 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeach-to-Reason: Competition-Guided Reasoning with a Self-Improving Teacher
Jun 24, 2026Chest X-ray visual question answering (CXR VQA) requires models not only to predict correct answers, but also to produce reliable medical reasoning. However, existing reinforcement-learning-based training typically relies on answer-level rewards, which are often too coarse to improve chain-of-thought (CoT) quality and can become ineffective when group-level advantages collapse to zero. We propose \textbf{Teach-to-Reason (T2R)}, a framework that introduces comparison-based supervision into CoT optimization through a self-improving \emph{Teacher} and a competition-guided \emph{Reasoner}. As the Teacher is iteratively strengthened via self-competition, the Reasoner is optimized against progressively stronger Teacher-generated references. We further introduce a case-wise reward design that preserves the original reward-induced positive/negative partition when it is informative, and restores supervision from competition scores when the original reward signal degenerates. Experiments on multiple CXR open-ended VQA benchmarks show that T2R consistently outperforms strong baselines, indicating that comparison-based supervision, when integrated in a controlled and principled manner, provides a more effective training signal for reasoning optimization.
Weight Group-wise Post-Training Quantization for Medical Foundation Model
Apr 09, 2026Foundation models have achieved remarkable results in medical image analysis. However, its large network architecture and high computational complexity significantly impact inference speed, limiting its application on terminal medical devices. Quantization, a technique that compresses models into low-bit versions, is a solution to this challenge. In this paper, we propose a post-training quantization algorithm, Permutation-COMQ. It eliminates the need for backpropagation by using simple dot products and rounding operations, thereby removing hyperparameter tuning and simplifying the process. Additionally, we introduce a weight-aware strategy that reorders the weight within each layer to address the accuracy degradation induced by channel-wise scaling during quantization, while preserving channel structure. Experiments demonstrate that our method achieves the best results in 2-bit, 4-bit, and 8-bit quantization.
Evidence-Based Actor-Verifier Reasoning for Echocardiographic Agents
Apr 07, 2026Echocardiography plays an important role in the screening and diagnosis of cardiovascular diseases. However, automated intelligent analysis of echocardiographic data remains challenging due to complex cardiac dynamics and strong view heterogeneity. In recent years, visual language models (VLM) have opened a new avenue for building ultrasound understanding systems for clinical decision support. Nevertheless, most existing methods formulate this task as a direct mapping from video and question to answer, making them vulnerable to template shortcuts and spurious explanations. To address these issues, we propose EchoTrust, an evidence-driven Actor-Verifier framework for trustworthy reasoning in echocardiography VLM-based agents. EchoTrust produces a structured intermediate representation that is subsequently analyzed by distinct roles, enabling more reliable and interpretable decision-making for high-stakes clinical applications.
DEP: A Decentralized Large Language Model Evaluation Protocol
Mar 01, 2026With the rapid development of Large Language Models (LLMs), a large number of benchmarks have been proposed. However, most benchmarks lack unified evaluation standard and require the manual implementation of custom scripts, making results hard to ensure consistency and reproducibility. Furthermore, mainstream evaluation frameworks are centralized, with datasets and answers, which increases the risk of benchmark leakage. To address these issues, we propose a Decentralized Evaluation Protocol (DEP), a decentralized yet unified and standardized evaluation framework through a matching server without constraining benchmarks. The server can be mounted locally or deployed remotely, and once adapted, it can be reused over the long term. By decoupling users, LLMs, and benchmarks, DEP enables modular, plug-and-play evaluation: benchmark files and evaluation logic stay exclusively on the server side. In remote setting, users cannot access the ground truth, thereby achieving data isolation and leak-proof evaluation. To facilitate practical adoption, we develop DEP Toolkit, a protocol-compatible toolkit that supports features such as breakpoint resume, concurrent requests, and congestion control. We also provide detailed documentation for adapting new benchmarks to DEP. Using DEP toolkit, we evaluate multiple LLMs across benchmarks. Experimental results verify the effectiveness of DEP and show that it reduces the cost of deploying benchmark evaluations. As of February 2026, we have adapted over 60 benchmarks and continue to promote community co-construction to support unified evaluation across various tasks and domains.
