 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 The First Challenge on Weather Removal in Videos
Apr 14, 2026This paper presents a review of the LoViF 2026 Challenge on Weather Removal in Videos. The challenge encourages the development of methods for restoring clean videos from inputs degraded by adverse weather conditions such as rain and snow, with an emphasis on achieving visually plausible and temporally consistent results while preserving scene structure and motion dynamics. To support this task, we introduce a new short-form WRV dataset tailored for video weather removal. It consists of 18 videos 1,216 synthesized frames paired with 1,216 real-world ground-truth frames at a resolution of 832 x 480, and is split into training, validation, and test sets with a ratio of 1:1:1. The goal of this challenge is to advance robust and realistic video restoration under real-world weather conditions, with evaluation protocols that jointly consider fidelity and perceptual quality. The challenge attracted 37 participants and received 5 valid final submissions with corresponding fact sheets, contributing to progress in weather removal for videos. The project is publicly available at https://www.codabench.org/competitions/13462/.
TransGP: Task-Conditioned Transformer-Guided Genetic Programming for Multitask Dynamic Flexible Job Shop Scheduling
Apr 04, 2026Hyper-heuristics have become a popular approach for solving dynamic flexible job shop scheduling (DFJSS) problems. They use gradient-free optimization techniques like Genetic Programming (GP) to evolve non-differentiable heuristics. However, conventional GP methods tend to converge slowly because they rely solely on evolutionary search to find good heuristics. Existing multitask GP methods can solve multiple tasks simultaneously and speed up the search by transferring knowledge across similar tasks. But they mostly exchange heuristic building blocks without truly generating heuristics conditioned on task information. In this paper, we aim to accelerate convergence and enable task-specific heuristic generation by incorporating a task-conditioned Transformer model. The Transformer works in two ways. First, it learns the distribution of elite heuristics, biasing the search toward promising regions of the heuristic space. Second, through conditional generation, it produces heuristics tailored to specific tasks, allowing the model to handle multiple scheduling tasks at once and improving overall optimization efficiency. Based on these ideas, we propose TransGP, a Task-Conditioned Transformer-Guided GP framework. This evolutionary paradigm integrates generative modeling with GP, enabling efficient multitask heuristic learning and knowledge transfer. We evaluate TransGP on a range of DFJSS scenarios. Experimental results show that TransGP consistently outperforms multitask GP baselines, widely used handcrafted heuristics, and the pure Transformer model, achieving faster convergence, superior solution quality, and enhanced robustness.
Finding Sets of Pareto Sets in Real-World Scenarios -- A Multitask Multiobjective Perspective
Apr 04, 2026Recently, evolutionary multitasking has been employed to generate a ``set of Pareto sets" (SOS) for machine learning models, addressing diverse task settings across heterogeneous environments. This involves creating a repository of compact, specialized solution models that are collectively tailored to each specific task setting and environment, enabling users to select the most suitable model based on particular specifications and preferences. In this paper, we further demonstrate the versatility and applicability of the SOS concept across diverse domains, focusing on three real-world problems: engineering design problems, inventory management problems, and hyperparameter optimization problems. Additionally, as evolutionary multitasking has proven effective in generating the SOS, we investigate the performance of current evolutionary multitasking methods on these real-world problems. Subsequently, we present visualizations of the generated SOS in both decision and objective spaces, complemented by the development of a measurement to gauge the similarity between different Pareto sets corresponding to diverse tasks. Finally, we show that by systematically examining the shifts in Pareto optimal designs across different task settings though the SOS solutions, users can gain deeper understandings on the dynamic interplay between design solutions and their performance in different settings or contexts.
