 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher Encoder-Student Decoder Denoising Guided Segmentation Network for Anomaly Detection
Jan 21, 2025



Visual anomaly detection is a highly challenging task, often categorized as a one-class classification and segmentation problem. Recent studies have demonstrated that the student-teacher (S-T) framework effectively addresses this challenge. However, most S-T frameworks rely solely on pre-trained teacher networks to guide student networks in learning multi-scale similar features, overlooking the potential of the student networks to enhance learning through multi-scale feature fusion. In this study, we propose a novel model named PFADSeg, which integrates a pre-trained teacher network, a denoising student network with multi-scale feature fusion, and a guided anomaly segmentation network into a unified framework. By adopting a unique teacher-encoder and student-decoder denoising mode, the model improves the student network's ability to learn from teacher network features. Furthermore, an adaptive feature fusion mechanism is introduced to train a self-supervised segmentation network that synthesizes anomaly masks autonomously, significantly increasing detection performance. Evaluated on the MVTec AD dataset, PFADSeg achieves state-of-the-art results with an image-level AUC of 98.9%, a pixel-level mean precision of 76.4%, and an instance-level mean precision of 78.7%.
A Self-Learning Multimodal Approach for Fake News Detection
Dec 08, 2024



The rapid growth of social media has resulted in an explosion of online news content, leading to a significant increase in the spread of misleading or false information. While machine learning techniques have been widely applied to detect fake news, the scarcity of labeled datasets remains a critical challenge. Misinformation frequently appears as paired text and images, where a news article or headline is accompanied by a related visuals. In this paper, we introduce a self-learning multimodal model for fake news classification. The model leverages contrastive learning, a robust method for feature extraction that operates without requiring labeled data, and integrates the strengths of Large Language Models (LLMs) to jointly analyze both text and image features. LLMs are excel at this task due to their ability to process diverse linguistic data drawn from extensive training corpora. Our experimental results on a public dataset demonstrate that the proposed model outperforms several state-of-the-art classification approaches, achieving over 85% accuracy, precision, recall, and F1-score. These findings highlight the model's effectiveness in tackling the challenges of multimodal fake news detection.
Uncertainty-Aware Explainable Recommendation with Large Language Models
Jan 31, 2024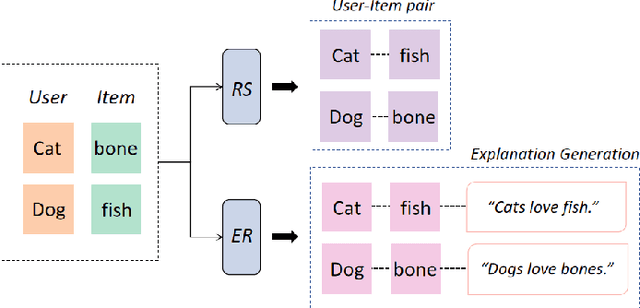
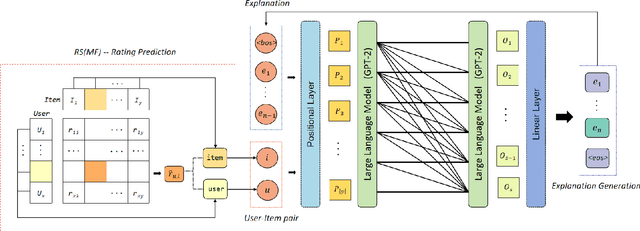

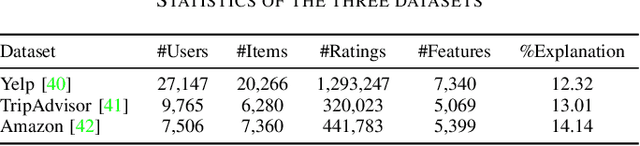
Providing explanations within the recommendation system would boost user satisfaction and foster trust, especially by elaborating on the reasons for selecting recommended items tailored to the user. The predominant approach in this domain revolves around generating text-based explanations, with a notable emphasis on applying large language models (LLMs). However, refining LLMs for explainable recommendations proves impractical due to time constraints and computing resource limitations. As an alternative, the current approach involves training the prompt rather than the LLM. In this study, we developed a model that utilizes the ID vectors of user and item inputs as prompts for GPT-2. We employed a joint training mechanism within a multi-task learning framework to optimize both the recommendation task and explanation task. This strategy enables a more effective exploration of users' interests, improving recommendation effectiveness and user satisfaction. Through the experiments, our method achieving 1.59 DIV, 0.57 USR and 0.41 FCR on the Yelp, TripAdvisor and Amazon dataset respectively, demonstrates superior performance over four SOTA methods in terms of explainability evaluation metric. In addition, we identified that the proposed model is able to ensure stable textual quality on the three public datasets.
