 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVL-BERT: Knowledge Enhanced Visual-and-Linguistic BERT for Visual Commonsense Reasoning
Paper and Code
Dec 13, 2020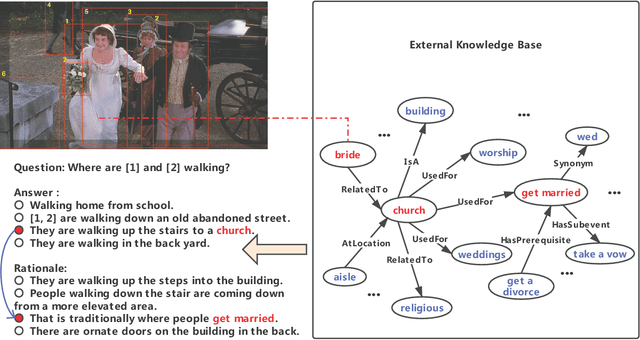


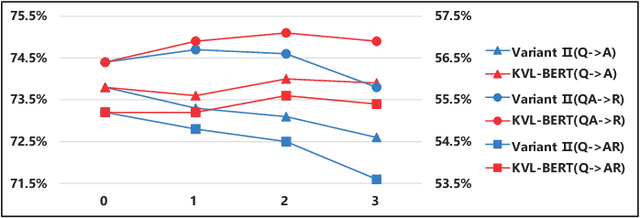
Reasoning is a critical ability towards complete visual understanding. To develop machine with cognition-level visual understanding and reasoning abilities, the visual commonsense reasoning (VCR) task has been introduced. In VCR, given a challenging question about an image, a machine must answer correctly and then provide a rationale justifying its answer. The methods adopting the powerful BERT model as the backbone for learning joint representation of image content and natural language have shown promising improvements on VCR. However, none of the existing methods have utilized commonsense knowledge in visual commonsense reasoning, which we believe will be greatly helpful in this task. With the support of commonsense knowledge, complex questions even if the required information is not depicted in the image can be answered with cognitive reasoning. Therefore, we incorporate commonsense knowledge into the cross-modal BERT, and propose a novel Knowledge Enhanced Visual-and-Linguistic BERT (KVL-BERT for short) model. Besides taking visual and linguistic contents as input, external commonsense knowledge extracted from ConceptNet is integrated into the multi-layer Transformer. In order to reserve the structural information and semantic representation of the original sentence, we propose using relative position embedding and mask-self-attention to weaken the effect between the injected commonsense knowledge and other unrelated components in the input sequence. Compared to other task-specific models and general task-agnostic pre-training models, our KVL-BERT outperforms them by a large margin.