 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouter-Suggest: Dynamic Routing for Multimodal Auto-Completion in Visually-Grounded Dialogs
Jan 09, 2026Real-time multimodal auto-completion is essential for digital assistants, chatbots, design tools, and healthcare consultations, where user inputs rely on shared visual context. We introduce Multimodal Auto-Completion (MAC), a task that predicts upcoming characters in live chats using partially typed text and visual cues. Unlike traditional text-only auto-completion (TAC), MAC grounds predictions in multimodal context to better capture user intent. To enable this task, we adapt MMDialog and ImageChat to create benchmark datasets. We evaluate leading vision-language models (VLMs) against strong textual baselines, highlighting trade-offs in accuracy and efficiency. We present Router-Suggest, a router framework that dynamically selects between textual models and VLMs based on dialog context, along with a lightweight variant for resource-constrained environments. Router-Suggest achieves a 2.3x to 10x speedup over the best-performing VLM. A user study shows that VLMs significantly excel over textual models on user satisfaction, notably saving user typing effort and improving the quality of completions in multi-turn conversations. These findings underscore the need for multimodal context in auto-completions, leading to smarter, user-aware assistants.
Pro-Pose: Unpaired Full-Body Portrait Synthesis via Canonical UV Maps
Dec 19, 2025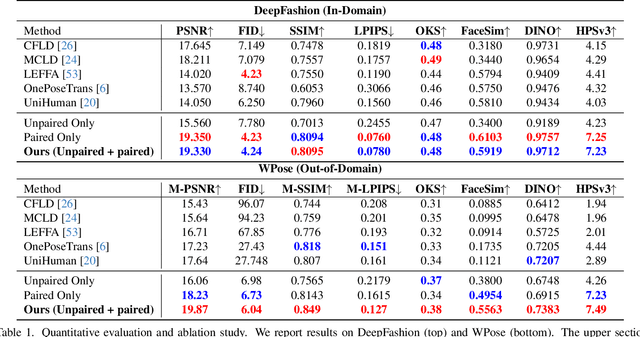
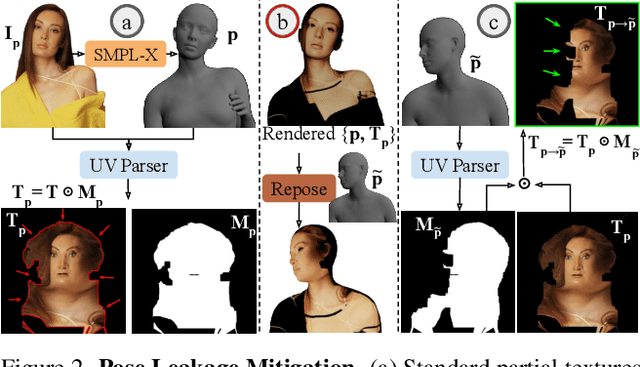
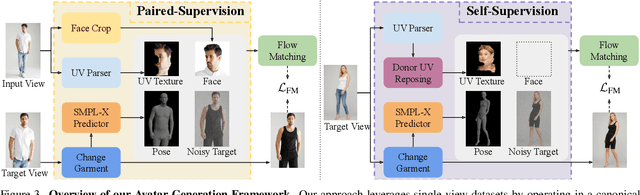

Photographs of people taken by professional photographers typically present the person in beautiful lighting, with an interesting pose, and flattering quality. This is unlike common photos people can take of themselves. In this paper, we explore how to create a ``professional'' version of a person's photograph, i.e., in a chosen pose, in a simple environment, with good lighting, and standard black top/bottom clothing. A key challenge is to preserve the person's unique identity, face and body features while transforming the photo. If there would exist a large paired dataset of the same person photographed both ``in the wild'' and by a professional photographer, the problem would potentially be easier to solve. However, such data does not exist, especially for a large variety of identities. To that end, we propose two key insights: 1) Our method transforms the input photo and person's face to a canonical UV space, which is further coupled with reposing methodology to model occlusions and novel view synthesis. Operating in UV space allows us to leverage existing unpaired datasets. 2) We personalize the output photo via multi image finetuning. Our approach yields high-quality, reposed portraits and achieves strong qualitative and quantitative performance on real-world imagery.
YouDream: Generating Anatomically Controllable Consistent Text-to-3D Animals
Jun 24, 2024