X-Transfer: A Transfer Learning-Based Framework for Robust GAN-Generated Fake Image Detection
Oct 07, 2023



Generative adversarial networks (GANs) have remarkably advanced in diverse domains, especially image generation and editing. However, the misuse of GANs for generating deceptive images raises significant security concerns, including face replacement and fake accounts, which have gained widespread attention. Consequently, there is an urgent need for effective detection methods to distinguish between real and fake images. Some of the current research centers around the application of transfer learning. Nevertheless, it encounters challenges such as knowledge forgetting from the original dataset and inadequate performance when dealing with imbalanced data during training. To alleviate the above issues, this paper introduces a novel GAN-generated image detection algorithm called X-Transfer. This model enhances transfer learning by utilizing two sibling neural networks that employ interleaved parallel gradient transmission. This approach also effectively mitigates the problem of excessive knowledge forgetting. In addition, we combine AUC loss term and cross-entropy loss to enhance the model's performance comprehensively. The AUC loss approximates the AUC metric using WMW statistics, ensuring differentiability and improving the performance of traditional AUC evaluation. We carry out comprehensive experiments on multiple facial image datasets. The results show that our model outperforms the general transferring approach, and the best accuracy achieves 99.04%, which is increased by approximately 10%. Furthermore, we demonstrate excellent performance on non-face datasets, validating its generality and broader application prospects.
Harnessing the Power of Text-image Contrastive Models for Automatic Detection of Online Misinformation
Apr 19, 2023As growing usage of social media websites in the recent decades, the amount of news articles spreading online rapidly, resulting in an unprecedented scale of potentially fraudulent information. Although a plenty of studies have applied the supervised machine learning approaches to detect such content, the lack of gold standard training data has hindered the development. Analysing the single data format, either fake text description or fake image, is the mainstream direction for the current research. However, the misinformation in real-world scenario is commonly formed as a text-image pair where the news article/news title is described as text content, and usually followed by the related image. Given the strong ability of learning features without labelled data, contrastive learning, as a self-learning approach, has emerged and achieved success on the computer vision. In this paper, our goal is to explore the constrastive learning in the domain of misinformation identification. We developed a self-learning model and carried out the comprehensive experiments on a public data set named COSMOS. Comparing to the baseline classifier, our model shows the superior performance of non-matched image-text pair detection (approximately 10%) when the training data is insufficient. In addition, we observed the stability for contrsative learning and suggested the use of it offers large reductions in the number of training data, whilst maintaining comparable classification results.
Robust Multimodal Image Registration Using Deep Recurrent Reinforcement Learning
Jan 29, 2020


The crucial components of a conventional image registration method are the choice of the right feature representations and similarity measures. These two components, although elaborately designed, are somewhat handcrafted using human knowledge. To this end, these two components are tackled in an end-to-end manner via reinforcement learning in this work. Specifically, an artificial agent, which is composed of a combined policy and value network, is trained to adjust the moving image toward the right direction. We train this network using an asynchronous reinforcement learning algorithm, where a customized reward function is also leveraged to encourage robust image registration. This trained network is further incorporated with a lookahead inference to improve the registration capability. The advantage of this algorithm is fully demonstrated by our superior performance on clinical MR and CT image pairs to other state-of-the-art medical image registration methods.
