 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealBirdID: Benchmarking Bird Species Identification in the Era of MLLMs
Mar 27, 2026Fine-grained bird species identification in the wild is frequently unanswerable from a single image: key cues may be non-visual (e.g. vocalization), or obscured due to occlusion, camera angle, or low resolution. Yet today's multimodal systems are typically judged on answerable, in-schema cases, encouraging confident guesses rather than principled abstention. We propose the RealBirdID benchmark: given an image of a bird, a system should either answer with a species or abstain with a concrete, evidence-based rationale: "requires vocalization," "low quality image," or "view obstructed". For each genus, the dataset includes a validation split composed of curated unanswerable examples with labeled rationales, paired with a companion set of clearly answerable instances. We find that (1) the species identification on the answerable set is challenging for a variety of open-source and proprietary models (less than 13% accuracy for MLLMs including GPT-5 and Gemini-2.5 Pro), (2) models with greater classification ability are not necessarily more calibrated to abstain from unanswerable examples, and (3) that MLLMs generally fail at providing correct reasons even when they do abstain. RealBirdID establishes a focused target for abstention-aware fine-grained recognition and a recipe for measuring progress.
3D Space as a Scratchpad for Editable Text-to-Image Generation
Jan 21, 2026Recent progress in large language models (LLMs) has shown that reasoning improves when intermediate thoughts are externalized into explicit workspaces, such as chain-of-thought traces or tool-augmented reasoning. Yet, visual language models (VLMs) lack an analogous mechanism for spatial reasoning, limiting their ability to generate images that accurately reflect geometric relations, object identities, and compositional intent. We introduce the concept of a spatial scratchpad -- a 3D reasoning substrate that bridges linguistic intent and image synthesis. Given a text prompt, our framework parses subjects and background elements, instantiates them as editable 3D meshes, and employs agentic scene planning for placement, orientation, and viewpoint selection. The resulting 3D arrangement is rendered back into the image domain with identity-preserving cues, enabling the VLM to generate spatially consistent and visually coherent outputs. Unlike prior 2D layout-based methods, our approach supports intuitive 3D edits that propagate reliably into final images. Empirically, it achieves a 32% improvement in text alignment on GenAI-Bench, demonstrating the benefit of explicit 3D reasoning for precise, controllable image generation. Our results highlight a new paradigm for vision-language models that deliberate not only in language, but also in space. Code and visualizations at https://oindrilasaha.github.io/3DScratchpad/
Generate, Transduct, Adapt: Iterative Transduction with VLMs
Jan 10, 2025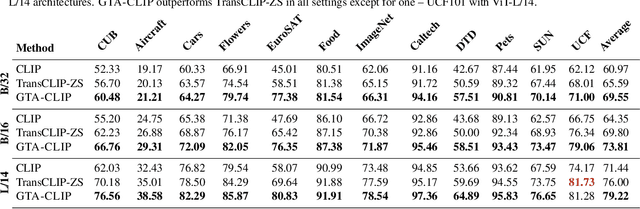
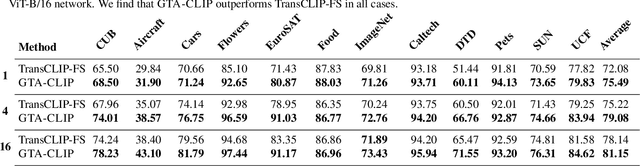
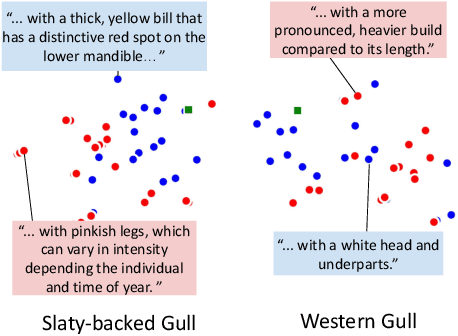
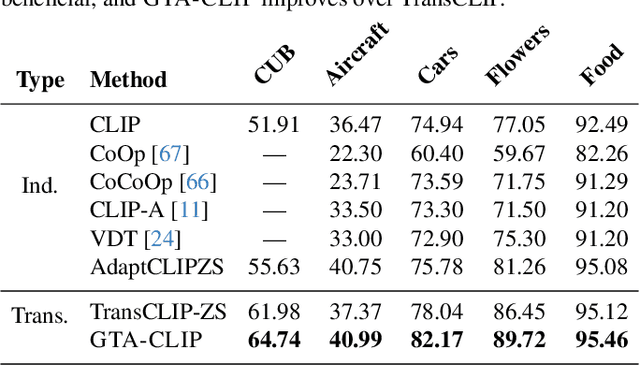
Transductive zero-shot learning with vision-language models leverages image-image similarities within the dataset to achieve better classification accuracy compared to the inductive setting. However, there is little work that explores the structure of the language space in this context. We propose GTA-CLIP, a novel technique that incorporates supervision from language models for joint transduction in language and vision spaces. Our approach is iterative and consists of three steps: (i) incrementally exploring the attribute space by querying language models, (ii) an attribute-augmented transductive inference procedure, and (iii) fine-tuning the language and vision encoders based on inferred labels within the dataset. Through experiments with CLIP encoders, we demonstrate that GTA-CLIP, yields an average performance improvement of 8.6% and 3.7% across 12 datasets and 3 encoders, over CLIP and transductive CLIP respectively in the zero-shot setting. We also observe similar improvements in a few-shot setting. We present ablation studies that demonstrate the value of each step and visualize how the vision and language spaces evolve over iterations driven by the transductive learning.
YouDream: Generating Anatomically Controllable Consistent Text-to-3D Animals
Jun 24, 2024