Parametric Expensive Multi-Objective Optimization via Generative Solution Modeling
Nov 17, 2025Many real-world applications require solving families of expensive multi-objective optimization problems~(EMOPs) under varying operational conditions. This gives rise to parametric expensive multi-objective optimization problems (P-EMOPs) where each task parameter defines a distinct optimization instance. Current multi-objective Bayesian optimization methods have been widely used for finding finite sets of Pareto optimal solutions for individual tasks. However, P-EMOPs present a fundamental challenge: the continuous task parameter space can contain infinite distinct problems, each requiring separate expensive evaluations. This demands learning an inverse model that can directly predict optimized solutions for any task-preference query without expensive re-evaluation. This paper introduces the first parametric multi-objective Bayesian optimizer that learns this inverse model by alternating between (1) acquisition-driven search leveraging inter-task synergies and (2) generative solution sampling via conditional generative models. This approach enables efficient optimization across related tasks and finally achieves direct solution prediction for unseen parameterized EMOPs without additional expensive evaluations. We theoretically justify the faster convergence by leveraging inter-task synergies through task-aware Gaussian processes. Meanwhile, empirical studies in synthetic and real-world benchmarks further verify the effectiveness of our alternating framework.
NeuSpring: Neural Spring Fields for Reconstruction and Simulation of Deformable Objects from Videos
Nov 11, 2025In this paper, we aim to create physical digital twins of deformable objects under interaction. Existing methods focus more on the physical learning of current state modeling, but generalize worse to future prediction. This is because existing methods ignore the intrinsic physical properties of deformable objects, resulting in the limited physical learning in the current state modeling. To address this, we present NeuSpring, a neural spring field for the reconstruction and simulation of deformable objects from videos. Built upon spring-mass models for realistic physical simulation, our method consists of two major innovations: 1) a piecewise topology solution that efficiently models multi-region spring connection topologies using zero-order optimization, which considers the material heterogeneity of real-world objects. 2) a neural spring field that represents spring physical properties across different frames using a canonical coordinate-based neural network, which effectively leverages the spatial associativity of springs for physical learning. Experiments on real-world datasets demonstrate that our NeuSping achieves superior reconstruction and simulation performance for current state modeling and future prediction, with Chamfer distance improved by 20% and 25%, respectively.
($\boldsymbolθ_l, \boldsymbolθ_u$)-Parametric Multi-Task Optimization: Joint Search in Solution and Infinite Task Spaces
Mar 11, 2025
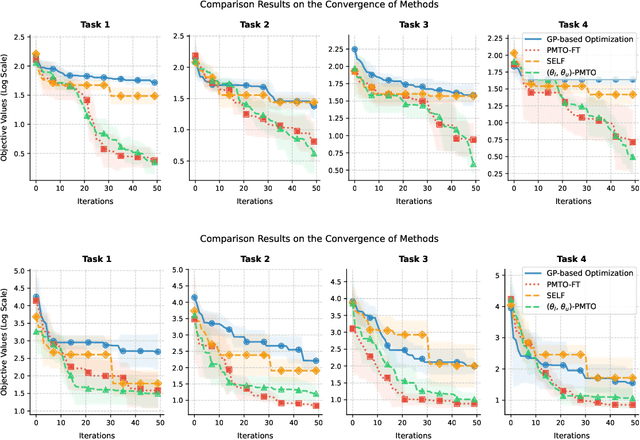


Multi-task optimization is typically characterized by a fixed and finite set of optimization tasks. The present paper relaxes this condition by considering a non-fixed and potentially infinite set of optimization tasks defined in a parameterized, continuous and bounded task space. We refer to this unique problem setting as parametric multi-task optimization (PMTO). Assuming the bounds of the task parameters to be ($\boldsymbol{\theta}_l$, $\boldsymbol{\theta}_u$), a novel ($\boldsymbol{\theta}_l$, $\boldsymbol{\theta}_u$)-PMTO algorithm is crafted to enable joint search over tasks and their solutions. This joint search is supported by two approximation models: (1) for mapping solutions to the objective spaces of all tasks, which provably accelerates convergence by acting as a conduit for inter-task knowledge transfers, and (2) for probabilistically mapping tasks to the solution space, which facilitates evolutionary exploration of under-explored regions of the task space. At the end of a full ($\boldsymbol{\theta}_l$, $\boldsymbol{\theta}_u$)-PMTO run, the acquired models enable rapid identification of optimized solutions for any task lying within the specified bounds. This outcome is validated on both synthetic test problems and practical case studies, with the significant real-world applicability of PMTO shown towards fast reconfiguration of robot controllers under changing task conditions. The potential of PMTO to vastly speedup the search for solutions to minimax optimization problems is also demonstrated through an example in robust engineering design.