Diffusion Epistemic Uncertainty with Asymmetric Learning for Diffusion-Generated Image Detection
Jan 21, 2026The rapid progress of diffusion models highlights the growing need for detecting generated images. Previous research demonstrates that incorporating diffusion-based measurements, such as reconstruction error, can enhance the generalizability of detectors. However, ignoring the differing impacts of aleatoric and epistemic uncertainty on reconstruction error can undermine detection performance. Aleatoric uncertainty, arising from inherent data noise, creates ambiguity that impedes accurate detection of generated images. As it reflects random variations within the data (e.g., noise in natural textures), it does not help distinguish generated images. In contrast, epistemic uncertainty, which represents the model's lack of knowledge about unfamiliar patterns, supports detection. In this paper, we propose a novel framework, Diffusion Epistemic Uncertainty with Asymmetric Learning~(DEUA), for detecting diffusion-generated images. We introduce Diffusion Epistemic Uncertainty~(DEU) estimation via the Laplace approximation to assess the proximity of data to the manifold of diffusion-generated samples. Additionally, an asymmetric loss function is introduced to train a balanced classifier with larger margins, further enhancing generalizability. Extensive experiments on large-scale benchmarks validate the state-of-the-art performance of our method.
nncase: An End-to-End Compiler for Efficient LLM Deployment on Heterogeneous Storage Architectures
Dec 25, 2025The efficient deployment of large language models (LLMs) is hindered by memory architecture heterogeneity, where traditional compilers suffer from fragmented workflows and high adaptation costs. We present nncase, an open-source, end-to-end compilation framework designed to unify optimization across diverse targets. Central to nncase is an e-graph-based term rewriting engine that mitigates the phase ordering problem, enabling global exploration of computation and data movement strategies. The framework integrates three key modules: Auto Vectorize for adapting to heterogeneous computing units, Auto Distribution for searching parallel strategies with cost-aware communication optimization, and Auto Schedule for maximizing on-chip cache locality. Furthermore, a buffer-aware Codegen phase ensures efficient kernel instantiation. Evaluations show that nncase outperforms mainstream frameworks like MLC LLM and Intel IPEX on Qwen3 series models and achieves performance comparable to the hand-optimized llama.cpp on CPUs, demonstrating the viability of automated compilation for high-performance LLM deployment. The source code is available at https://github.com/kendryte/nncase.
DCD: A Semantic Segmentation Model for Fetal Ultrasound Four-Chamber View
Jun 10, 2025Accurate segmentation of anatomical structures in the apical four-chamber (A4C) view of fetal echocardiography is essential for early diagnosis and prenatal evaluation of congenital heart disease (CHD). However, precise segmentation remains challenging due to ultrasound artifacts, speckle noise, anatomical variability, and boundary ambiguity across different gestational stages. To reduce the workload of sonographers and enhance segmentation accuracy, we propose DCD, an advanced deep learning-based model for automatic segmentation of key anatomical structures in the fetal A4C view. Our model incorporates a Dense Atrous Spatial Pyramid Pooling (Dense ASPP) module, enabling superior multi-scale feature extraction, and a Convolutional Block Attention Module (CBAM) to enhance adaptive feature representation. By effectively capturing both local and global contextual information, DCD achieves precise and robust segmentation, contributing to improved prenatal cardiac assessment.
A Self-Learning Multimodal Approach for Fake News Detection
Dec 08, 2024



The rapid growth of social media has resulted in an explosion of online news content, leading to a significant increase in the spread of misleading or false information. While machine learning techniques have been widely applied to detect fake news, the scarcity of labeled datasets remains a critical challenge. Misinformation frequently appears as paired text and images, where a news article or headline is accompanied by a related visuals. In this paper, we introduce a self-learning multimodal model for fake news classification. The model leverages contrastive learning, a robust method for feature extraction that operates without requiring labeled data, and integrates the strengths of Large Language Models (LLMs) to jointly analyze both text and image features. LLMs are excel at this task due to their ability to process diverse linguistic data drawn from extensive training corpora. Our experimental results on a public dataset demonstrate that the proposed model outperforms several state-of-the-art classification approaches, achieving over 85% accuracy, precision, recall, and F1-score. These findings highlight the model's effectiveness in tackling the challenges of multimodal fake news detection.
