 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecSal : Deep Recursive Supervision for Visual Saliency Prediction
Paper and Code
Aug 31, 2020

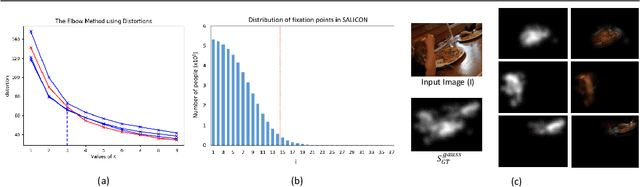
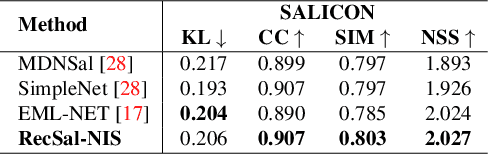
State-of-the-art saliency prediction methods develop upon model architectures or loss functions; while training to generate one target saliency map. However, publicly available saliency prediction datasets can be utilized to create more information for each stimulus than just a final aggregate saliency map. This information when utilized in a biologically inspired fashion can contribute in better prediction performance without the use of models with huge number of parameters. In this light, we propose to extract and use the statistics of (a) region specific saliency and (b) temporal order of fixations, to provide additional context to our network. We show that extra supervision using spatially or temporally sequenced fixations results in achieving better performance in saliency prediction. Further, we also design novel architectures for utilizing this extra information and show that it achieves superior performance over a base model which is devoid of extra supervision. We show that our best method outperforms previous state-of-the-art methods with 50-80% fewer parameters. We also show that our models perform consistently well across all evaluation metrics unlike prior methods.