Denoising of 3-D Magnetic Resonance Images Using a Residual Encoder-Decoder Wasserstein Generative Adversarial Network
Aug 12, 2018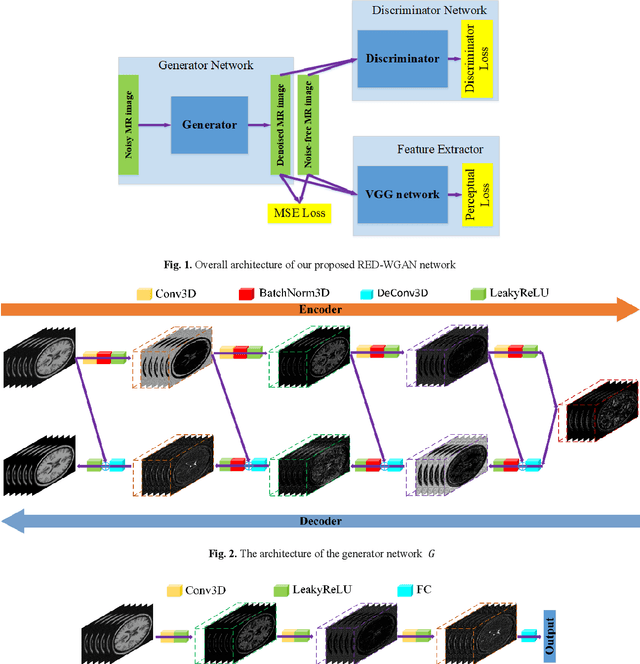
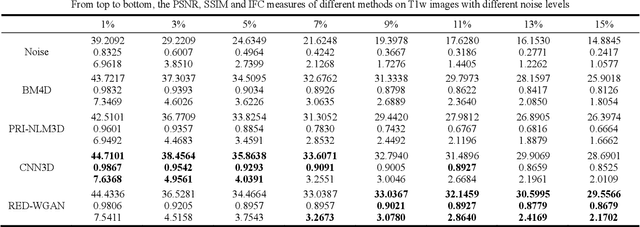
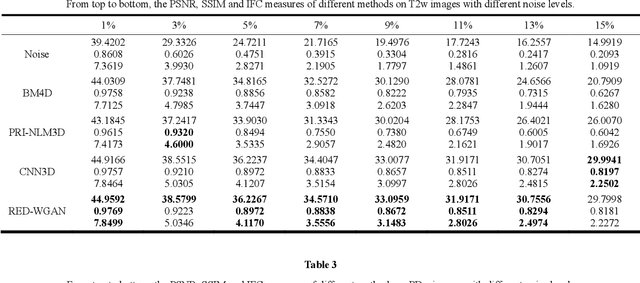
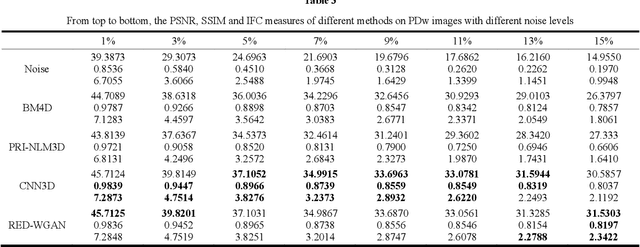
Structure-preserved denoising of 3-D magnetic resonance images (MRI) is a critical step in the medical image analysis. Over the past years, many algorithms have been proposed with impressive performances. Inspired by the idea of deep learning, in this paper, we introduce a MRI denoising method based on the residual encoder-decoder Wasserstein generative adversarial network (RED-WGAN). Specifically, to explore the structure similarity among neighboring slices, 3-D configuration are utilized as the basic processing unit. Residual autoencoder, combined with deconvolution operations are introduced into the generator network. Furthermore, to alleviate the shortcoming of traditional mean-squared error (MSE) loss function for over-smoothing, the perceptual similarity, which is implemented by calculating the distances in the feature space extracted by a pre-trained VGG-19 network, is incorporated with MSE and adversarial losses to form the new loss function. Extensive experiments are studied to access the performance of the proposed method. The experimental results show that the proposed RED-WGAN achieves superior performance relative to several state-of-art methods in both simulated and clinical data. Especially, our method demonstrates powerful ability in both noise suppression and structure preservation.
