 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Cover Selection for Image Steganography
Oct 23, 2024
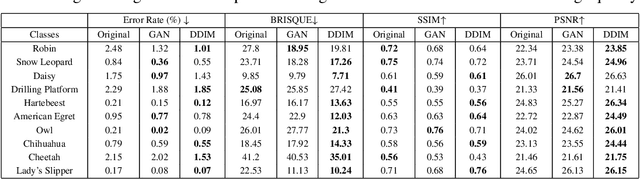
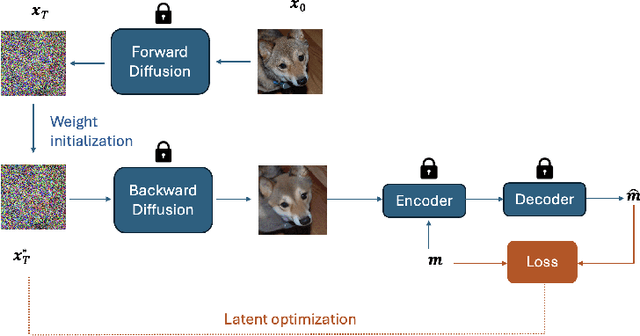
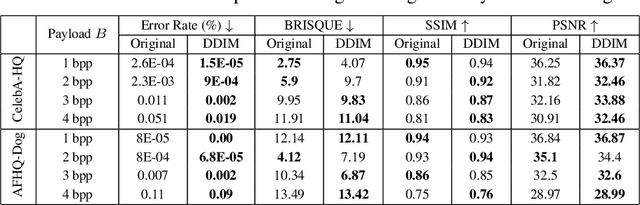
In steganography, selecting an optimal cover image, referred to as cover selection, is pivotal for effective message concealment. Traditional methods have typically employed exhaustive searches to identify images that conform to specific perceptual or complexity metrics. However, the relationship between these metrics and the actual message hiding efficacy of an image is unclear, often yielding less-than-ideal steganographic outcomes. Inspired by recent advancements in generative models, we introduce a novel cover selection framework, which involves optimizing within the latent space of pretrained generative models to identify the most suitable cover images, distinguishing itself from traditional exhaustive search methods. Our method shows significant advantages in message recovery and image quality. We also conduct an information-theoretic analysis of the generated cover images, revealing that message hiding predominantly occurs in low-variance pixels, reflecting the waterfilling algorithm's principles in parallel Gaussian channels. Our code can be found at: https://github.com/karlchahine/Neural-Cover-Selection-for-Image-Steganography.
Exploring Explainability in Video Action Recognition
Apr 13, 2024



Image Classification and Video Action Recognition are perhaps the two most foundational tasks in computer vision. Consequently, explaining the inner workings of trained deep neural networks is of prime importance. While numerous efforts focus on explaining the decisions of trained deep neural networks in image classification, exploration in the domain of its temporal version, video action recognition, has been scant. In this work, we take a deeper look at this problem. We begin by revisiting Grad-CAM, one of the popular feature attribution methods for Image Classification, and its extension to Video Action Recognition tasks and examine the method's limitations. To address these, we introduce Video-TCAV, by building on TCAV for Image Classification tasks, which aims to quantify the importance of specific concepts in the decision-making process of Video Action Recognition models. As the scalable generation of concepts is still an open problem, we propose a machine-assisted approach to generate spatial and spatiotemporal concepts relevant to Video Action Recognition for testing Video-TCAV. We then establish the importance of temporally-varying concepts by demonstrating the superiority of dynamic spatiotemporal concepts over trivial spatial concepts. In conclusion, we introduce a framework for investigating hypotheses in action recognition and quantitatively testing them, thus advancing research in the explainability of deep neural networks used in video action recognition.
