 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Contrastive Learning on Graphs
Dec 13, 2022



Inspired by the impressive success of contrastive learning (CL), a variety of graph augmentation strategies have been employed to learn node representations in a self-supervised manner. Existing methods construct the contrastive samples by adding perturbations to the graph structure or node attributes. Although impressive results are achieved, it is rather blind to the wealth of prior information assumed: with the increase of the perturbation degree applied on the original graph, 1) the similarity between the original graph and the generated augmented graph gradually decreases; 2) the discrimination between all nodes within each augmented view gradually increases. In this paper, we argue that both such prior information can be incorporated (differently) into the contrastive learning paradigm following our general ranking framework. In particular, we first interpret CL as a special case of learning to rank (L2R), which inspires us to leverage the ranking order among positive augmented views. Meanwhile, we introduce a self-ranking paradigm to ensure that the discriminative information among different nodes can be maintained and also be less altered to the perturbations of different degrees. Experiment results on various benchmark datasets verify the effectiveness of our algorithm compared with the supervised and unsupervised models.
MNER-QG: An End-to-End MRC framework for Multimodal Named Entity Recognition with Query Grounding
Nov 27, 2022Multimodal named entity recognition (MNER) is a critical step in information extraction, which aims to detect entity spans and classify them to corresponding entity types given a sentence-image pair. Existing methods either (1) obtain named entities with coarse-grained visual clues from attention mechanisms, or (2) first detect fine-grained visual regions with toolkits and then recognize named entities. However, they suffer from improper alignment between entity types and visual regions or error propagation in the two-stage manner, which finally imports irrelevant visual information into texts. In this paper, we propose a novel end-to-end framework named MNER-QG that can simultaneously perform MRC-based multimodal named entity recognition and query grounding. Specifically, with the assistance of queries, MNER-QG can provide prior knowledge of entity types and visual regions, and further enhance representations of both texts and images. To conduct the query grounding task, we provide manual annotations and weak supervisions that are obtained via training a highly flexible visual grounding model with transfer learning. We conduct extensive experiments on two public MNER datasets, Twitter2015 and Twitter2017. Experimental results show that MNER-QG outperforms the current state-of-the-art models on the MNER task, and also improves the query grounding performance.
To be Closer: Learning to Link up Aspects with Opinions
Sep 17, 2021


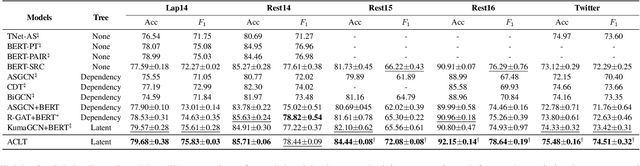
Dependency parse trees are helpful for discovering the opinion words in aspect-based sentiment analysis (ABSA). However, the trees obtained from off-the-shelf dependency parsers are static, and could be sub-optimal in ABSA. This is because the syntactic trees are not designed for capturing the interactions between opinion words and aspect words. In this work, we aim to shorten the distance between aspects and corresponding opinion words by learning an aspect-centric tree structure. The aspect and opinion words are expected to be closer along such tree structure compared to the standard dependency parse tree. The learning process allows the tree structure to adaptively correlate the aspect and opinion words, enabling us to better identify the polarity in the ABSA task. We conduct experiments on five aspect-based sentiment datasets, and the proposed model significantly outperforms recent strong baselines. Furthermore, our thorough analysis demonstrates the average distance between aspect and opinion words are shortened by at least 19% on the standard SemEval Restaurant14 dataset.
KVL-BERT: Knowledge Enhanced Visual-and-Linguistic BERT for Visual Commonsense Reasoning
Dec 13, 2020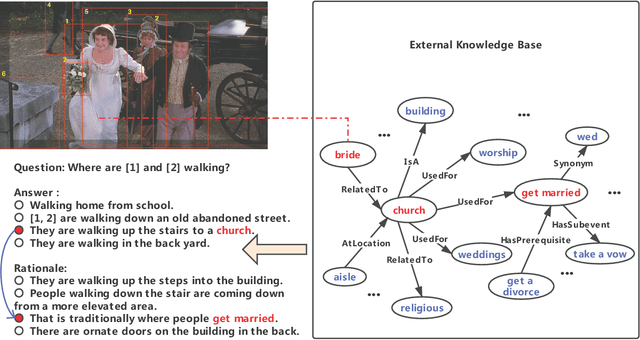


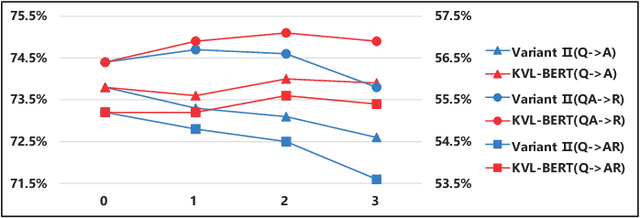
Reasoning is a critical ability towards complete visual understanding. To develop machine with cognition-level visual understanding and reasoning abilities, the visual commonsense reasoning (VCR) task has been introduced. In VCR, given a challenging question about an image, a machine must answer correctly and then provide a rationale justifying its answer. The methods adopting the powerful BERT model as the backbone for learning joint representation of image content and natural language have shown promising improvements on VCR. However, none of the existing methods have utilized commonsense knowledge in visual commonsense reasoning, which we believe will be greatly helpful in this task. With the support of commonsense knowledge, complex questions even if the required information is not depicted in the image can be answered with cognitive reasoning. Therefore, we incorporate commonsense knowledge into the cross-modal BERT, and propose a novel Knowledge Enhanced Visual-and-Linguistic BERT (KVL-BERT for short) model. Besides taking visual and linguistic contents as input, external commonsense knowledge extracted from ConceptNet is integrated into the multi-layer Transformer. In order to reserve the structural information and semantic representation of the original sentence, we propose using relative position embedding and mask-self-attention to weaken the effect between the injected commonsense knowledge and other unrelated components in the input sequence. Compared to other task-specific models and general task-agnostic pre-training models, our KVL-BERT outperforms them by a large margin.
Earlier Attention? Aspect-Aware LSTM for Aspect Sentiment Analysis
May 19, 2019


Aspect-based sentiment analysis (ABSA) aims to predict fine-grained sentiments of comments with respect to given aspect terms or categories. In previous ABSA methods, the importance of aspect has been realized and verified. Most existing LSTM-based models take aspect into account via the attention mechanism, where the attention weights are calculated after the context is modeled in the form of contextual vectors. However, aspect-related information may be already discarded and aspect-irrelevant information may be retained in classic LSTM cells in the context modeling process, which can be improved to generate more effective context representations. This paper proposes a novel variant of LSTM, termed as aspect-aware LSTM (AA-LSTM), which incorporates aspect information into LSTM cells in the context modeling stage before the attention mechanism. Therefore, our AA-LSTM can dynamically produce aspect-aware contextual representations. We experiment with several representative LSTM-based models by replacing the classic LSTM cells with the AA-LSTM cells. Experimental results on SemEval-2014 Datasets demonstrate the effectiveness of AA-LSTM.