 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents
Jul 26, 2024



Autonomous agents that address day-to-day digital tasks (e.g., ordering groceries for a household), must not only operate multiple apps (e.g., notes, messaging, shopping app) via APIs, but also generate rich code with complex control flow in an iterative manner based on their interaction with the environment. However, existing benchmarks for tool use are inadequate, as they only cover tasks that require a simple sequence of API calls. To remedy this gap, we built $\textbf{AppWorld Engine}$, a high-quality execution environment (60K lines of code) of 9 day-to-day apps operable via 457 APIs and populated with realistic digital activities simulating the lives of ~100 fictitious users. We then created $\textbf{AppWorld Benchmark}$ (40K lines of code), a suite of 750 natural, diverse, and challenging autonomous agent tasks requiring rich and interactive code generation. It supports robust programmatic evaluation with state-based unit tests, allowing for different ways of completing a task while also checking for unexpected changes, i.e., collateral damage. The state-of-the-art LLM, GPT-4o, solves only ~49% of our 'normal' tasks and ~30% of 'challenge' tasks, while other models solve at least 16% fewer. This highlights the benchmark's difficulty and AppWorld's potential to push the frontiers of interactive coding agents. The project website is available at https://appworld.dev/.
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
Dec 20, 2022



Recent work has shown that large language models are capable of generating natural language reasoning steps or Chains-of-Thoughts (CoT) to answer a multi-step question when prompted to do so. This is insufficient, however, when the necessary knowledge is not available or up-to-date within a model's parameters. A straightforward approach to address this is to retrieve text from an external knowledge source using the question as a query and prepend it as context to the model's input. This, however, is also insufficient for multi-step QA where \textit{what to retrieve} depends on \textit{what has already been derived}. To address this issue we propose IRCoT, a new approach that interleaves retrieval with CoT for multi-step QA, guiding the retrieval with CoT and in turn using retrieved results to improve CoT. Our experiments with GPT3 show substantial improvements in retrieval (up to 22 points) and downstream QA (up to 16 points) over the baselines on four datasets: HotpotQA, 2WikiMultihopQA, MuSiQue, and IIRC. Notably, our method also works well for much smaller models such as T5-Flan-large (0.7B) without any additional training.
Two-Turn Debate Doesn't Help Humans Answer Hard Reading Comprehension Questions
Oct 19, 2022
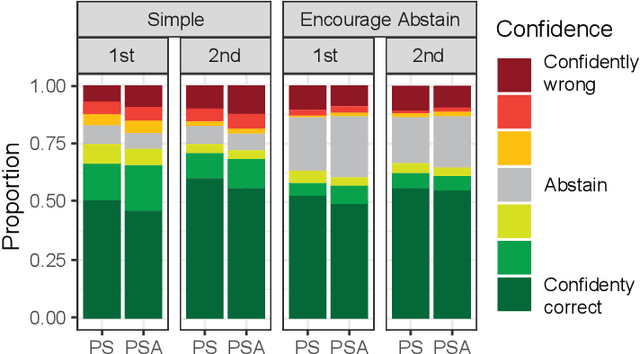
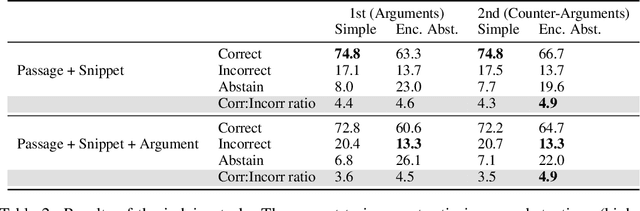