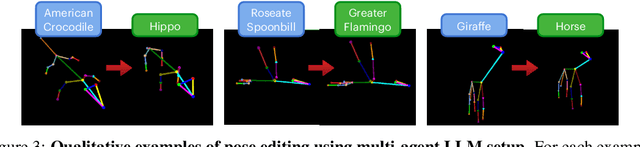

3D generation guided by text-to-image diffusion models enables the creation of visually compelling assets. However previous methods explore generation based on image or text. The boundaries of creativity are limited by what can be expressed through words or the images that can be sourced. We present YouDream, a method to generate high-quality anatomically controllable animals. YouDream is guided using a text-to-image diffusion model controlled by 2D views of a 3D pose prior. Our method generates 3D animals that are not possible to create using previous text-to-3D generative methods. Additionally, our method is capable of preserving anatomic consistency in the generated animals, an area where prior text-to-3D approaches often struggle. Moreover, we design a fully automated pipeline for generating commonly found animals. To circumvent the need for human intervention to create a 3D pose, we propose a multi-agent LLM that adapts poses from a limited library of animal 3D poses to represent the desired animal. A user study conducted on the outcomes of YouDream demonstrates the preference of the animal models generated by our method over others. Turntable results and code are released at https://youdream3d.github.io/
Decomposed evaluations of geographic disparities in text-to-image models
Jun 17, 2024Recent work has identified substantial disparities in generated images of different geographic regions, including stereotypical depictions of everyday objects like houses and cars. However, existing measures for these disparities have been limited to either human evaluations, which are time-consuming and costly, or automatic metrics evaluating full images, which are unable to attribute these disparities to specific parts of the generated images. In this work, we introduce a new set of metrics, Decomposed Indicators of Disparities in Image Generation (Decomposed-DIG), that allows us to separately measure geographic disparities in the depiction of objects and backgrounds in generated images. Using Decomposed-DIG, we audit a widely used latent diffusion model and find that generated images depict objects with better realism than backgrounds and that backgrounds in generated images tend to contain larger regional disparities than objects. We use Decomposed-DIG to pinpoint specific examples of disparities, such as stereotypical background generation in Africa, struggling to generate modern vehicles in Africa, and unrealistically placing some objects in outdoor settings. Informed by our metric, we use a new prompting structure that enables a 52% worst-region improvement and a 20% average improvement in generated background diversity.
C3DAG: Controlled 3D Animal Generation using 3D pose guidance
Jun 11, 2024


Recent advancements in text-to-3D generation have demonstrated the ability to generate high quality 3D assets. However while generating animals these methods underperform, often portraying inaccurate anatomy and geometry. Towards ameliorating this defect, we present C3DAG, a novel pose-Controlled text-to-3D Animal Generation framework which generates a high quality 3D animal consistent with a given pose. We also introduce an automatic 3D shape creator tool, that allows dynamic pose generation and modification via a web-based tool, and that generates a 3D balloon animal using simple geometries. A NeRF is then initialized using this 3D shape using depth-controlled SDS. In the next stage, the pre-trained NeRF is fine-tuned using quadruped-pose-controlled SDS. The pipeline that we have developed not only produces geometrically and anatomically consistent results, but also renders highly controlled 3D animals, unlike prior methods which do not allow fine-grained pose control.
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Jan 04, 2024The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this "bag-level" image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We plan to release the benchmark, consisting of 7 datasets, which will contribute to future research in zero-shot recognition.
PARTICLE: Part Discovery and Contrastive Learning for Fine-grained Recognition
Sep 25, 2023



