 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubjective and Objective Analysis of Indian Social Media Video Quality
Paper and Code

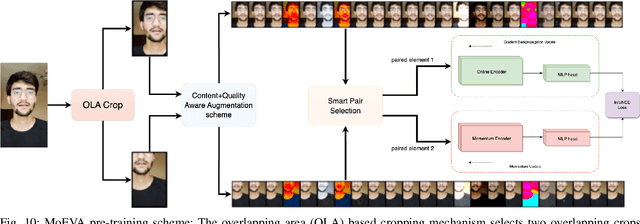
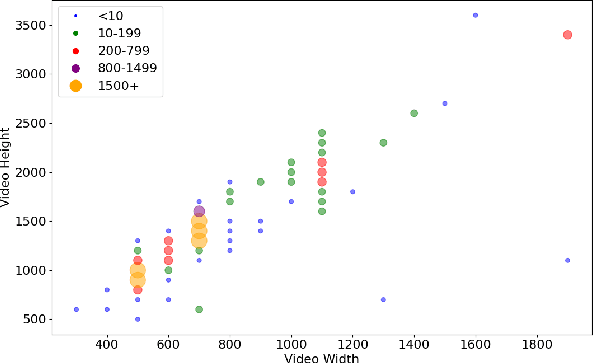
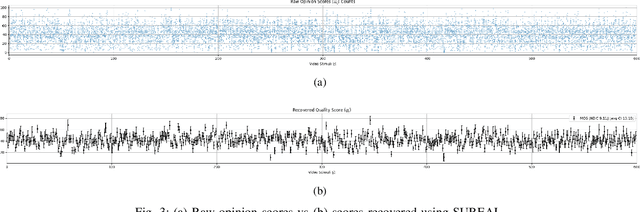
We conducted a large-scale subjective study of the perceptual quality of User-Generated Mobile Video Content on a set of mobile-originated videos obtained from the Indian social media platform ShareChat. The content viewed by volunteer human subjects under controlled laboratory conditions has the benefit of culturally diversifying the existing corpus of User-Generated Content (UGC) video quality datasets. There is a great need for large and diverse UGC-VQA datasets, given the explosive global growth of the visual internet and social media platforms. This is particularly true in regard to videos obtained by smartphones, especially in rapidly emerging economies like India. ShareChat provides a safe and cultural community oriented space for users to generate and share content in their preferred Indian languages and dialects. Our subjective quality study, which is based on this data, offers a boost of cultural, visual, and language diversification to the video quality research community. We expect that this new data resource will also allow for the development of systems that can predict the perceived visual quality of Indian social media videos, to control scaling and compression protocols for streaming, provide better user recommendations, and guide content analysis and processing. We demonstrate the value of the new data resource by conducting a study of leading blind video quality models on it, including a new model, called MoEVA, which deploys a mixture of experts to predict video quality. Both the new LIVE-ShareChat dataset and sample source code for MoEVA are being made freely available to the research community at https://github.com/sandeep-sm/LIVE-SC