 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Turn Debate Doesn't Help Humans Answer Hard Reading Comprehension Questions
Paper and Code
Oct 19, 2022
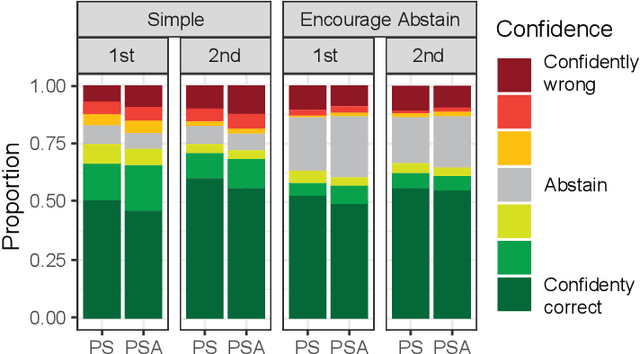
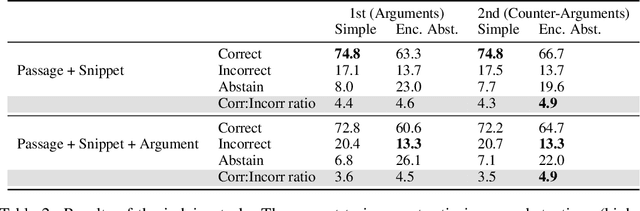
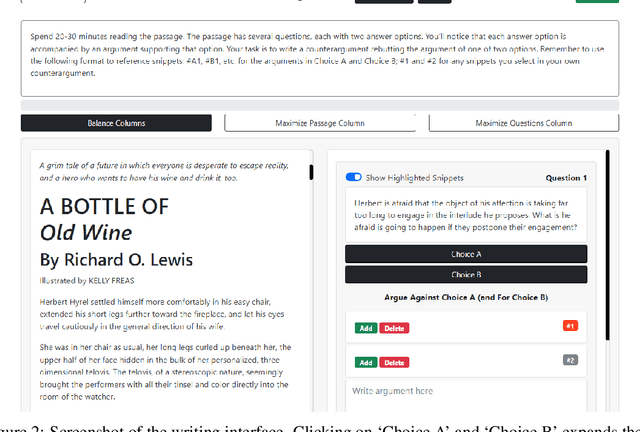
The use of language-model-based question-answering systems to aid humans in completing difficult tasks is limited, in part, by the unreliability of the text these systems generate. Using hard multiple-choice reading comprehension questions as a testbed, we assess whether presenting humans with arguments for two competing answer options, where one is correct and the other is incorrect, allows human judges to perform more accurately, even when one of the arguments is unreliable and deceptive. If this is helpful, we may be able to increase our justified trust in language-model-based systems by asking them to produce these arguments where needed. Previous research has shown that just a single turn of arguments in this format is not helpful to humans. However, as debate settings are characterized by a back-and-forth dialogue, we follow up on previous results to test whether adding a second round of counter-arguments is helpful to humans. We find that, regardless of whether they have access to arguments or not, humans perform similarly on our task. These findings suggest that, in the case of answering reading comprehension questions, debate is not a helpful format.