Learning from Noisy Labels via Conditional Distributionally Robust Optimization
Nov 26, 2024While crowdsourcing has emerged as a practical solution for labeling large datasets, it presents a significant challenge in learning accurate models due to noisy labels from annotators with varying levels of expertise. Existing methods typically estimate the true label posterior, conditioned on the instance and noisy annotations, to infer true labels or adjust loss functions. These estimates, however, often overlook potential misspecification in the true label posterior, which can degrade model performances, especially in high-noise scenarios. To address this issue, we investigate learning from noisy annotations with an estimated true label posterior through the framework of conditional distributionally robust optimization (CDRO). We propose formulating the problem as minimizing the worst-case risk within a distance-based ambiguity set centered around a reference distribution. By examining the strong duality of the formulation, we derive upper bounds for the worst-case risk and develop an analytical solution for the dual robust risk for each data point. This leads to a novel robust pseudo-labeling algorithm that leverages the likelihood ratio test to construct a pseudo-empirical distribution, providing a robust reference probability distribution in CDRO. Moreover, to devise an efficient algorithm for CDRO, we derive a closed-form expression for the empirical robust risk and the optimal Lagrange multiplier of the dual problem, facilitating a principled balance between robustness and model fitting. Our experimental results on both synthetic and real-world datasets demonstrate the superiority of our method.
Uncertainty-Aware Explainable Recommendation with Large Language Models
Jan 31, 2024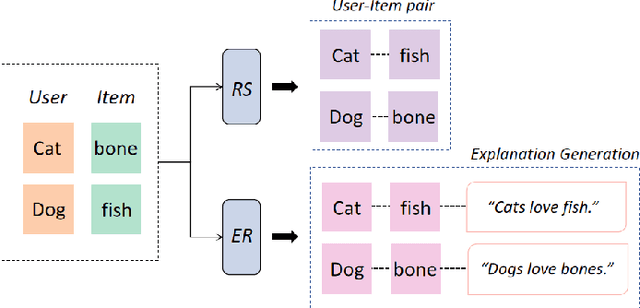
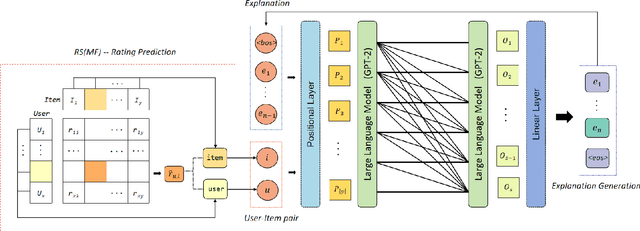

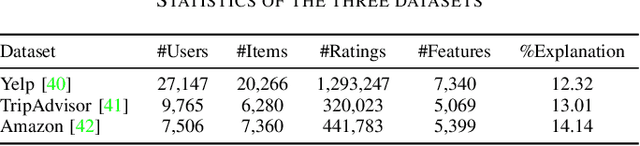
Providing explanations within the recommendation system would boost user satisfaction and foster trust, especially by elaborating on the reasons for selecting recommended items tailored to the user. The predominant approach in this domain revolves around generating text-based explanations, with a notable emphasis on applying large language models (LLMs). However, refining LLMs for explainable recommendations proves impractical due to time constraints and computing resource limitations. As an alternative, the current approach involves training the prompt rather than the LLM. In this study, we developed a model that utilizes the ID vectors of user and item inputs as prompts for GPT-2. We employed a joint training mechanism within a multi-task learning framework to optimize both the recommendation task and explanation task. This strategy enables a more effective exploration of users' interests, improving recommendation effectiveness and user satisfaction. Through the experiments, our method achieving 1.59 DIV, 0.57 USR and 0.41 FCR on the Yelp, TripAdvisor and Amazon dataset respectively, demonstrates superior performance over four SOTA methods in terms of explainability evaluation metric. In addition, we identified that the proposed model is able to ensure stable textual quality on the three public datasets.