, and (2) using a setting that infers the structure from the prompt language. Results: Our work is the first to study and compare the performance of the GPT-4 and o1 for the end-to-end zero-shot biomedical RE task across a broad array of datasets. We found the zero-shot performances to be proximal to that of fine-tuned methods. The limitations of this approach are that it performs poorly on instances containing many relations and errs on the boundaries of textual mentions. Conclusion: Recent large language models exhibit promising zero-shot capabilities in complex biomedical RE tasks, offering competitive performance with reduced dataset curation and NLP modeling needs at the cost of increased computing, potentially increasing medical community accessibility. Addressing the limitations we identify could further boost reliability. The code, data, and prompts for all our experiments are publicly available: https://github.com/bionlproc/ZeroShotRE
How Important is Domain Specificity in Language Models and Instruction Finetuning for Biomedical Relation Extraction?
Feb 21, 2024Cutting edge techniques developed in the general NLP domain are often subsequently applied to the high-value, data-rich biomedical domain. The past few years have seen generative language models (LMs), instruction finetuning, and few-shot learning become foci of NLP research. As such, generative LMs pretrained on biomedical corpora have proliferated and biomedical instruction finetuning has been attempted as well, all with the hope that domain specificity improves performance on downstream tasks. Given the nontrivial effort in training such models, we investigate what, if any, benefits they have in the key biomedical NLP task of relation extraction. Specifically, we address two questions: (1) Do LMs trained on biomedical corpora outperform those trained on general domain corpora? (2) Do models instruction finetuned on biomedical datasets outperform those finetuned on assorted datasets or those simply pretrained? We tackle these questions using existing LMs, testing across four datasets. In a surprising result, general-domain models typically outperformed biomedical-domain models. However, biomedical instruction finetuning improved performance to a similar degree as general instruction finetuning, despite having orders of magnitude fewer instructions. Our findings suggest it may be more fruitful to focus research effort on larger-scale biomedical instruction finetuning of general LMs over building domain-specific biomedical LMs