 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnitho: A Unified Multi-Task Framework for Computational Lithography
Nov 14, 2025Reliable, generalizable data foundations are critical for enabling large-scale models in computational lithography. However, essential tasks-mask generation, rule violation detection, and layout optimization-are often handled in isolation, hindered by scarce datasets and limited modeling approaches. To address these challenges, we introduce Unitho, a unified multi-task large vision model built upon the Transformer architecture. Trained on a large-scale industrial lithography simulation dataset with hundreds of thousands of cases, Unitho supports end-to-end mask generation, lithography simulation, and rule violation detection. By enabling agile and high-fidelity lithography simulation, Unitho further facilitates the construction of robust data foundations for intelligent EDA. Experimental results validate its effectiveness and generalizability, with performance substantially surpassing academic baselines.
FabGPT: An Efficient Large Multimodal Model for Complex Wafer Defect Knowledge Queries
Jul 15, 2024



Intelligence is key to advancing integrated circuit (IC) fabrication. Recent breakthroughs in Large Multimodal Models (LMMs) have unlocked unparalleled abilities in understanding images and text, fostering intelligent fabrication. Leveraging the power of LMMs, we introduce FabGPT, a customized IC fabrication large multimodal model for wafer defect knowledge query. FabGPT manifests expertise in conducting defect detection in Scanning Electron Microscope (SEM) images, performing root cause analysis, and providing expert question-answering (Q&A) on fabrication processes. FabGPT matches enhanced multimodal features to automatically detect minute defects under complex wafer backgrounds and reduce the subjectivity of manual threshold settings. Besides, the proposed modulation module and interactive corpus training strategy embed wafer defect knowledge into the pre-trained model, effectively balancing Q&A queries related to defect knowledge and original knowledge and mitigating the modality bias issues. Experiments on in-house fab data (SEM-WaD) show that our FabGPT achieves significant performance improvement in wafer defect detection and knowledge querying.
Transformer based Pluralistic Image Completion with Reduced Information Loss
Apr 15, 2024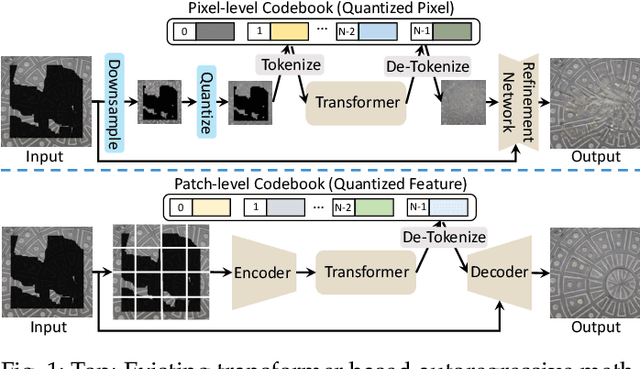


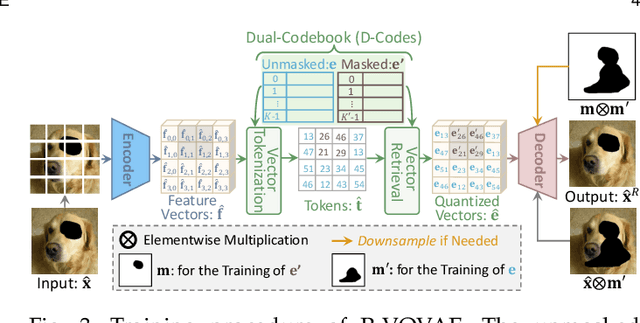
Transformer based methods have achieved great success in image inpainting recently. However, we find that these solutions regard each pixel as a token, thus suffering from an information loss issue from two aspects: 1) They downsample the input image into much lower resolutions for efficiency consideration. 2) They quantize $256^3$ RGB values to a small number (such as 512) of quantized color values. The indices of quantized pixels are used as tokens for the inputs and prediction targets of the transformer. To mitigate these issues, we propose a new transformer based framework called "PUT". Specifically, to avoid input downsampling while maintaining computation efficiency, we design a patch-based auto-encoder P-VQVAE. The encoder converts the masked image into non-overlapped patch tokens and the decoder recovers the masked regions from the inpainted tokens while keeping the unmasked regions unchanged. To eliminate the information loss caused by input quantization, an Un-quantized Transformer is applied. It directly takes features from the P-VQVAE encoder as input without any quantization and only regards the quantized tokens as prediction targets. Furthermore, to make the inpainting process more controllable, we introduce semantic and structural conditions as extra guidance. Extensive experiments show that our method greatly outperforms existing transformer based methods on image fidelity and achieves much higher diversity and better fidelity than state-of-the-art pluralistic inpainting methods on complex large-scale datasets (e.g., ImageNet). Codes are available at https://github.com/liuqk3/PUT.