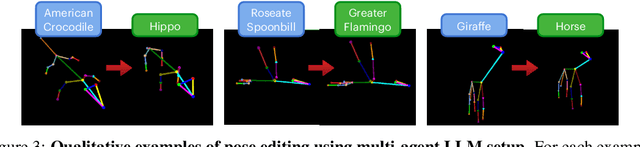

3D generation guided by text-to-image diffusion models enables the creation of visually compelling assets. However previous methods explore generation based on image or text. The boundaries of creativity are limited by what can be expressed through words or the images that can be sourced. We present YouDream, a method to generate high-quality anatomically controllable animals. YouDream is guided using a text-to-image diffusion model controlled by 2D views of a 3D pose prior. Our method generates 3D animals that are not possible to create using previous text-to-3D generative methods. Additionally, our method is capable of preserving anatomic consistency in the generated animals, an area where prior text-to-3D approaches often struggle. Moreover, we design a fully automated pipeline for generating commonly found animals. To circumvent the need for human intervention to create a 3D pose, we propose a multi-agent LLM that adapts poses from a limited library of animal 3D poses to represent the desired animal. A user study conducted on the outcomes of YouDream demonstrates the preference of the animal models generated by our method over others. Turntable results and code are released at https://youdream3d.github.io/
C3DAG: Controlled 3D Animal Generation using 3D pose guidance
Jun 11, 2024


Recent advancements in text-to-3D generation have demonstrated the ability to generate high quality 3D assets. However while generating animals these methods underperform, often portraying inaccurate anatomy and geometry. Towards ameliorating this defect, we present C3DAG, a novel pose-Controlled text-to-3D Animal Generation framework which generates a high quality 3D animal consistent with a given pose. We also introduce an automatic 3D shape creator tool, that allows dynamic pose generation and modification via a web-based tool, and that generates a 3D balloon animal using simple geometries. A NeRF is then initialized using this 3D shape using depth-controlled SDS. In the next stage, the pre-trained NeRF is fine-tuned using quadruped-pose-controlled SDS. The pipeline that we have developed not only produces geometrically and anatomically consistent results, but also renders highly controlled 3D animals, unlike prior methods which do not allow fine-grained pose control.
Subjective and Objective Analysis of Indian Social Media Video Quality
Jan 05, 2024
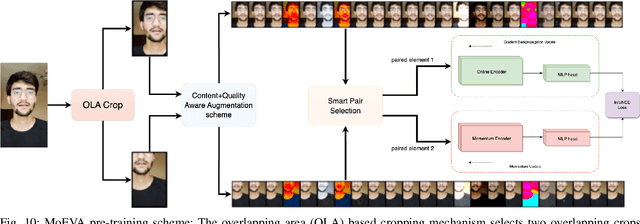
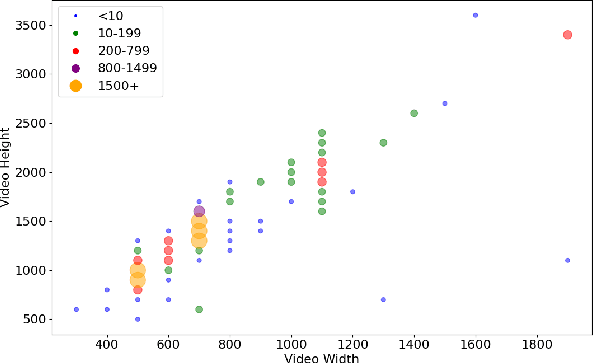
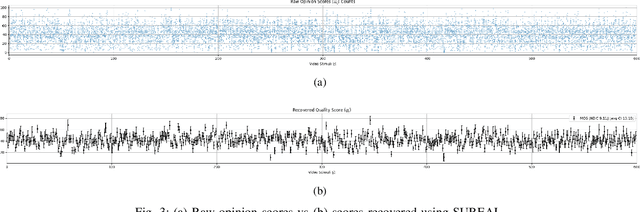
We conducted a large-scale subjective study of the perceptual quality of User-Generated Mobile Video Content on a set of mobile-originated videos obtained from the Indian social media platform ShareChat. The content viewed by volunteer human subjects under controlled laboratory conditions has the benefit of culturally diversifying the existing corpus of User-Generated Content (UGC) video quality datasets. There is a great need for large and diverse UGC-VQA datasets, given the explosive global growth of the visual internet and social media platforms. This is particularly true in regard to videos obtained by smartphones, especially in rapidly emerging economies like India. ShareChat provides a safe and cultural community oriented space for users to generate and share content in their preferred Indian languages and dialects. Our subjective quality study, which is based on this data, offers a boost of cultural, visual, and language diversification to the video quality research community. We expect that this new data resource will also allow for the development of systems that can predict the perceived visual quality of Indian social media videos, to control scaling and compression protocols for streaming, provide better user recommendations, and guide content analysis and processing. We demonstrate the value of the new data resource by conducting a study of leading blind video quality models on it, including a new model, called MoEVA, which deploys a mixture of experts to predict video quality. Both the new LIVE-ShareChat dataset and sample source code for MoEVA are being made freely available to the research community at https://github.com/sandeep-sm/LIVE-SC
Re-IQA: Unsupervised Learning for Image Quality Assessment in the Wild
Apr 02, 2023