Gungnir: Exploiting Stylistic Features in Images for Backdoor Attacks on Diffusion Models
Feb 28, 2025In recent years, Diffusion Models (DMs) have demonstrated significant advances in the field of image generation. However, according to current research, DMs are vulnerable to backdoor attacks, which allow attackers to control the model's output by inputting data containing covert triggers, such as a specific patch or phrase. Existing defense strategies are well equipped to thwart such attacks through backdoor detection and trigger inversion because previous attack methods are constrained by limited input spaces and triggers defined by low-dimensional features. To bridge these gaps, we propose Gungnir, a novel method that enables attackers to activate the backdoor in DMs through hidden style triggers within input images. Our approach proposes using stylistic features as triggers for the first time and implements backdoor attacks successfully in image2image tasks by utilizing Reconstructing-Adversarial Noise (RAN) and Short-Term-Timesteps-Retention (STTR) of DMs. Meanwhile, experiments demonstrate that our method can easily bypass existing defense methods. Among existing DM main backdoor defense frameworks, our approach achieves a 0\% backdoor detection rate (BDR). Our codes are available at https://github.com/paoche11/Gungnir.
Physics-Informed Neuro-Evolution (PINE): A Survey and Prospects
Jan 11, 2025Deep learning models trained on finite data lack a complete understanding of the physical world. On the other hand, physics-informed neural networks (PINNs) are infused with such knowledge through the incorporation of mathematically expressible laws of nature into their training loss function. By complying with physical laws, PINNs provide advantages over purely data-driven models in limited-data regimes. This feature has propelled them to the forefront of scientific machine learning, a domain characterized by scarce and costly data. However, the vision of accurate physics-informed learning comes with significant challenges. This review examines PINNs for the first time in terms of model optimization and generalization, shedding light on the need for new algorithmic advances to overcome issues pertaining to the training speed, precision, and generalizability of today's PINN models. Of particular interest are the gradient-free methods of neuroevolution for optimizing the uniquely complex loss landscapes arising in PINN training. Methods synergizing gradient descent and neuroevolution for discovering bespoke neural architectures and balancing multiple conflicting terms in physics-informed learning objectives are positioned as important avenues for future research. Yet another exciting track is to cast neuroevolution as a meta-learner of generalizable PINN models.
Language Model Evolutionary Algorithms for Recommender Systems: Benchmarks and Algorithm Comparisons
Nov 16, 2024
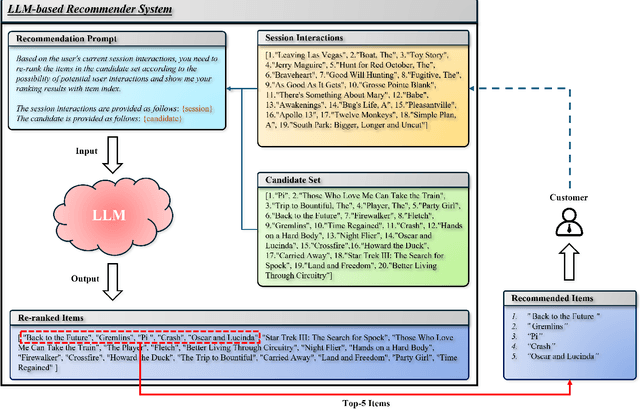


In the evolutionary computing community, the remarkable language-handling capabilities and reasoning power of large language models (LLMs) have significantly enhanced the functionality of evolutionary algorithms (EAs), enabling them to tackle optimization problems involving structured language or program code. Although this field is still in its early stages, its impressive potential has led to the development of various LLM-based EAs. To effectively evaluate the performance and practical applicability of these LLM-based EAs, benchmarks with real-world relevance are essential. In this paper, we focus on LLM-based recommender systems (RSs) and introduce a benchmark problem set, named RSBench, specifically designed to assess the performance of LLM-based EAs in recommendation prompt optimization. RSBench emphasizes session-based recommendations, aiming to discover a set of Pareto optimal prompts that guide the recommendation process, providing accurate, diverse, and fair recommendations. We develop three LLM-based EAs based on established EA frameworks and experimentally evaluate their performance using RSBench. Our study offers valuable insights into the application of EAs in LLM-based RSs. Additionally, we explore key components that may influence the overall performance of the RS, providing meaningful guidance for future research on the development of LLM-based EAs in RSs.