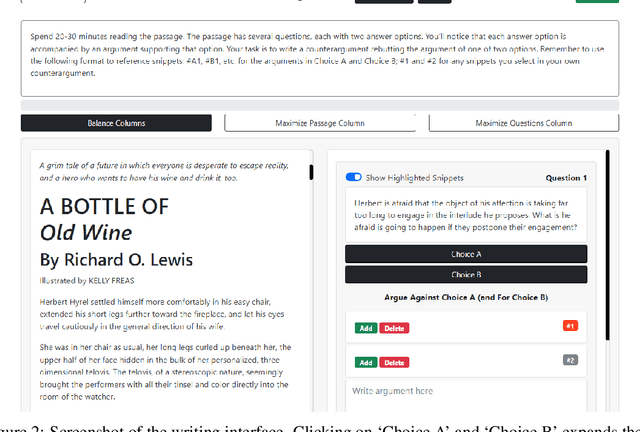
The use of language-model-based question-answering systems to aid humans in completing difficult tasks is limited, in part, by the unreliability of the text these systems generate. Using hard multiple-choice reading comprehension questions as a testbed, we assess whether presenting humans with arguments for two competing answer options, where one is correct and the other is incorrect, allows human judges to perform more accurately, even when one of the arguments is unreliable and deceptive. If this is helpful, we may be able to increase our justified trust in language-model-based systems by asking them to produce these arguments where needed. Previous research has shown that just a single turn of arguments in this format is not helpful to humans. However, as debate settings are characterized by a back-and-forth dialogue, we follow up on previous results to test whether adding a second round of counter-arguments is helpful to humans. We find that, regardless of whether they have access to arguments or not, humans perform similarly on our task. These findings suggest that, in the case of answering reading comprehension questions, debate is not a helpful format.
Decomposed Prompting: A Modular Approach for Solving Complex Tasks
Oct 05, 2022

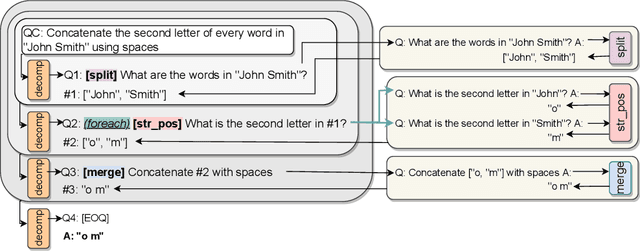

Few-shot prompting is a surprisingly powerful way to use Large Language Models (LLMs) to solve various tasks. However, this approach struggles as the task complexity increases or when the individual reasoning steps of the task themselves are hard to learn, especially when embedded in more complex tasks. To address this, we propose Decomposed Prompting, a new approach to solve complex tasks by decomposing them (via prompting) into simpler sub-tasks that can be delegated to a library of prompting-based LLMs dedicated to these sub-tasks. This modular structure allows each prompt to be optimized for its specific sub-task, further decomposed if necessary, and even easily replaced with more effective prompts, trained models, or symbolic functions if desired. We show that the flexibility and modularity of Decomposed Prompting allows it to outperform prior work on few-shot prompting using GPT3. On symbolic reasoning tasks, we can further decompose sub-tasks that are hard for LLMs into even simpler solvable sub-tasks. When the complexity comes from the input length, we can recursively decompose the task into the same task but with smaller inputs. We also evaluate our approach on textual multi-step reasoning tasks: on long-context multi-hop QA task, we can more effectively teach the sub-tasks via our separate sub-tasks prompts; and on open-domain multi-hop QA, we can incorporate a symbolic information retrieval within our decomposition framework, leading to improved performance on both tasks.