Turbo Autoencoder with a Trainable Interleaver
Nov 22, 2021
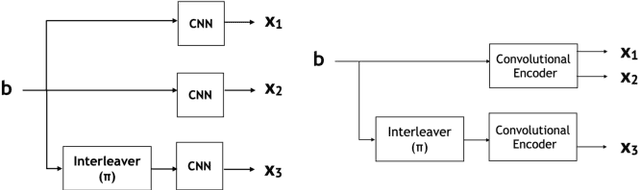
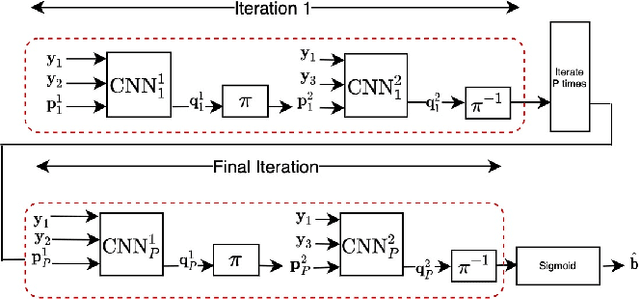
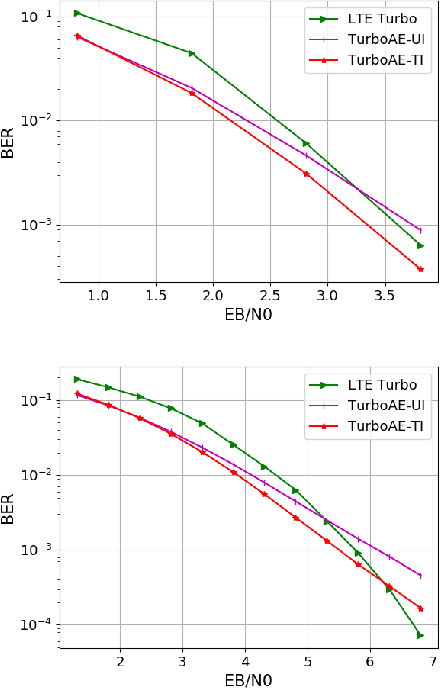
A critical aspect of reliable communication involves the design of codes that allow transmissions to be robustly and computationally efficiently decoded under noisy conditions. Advances in the design of reliable codes have been driven by coding theory and have been sporadic. Recently, it is shown that channel codes that are comparable to modern codes can be learned solely via deep learning. In particular, Turbo Autoencoder (TURBOAE), introduced by Jiang et al., is shown to achieve the reliability of Turbo codes for Additive White Gaussian Noise channels. In this paper, we focus on applying the idea of TURBOAE to various practical channels, such as fading channels and chirp noise channels. We introduce TURBOAE-TI, a novel neural architecture that combines TURBOAE with a trainable interleaver design. We develop a carefully-designed training procedure and a novel interleaver penalty function that are crucial in learning the interleaver and TURBOAE jointly. We demonstrate that TURBOAE-TI outperforms TURBOAE and LTE Turbo codes for several channels of interest. We also provide interpretation analysis to better understand TURBOAE-TI.
DeepIC: Coding for Interference Channels via Deep Learning
Aug 13, 2021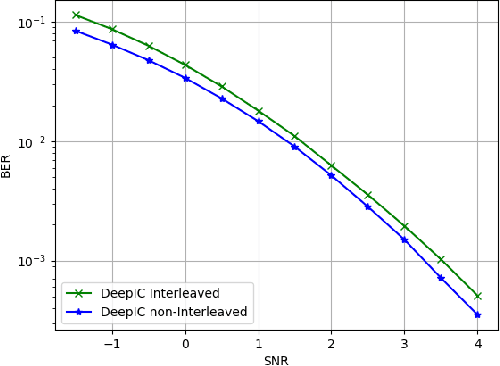
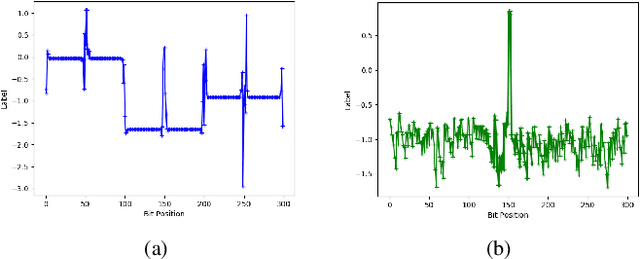
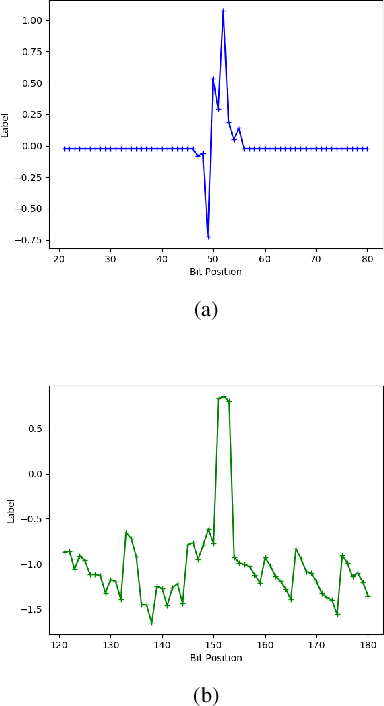
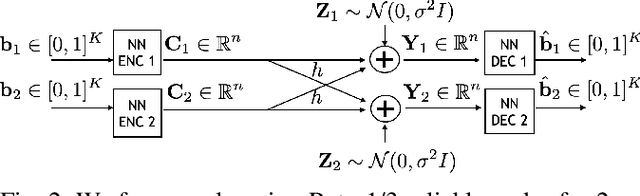
The two-user interference channel is a model for multi one-to-one communications, where two transmitters wish to communicate with their corresponding receivers via a shared wireless medium. Two most common and simple coding schemes are time division (TD) and treating interference as noise (TIN). Interestingly, it is shown that there exists an asymptotic scheme, called Han-Kobayashi scheme, that performs better than TD and TIN. However, Han-Kobayashi scheme has impractically high complexity and is designed for asymptotic settings, which leads to a gap between information theory and practice. In this paper, we focus on designing practical codes for interference channels. As it is challenging to analytically design practical codes with feasible complexity, we apply deep learning to learn codes for interference channels. We demonstrate that DeepIC, a convolutional neural network-based code with an iterative decoder, outperforms TD and TIN by a significant margin for two-user additive white Gaussian noise channels with moderate amount of interference.