Study on Sparse Representation based Classification for Biometric Verification
Feb 27, 2015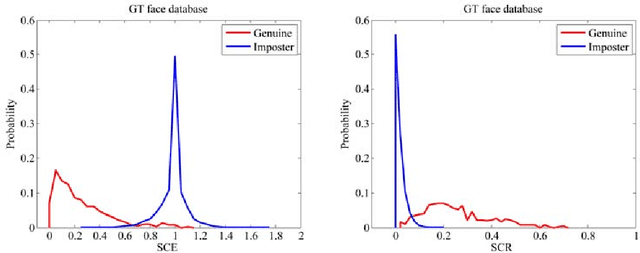

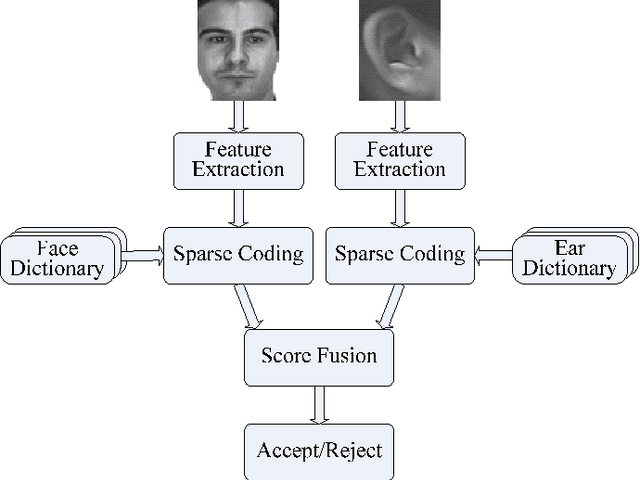
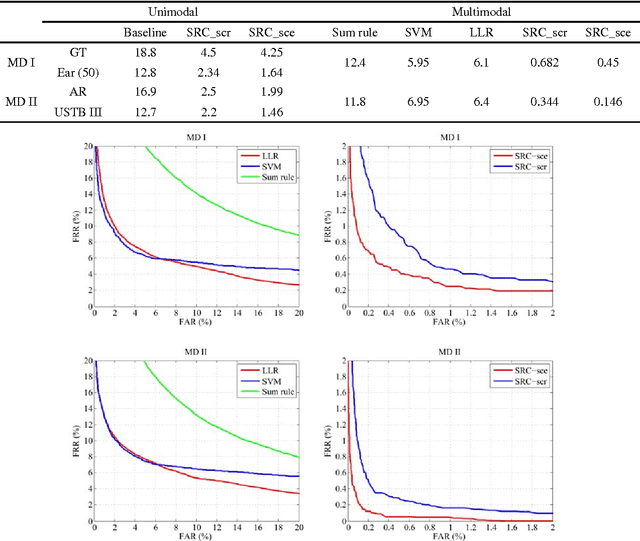
In this paper, we propose a multimodal verification system integrating face and ear based on sparse representation based classification (SRC). The face and ear query samples are first encoded separately to derive sparsity-based match scores, and which are then combined with sum-rule fusion for verification. Apart from validating the encouraging performance of SRC-based multimodal verification, this paper also dedicates to provide a clear understanding about the characteristics of SRC-based biometric verification. To this end, two sparsity-based metrics, i.e. spare coding error (SCE) and sparse contribution rate (SCR), are involved, together with face and ear unimodal SRC-based verification. As for the issue that SRC-based biometric verification may suffer from heavy computational burden and verification accuracy degradation with increase of enrolled subjects, we argue that it could be properly resolved by exploiting small random dictionary for sparsity-based score computation, which consists of training samples from a limited number of randomly selected subjects. Experimental results demonstrate the superiority of SRC-based multimodal verification compared to the state-of-the-art multimodal methods like likelihood ratio (LLR), support vector machine (SVM), and the sum-rule fusion methods using cosine similarity, meanwhile the idea of using small random dictionary is feasible in both effectiveness and efficiency.