Automatic Perceptual Image Quality Assessment is a challenging problem that impacts billions of internet, and social media users daily. To advance research in this field, we propose a Mixture of Experts approach to train two separate encoders to learn high-level content and low-level image quality features in an unsupervised setting. The unique novelty of our approach is its ability to generate low-level representations of image quality that are complementary to high-level features representing image content. We refer to the framework used to train the two encoders as Re-IQA. For Image Quality Assessment in the Wild, we deploy the complementary low and high-level image representations obtained from the Re-IQA framework to train a linear regression model, which is used to map the image representations to the ground truth quality scores, refer Figure 1. Our method achieves state-of-the-art performance on multiple large-scale image quality assessment databases containing both real and synthetic distortions, demonstrating how deep neural networks can be trained in an unsupervised setting to produce perceptually relevant representations. We conclude from our experiments that the low and high-level features obtained are indeed complementary and positively impact the performance of the linear regressor. A public release of all the codes associated with this work will be made available on GitHub.
RecSal : Deep Recursive Supervision for Visual Saliency Prediction
Aug 31, 2020

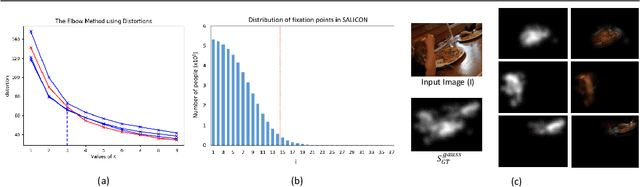
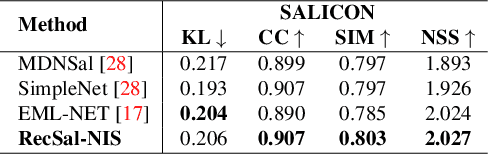
State-of-the-art saliency prediction methods develop upon model architectures or loss functions; while training to generate one target saliency map. However, publicly available saliency prediction datasets can be utilized to create more information for each stimulus than just a final aggregate saliency map. This information when utilized in a biologically inspired fashion can contribute in better prediction performance without the use of models with huge number of parameters. In this light, we propose to extract and use the statistics of (a) region specific saliency and (b) temporal order of fixations, to provide additional context to our network. We show that extra supervision using spatially or temporally sequenced fixations results in achieving better performance in saliency prediction. Further, we also design novel architectures for utilizing this extra information and show that it achieves superior performance over a base model which is devoid of extra supervision. We show that our best method outperforms previous state-of-the-art methods with 50-80% fewer parameters. We also show that our models perform consistently well across all evaluation metrics unlike prior methods.