Interpretable Short-Term Load Forecasting via Multi-Scale Temporal Decomposition
Feb 18, 2024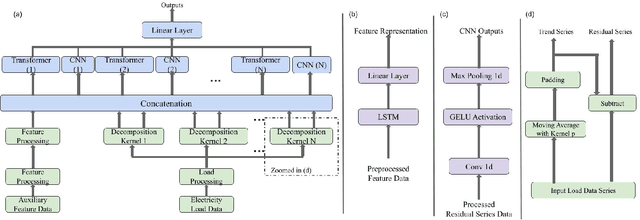
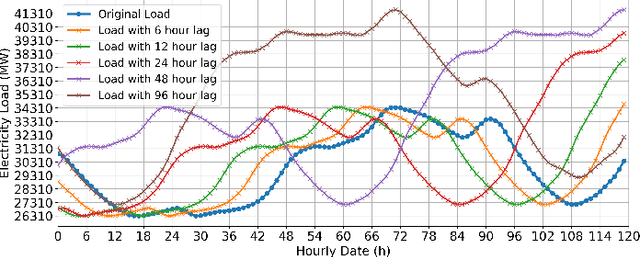
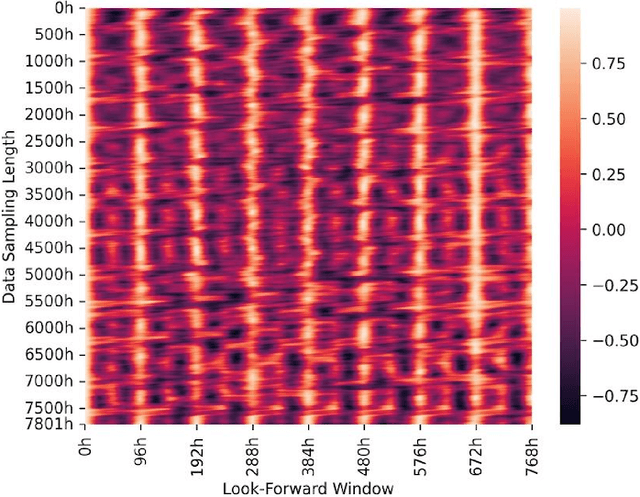
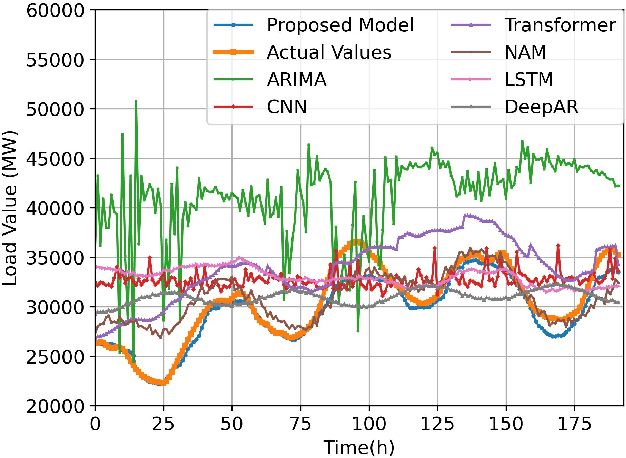
Rapid progress in machine learning and deep learning has enabled a wide range of applications in the electricity load forecasting of power systems, for instance, univariate and multivariate short-term load forecasting. Though the strong capabilities of learning the non-linearity of the load patterns and the high prediction accuracy have been achieved, the interpretability of typical deep learning models for electricity load forecasting is less studied. This paper proposes an interpretable deep learning method, which learns a linear combination of neural networks that each attends to an input time feature. We also proposed a multi-scale time series decomposition method to deal with the complex time patterns. Case studies have been carried out on the Belgium central grid load dataset and the proposed model demonstrated better accuracy compared to the frequently applied baseline model. Specifically, the proposed multi-scale temporal decomposition achieves the best MSE, MAE and RMSE of 0.52, 0.57 and 0.72 respectively. As for interpretability, on one hand, the proposed method displays generalization capability. On the other hand, it can demonstrate not only the feature but also the temporal interpretability compared to other baseline methods. Besides, the global time feature interpretabilities are also obtained. Obtaining global feature interpretabilities allows us to catch the overall patterns, trends, and cyclicality in load data while also revealing the significance of various time-related features in forming the final outputs.