We develop techniques for refining representations for fine-grained classification and segmentation tasks in a self-supervised manner. We find that fine-tuning methods based on instance-discriminative contrastive learning are not as effective, and posit that recognizing part-specific variations is crucial for fine-grained categorization. We present an iterative learning approach that incorporates part-centric equivariance and invariance objectives. First, pixel representations are clustered to discover parts. We analyze the representations from convolutional and vision transformer networks that are best suited for this task. Then, a part-centric learning step aggregates and contrasts representations of parts within an image. We show that this improves the performance on image classification and part segmentation tasks across datasets. For example, under a linear-evaluation scheme, the classification accuracy of a ResNet50 trained on ImageNet using DetCon, a self-supervised learning approach, improves from 35.4% to 42.0% on the Caltech-UCSD Birds, from 35.5% to 44.1% on the FGVC Aircraft, and from 29.7% to 37.4% on the Stanford Cars. We also observe significant gains in few-shot part segmentation tasks using the proposed technique, while instance-discriminative learning was not as effective. Smaller, yet consistent, improvements are also observed for stronger networks based on transformers.
Improving Few-Shot Part Segmentation using Coarse Supervision
Apr 11, 2022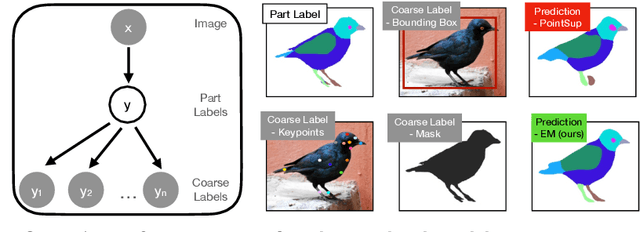

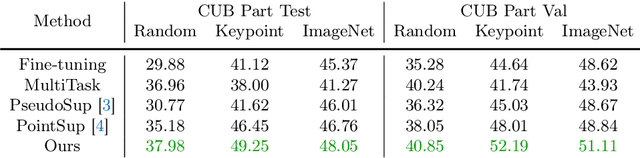

A significant bottleneck in training deep networks for part segmentation is the cost of obtaining detailed annotations. We propose a framework to exploit coarse labels such as figure-ground masks and keypoint locations that are readily available for some categories to improve part segmentation models. A key challenge is that these annotations were collected for different tasks and with different labeling styles and cannot be readily mapped to the part labels. To this end, we propose to jointly learn the dependencies between labeling styles and the part segmentation model, allowing us to utilize supervision from diverse labels. To evaluate our approach we develop a benchmark on the Caltech-UCSD birds and OID Aircraft dataset. Our approach outperforms baselines based on multi-task learning, semi-supervised learning, and competitive methods relying on loss functions manually designed to exploit sparse-supervision.
GANORCON: Are Generative Models Useful for Few-shot Segmentation?
Dec 01, 2021


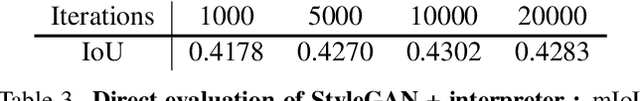
Advances in generative modeling based on GANs has motivated the community to find their use beyond image generation and editing tasks. In particular, several recent works have shown that GAN representations can be re-purposed for discriminative tasks such as part segmentation, especially when training data is limited. But how do these improvements stack-up against recent advances in self-supervised learning? Motivated by this we present an alternative approach based on contrastive learning and compare their performance on standard few-shot part segmentation benchmarks. Our experiments reveal that not only do the GAN-based approach offer no significant performance advantage, their multi-step training is complex, nearly an order-of-magnitude slower, and can introduce additional bias. These experiments suggest that the inductive biases of generative models, such as their ability to disentangle shape and texture, are well captured by standard feed-forward networks trained using contrastive learning. These experiments suggest that the inductive biases present in current generative models, such as their ability to disentangle shape and texture, are well captured by standard feed-forward networks trained using contrastive learning.