Teaching Broad Reasoning Skills via Decomposition-Guided Contexts
May 25, 2022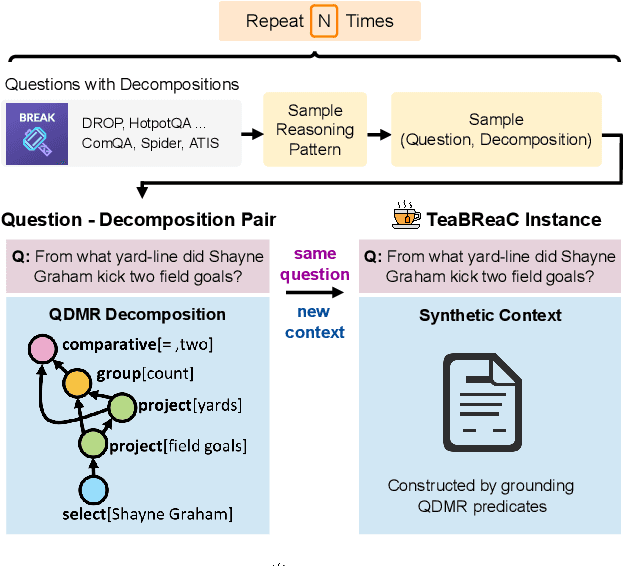
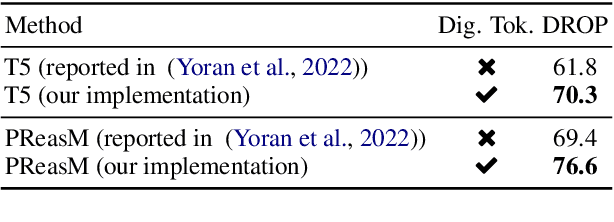
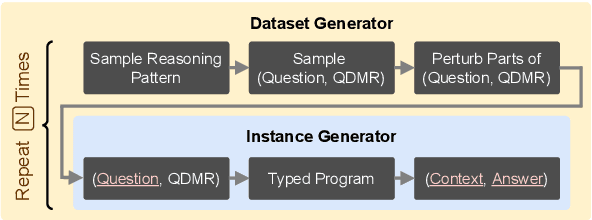

Question-answering datasets require a broad set of reasoning skills. We show how to use question decompositions to teach language models these broad reasoning skills in a robust fashion. Specifically, we use widely available QDMR representations to programmatically create synthetic contexts for real questions in six multihop reasoning datasets. These contexts are carefully designed to avoid common reasoning shortcuts prevalent in real contexts that prevent models from learning the right skills. This results in a pretraining dataset, named TeaBReaC, containing 525K multihop questions (with associated formal programs) covering about 900 reasoning patterns. We show that pretraining standard language models (LMs) on TeaBReaC before fine-tuning them on target datasets improves their performance by up to 13 EM points across 3 multihop QA datasets, with a 30 point gain on more complex questions. The resulting models also demonstrate higher robustness, with a 6-11 point improvement on two contrast sets. Furthermore, TeaBReaC pretraining substantially improves model performance and robustness even when starting with numeracy-aware LMs pretrained using recent methods (e.g., PReasM). Our work thus shows how one can effectively use decomposition-guided contexts to robustly teach multihop reasoning.
Single-Turn Debate Does Not Help Humans Answer Hard Reading-Comprehension Questions
Apr 13, 2022
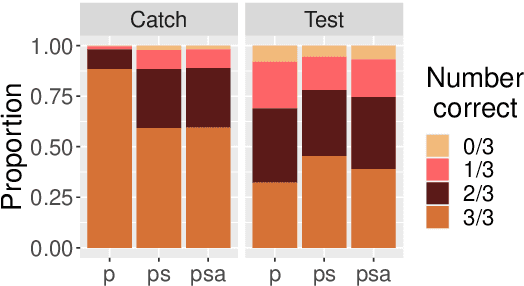

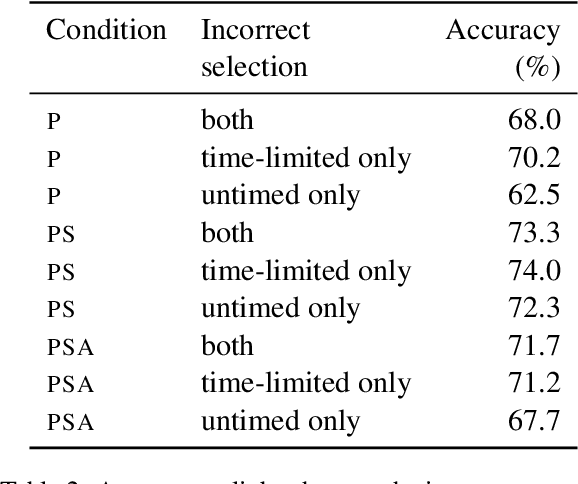
Current QA systems can generate reasonable-sounding yet false answers without explanation or evidence for the generated answer, which is especially problematic when humans cannot readily check the model's answers. This presents a challenge for building trust in machine learning systems. We take inspiration from real-world situations where difficult questions are answered by considering opposing sides (see Irving et al., 2018). For multiple-choice QA examples, we build a dataset of single arguments for both a correct and incorrect answer option in a debate-style set-up as an initial step in training models to produce explanations for two candidate answers. We use long contexts -- humans familiar with the context write convincing explanations for pre-selected correct and incorrect answers, and we test if those explanations allow humans who have not read the full context to more accurately determine the correct answer. We do not find that explanations in our set-up improve human accuracy, but a baseline condition shows that providing human-selected text snippets does improve accuracy. We use these findings to suggest ways of improving the debate set up for future data collection efforts.
