 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Ingredients Make for an Effective Crowdsourcing Protocol for Difficult NLU Data Collection Tasks?
Paper and Code
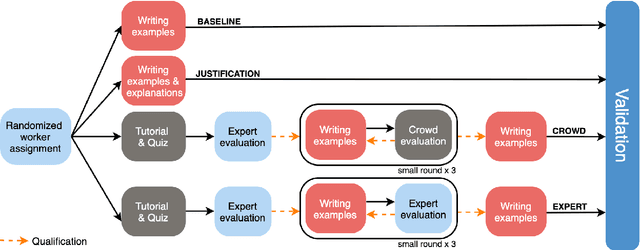
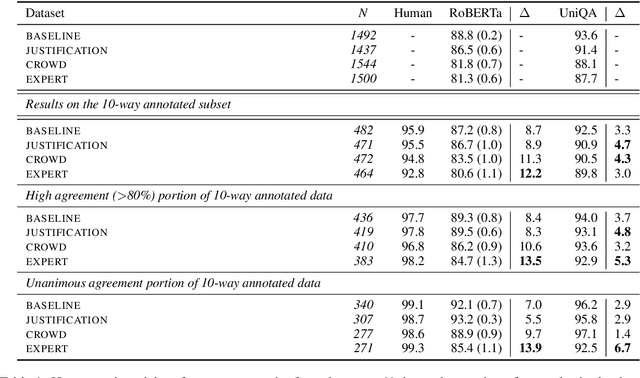


Crowdsourcing is widely used to create data for common natural language understanding tasks. Despite the importance of these datasets for measuring and refining model understanding of language, there has been little focus on the crowdsourcing methods used for collecting the datasets. In this paper, we compare the efficacy of interventions that have been proposed in prior work as ways of improving data quality. We use multiple-choice question answering as a testbed and run a randomized trial by assigning crowdworkers to write questions under one of four different data collection protocols. We find that asking workers to write explanations for their examples is an ineffective stand-alone strategy for boosting NLU example difficulty. However, we find that training crowdworkers, and then using an iterative process of collecting data, sending feedback, and qualifying workers based on expert judgments is an effective means of collecting challenging data. But using crowdsourced, instead of expert judgments, to qualify workers and send feedback does not prove to be effective. We observe that the data from the iterative protocol with expert assessments is more challenging by several measures. Notably, the human--model gap on the unanimous agreement portion of this data is, on average, twice as large as the gap for the baseline protocol data.