 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan ChatGPT assist visually impaired people with micro-navigation?
Jul 31, 2024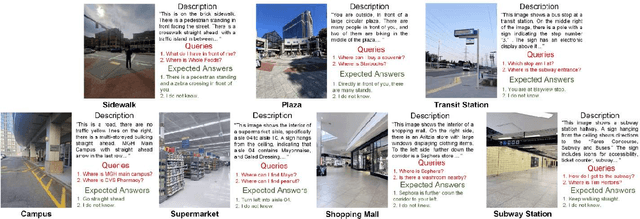



Objective: Micro-navigation poses challenges for blind and visually impaired individuals. They often need to ask for sighted assistance. We explored the feasibility of utilizing ChatGPT as a virtual assistant to provide navigation directions. Methods: We created a test set of outdoor and indoor micro-navigation scenarios consisting of 113 scene images and their human-generated text descriptions. A total of 412 way-finding queries and their expected responses were compiled based on the scenarios. Not all queries are answerable based on the information available in the scene image. "I do not know"response was expected for unanswerable queries, which served as negative cases. High level orientation responses were expected, and step-by-step guidance was not required. ChatGPT 4o was evaluated based on sensitivity (SEN) and specificity (SPE) under different conditions. Results: The default ChatGPT 4o, with scene images as inputs, resulted in SEN and SPE values of 64.8% and 75.9%, respectively. Instruction on how to respond to unanswerable questions did not improve SEN substantially but SPE increased by around 14 percentage points. SEN and SPE both improved substantially, by about 17 and 16 percentage points on average respectively, when human written descriptions of the scenes were provided as input instead of images. Providing further prompt instructions to the assistants when the input was text description did not substantially change the SEN and SPE values. Conclusion: Current native ChatGPT 4o is still unable to provide correct micro-navigation guidance in some cases, probably because its scene understanding is not optimized for navigation purposes. If multi-modal chatbots could interpret scenes with a level of clarity comparable to humans, and also guided by appropriate prompts, they may have the potential to provide assistance to visually impaired for micro-navigation.