Summarize-then-Answer: Generating Concise Explanations for Multi-hop Reading Comprehension
Sep 14, 2021
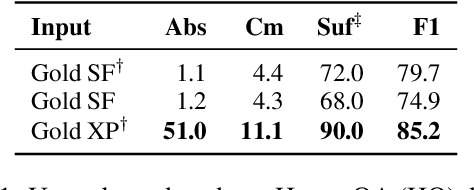
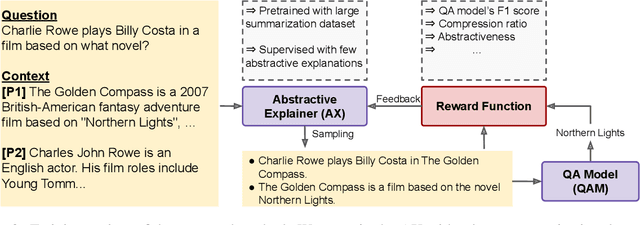
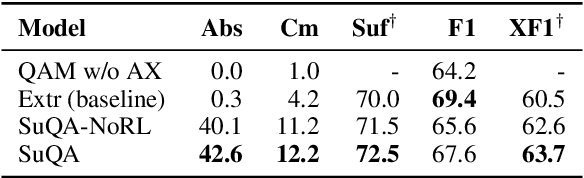
How can we generate concise explanations for multi-hop Reading Comprehension (RC)? The current strategies of identifying supporting sentences can be seen as an extractive question-focused summarization of the input text. However, these extractive explanations are not necessarily concise i.e. not minimally sufficient for answering a question. Instead, we advocate for an abstractive approach, where we propose to generate a question-focused, abstractive summary of input paragraphs and then feed it to an RC system. Given a limited amount of human-annotated abstractive explanations, we train the abstractive explainer in a semi-supervised manner, where we start from the supervised model and then train it further through trial and error maximizing a conciseness-promoted reward function. Our experiments demonstrate that the proposed abstractive explainer can generate more compact explanations than an extractive explainer with limited supervision (only 2k instances) while maintaining sufficiency.