Siamese-DETR for Generic Multi-Object Tracking
Oct 27, 2023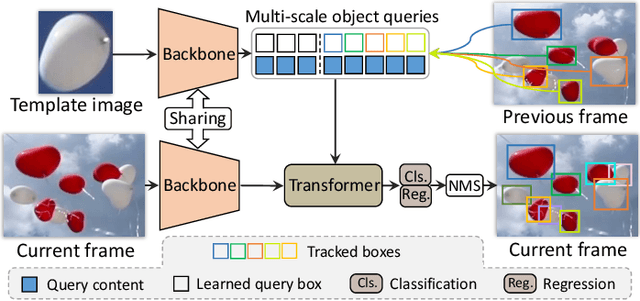
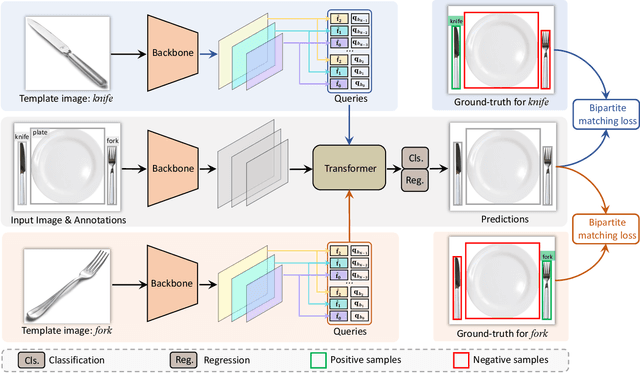
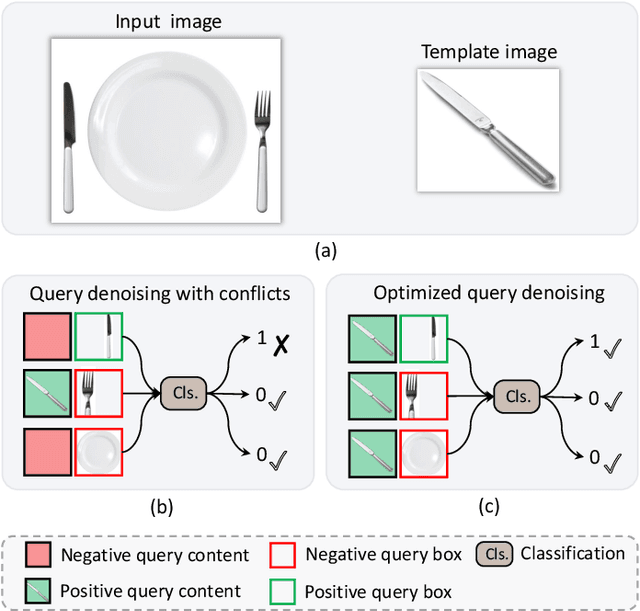

The ability to detect and track the dynamic objects in different scenes is fundamental to real-world applications, e.g., autonomous driving and robot navigation. However, traditional Multi-Object Tracking (MOT) is limited to tracking objects belonging to the pre-defined closed-set categories. Recently, Open-Vocabulary MOT (OVMOT) and Generic MOT (GMOT) are proposed to track interested objects beyond pre-defined categories with the given text prompt and template image. However, the expensive well pre-trained (vision-)language model and fine-grained category annotations are required to train OVMOT models. In this paper, we focus on GMOT and propose a simple but effective method, Siamese-DETR, for GMOT. Only the commonly used detection datasets (e.g., COCO) are required for training. Different from existing GMOT methods, which train a Single Object Tracking (SOT) based detector to detect interested objects and then apply a data association based MOT tracker to get the trajectories, we leverage the inherent object queries in DETR variants. Specifically: 1) The multi-scale object queries are designed based on the given template image, which are effective for detecting different scales of objects with the same category as the template image; 2) A dynamic matching training strategy is introduced to train Siamese-DETR on commonly used detection datasets, which takes full advantage of provided annotations; 3) The online tracking pipeline is simplified through a tracking-by-query manner by incorporating the tracked boxes in previous frame as additional query boxes. The complex data association is replaced with the much simpler Non-Maximum Suppression (NMS). Extensive experimental results show that Siamese-DETR surpasses existing MOT methods on GMOT-40 dataset by a large margin.
CS-PCN: Context-Space Progressive Collaborative Network for Image Denoising
May 17, 2023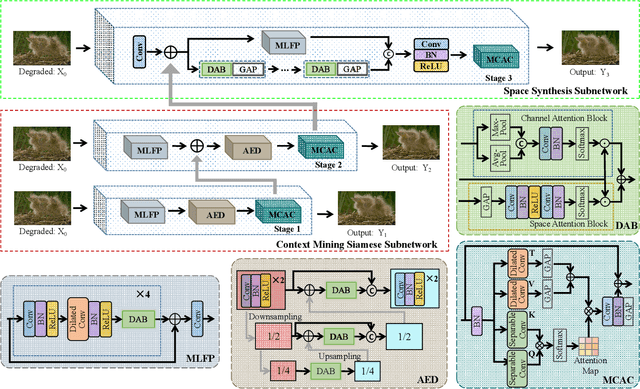



Currently, image-denoising methods based on deep learning cannot adequately reconcile contextual semantic information and spatial details. To take these information optimizations into consideration, in this paper, we propose a Context-Space Progressive Collaborative Network (CS-PCN) for image denoising. CS-PCN is a multi-stage hierarchical architecture composed of a context mining siamese sub-network (CM2S) and a space synthesis sub-network (3S). CM2S aims at extracting rich multi-scale contextual information by sequentially connecting multi-layer feature processors (MLFP) for semantic information pre-processing, attention encoder-decoders (AED) for multi-scale information, and multi-conv attention controllers (MCAC) for supervised feature fusion. 3S parallels MLFP and a single-scale cascading block to learn image details, which not only maintains the contextual information but also emphasizes the complementary spatial ones. Experimental results show that CS-PCN achieves significant performance improvement in synthetic and real-world noise removal.