LLM2FEA: Discover Novel Designs with Generative Evolutionary Multitasking
Jun 21, 2024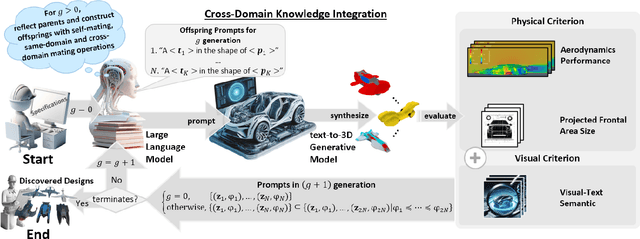
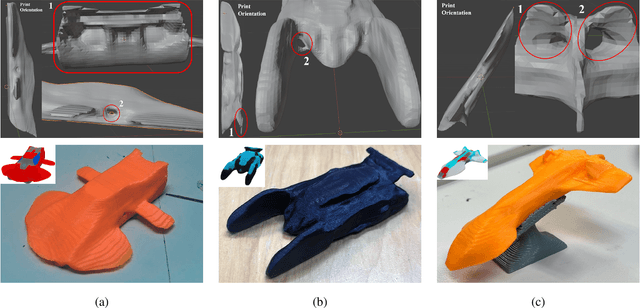
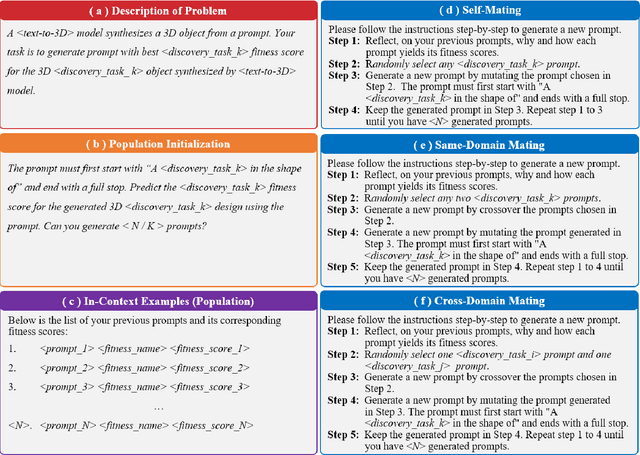

The rapid research and development of generative artificial intelligence has enabled the generation of high-quality images, text, and 3D models from text prompts. This advancement impels an inquiry into whether these models can be leveraged to create digital artifacts for both creative and engineering applications. Drawing on innovative designs from other domains may be one answer to this question, much like the historical practice of ``bionics", where humans have sought inspiration from nature's exemplary designs. This raises the intriguing possibility of using generative models to simultaneously tackle design tasks across multiple domains, facilitating cross-domain learning and resulting in a series of innovative design solutions. In this paper, we propose LLM2FEA as the first attempt to discover novel designs in generative models by transferring knowledge across multiple domains. By utilizing a multi-factorial evolutionary algorithm (MFEA) to drive a large language model, LLM2FEA integrates knowledge from various fields to generate prompts that guide the generative model in discovering novel and practical objects. Experimental results in the context of 3D aerodynamic design verify the discovery capabilities of the proposed LLM2FEA. The designs generated by LLM2FEA not only satisfy practicality requirements to a certain degree but also feature novel and aesthetically pleasing shapes, demonstrating the potential applications of LLM2FEA in discovery tasks.