MuSiQue: Multi-hop Questions via Single-hop Question Composition
Aug 02, 2021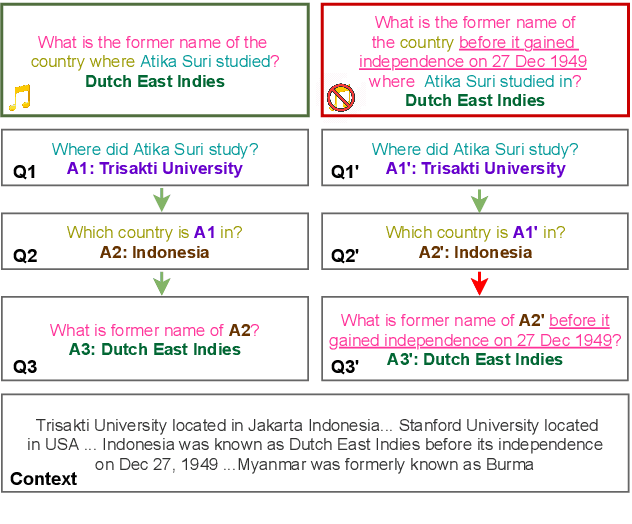
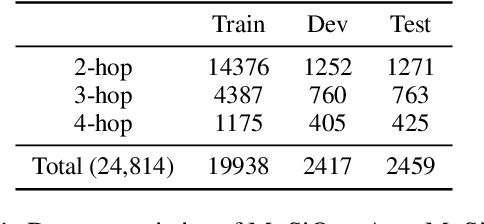
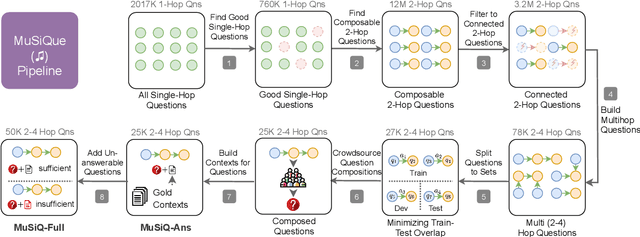
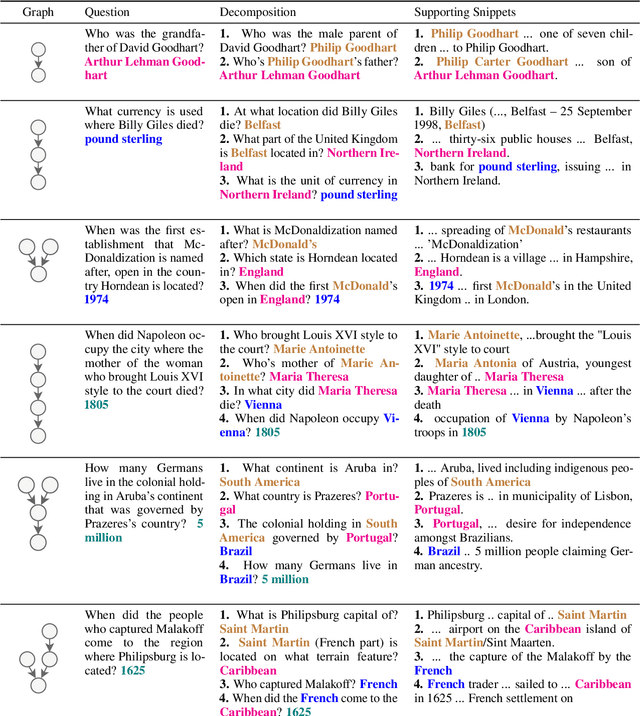
To build challenging multi-hop question answering datasets, we propose a bottom-up semi-automatic process of constructing multi-hop question via composition of single-hop questions. Constructing multi-hop questions as composition of single-hop questions allows us to exercise greater control over the quality of the resulting multi-hop questions. This process allows building a dataset with (i) connected reasoning where each step needs the answer from a previous step; (ii) minimal train-test leakage by eliminating even partial overlap of reasoning steps; (iii) variable number of hops and composition structures; and (iv) contrasting unanswerable questions by modifying the context. We use this process to construct a new multihop QA dataset: MuSiQue-Ans with ~25K 2-4 hop questions using seed questions from 5 existing single-hop datasets. Our experiments demonstrate that MuSique is challenging for state-of-the-art QA models (e.g., human-machine gap of $~$30 F1 pts), significantly harder than existing datasets (2x human-machine gap), and substantially less cheatable (e.g., a single-hop model is worse by 30 F1 pts). We also build an even more challenging dataset, MuSiQue-Full, consisting of answerable and unanswerable contrast question pairs, where model performance drops further by 13+ F1 pts. For data and code, see \url{https://github.com/stonybrooknlp/musique}.