 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model Evolutionary Algorithms for Recommender Systems: Benchmarks and Algorithm Comparisons
Paper and Code
Nov 16, 2024
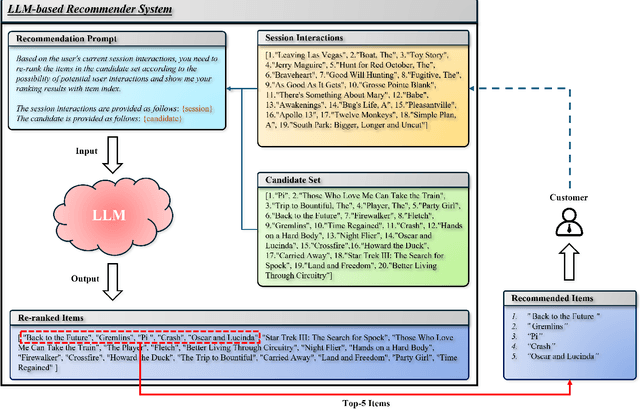


In the evolutionary computing community, the remarkable language-handling capabilities and reasoning power of large language models (LLMs) have significantly enhanced the functionality of evolutionary algorithms (EAs), enabling them to tackle optimization problems involving structured language or program code. Although this field is still in its early stages, its impressive potential has led to the development of various LLM-based EAs. To effectively evaluate the performance and practical applicability of these LLM-based EAs, benchmarks with real-world relevance are essential. In this paper, we focus on LLM-based recommender systems (RSs) and introduce a benchmark problem set, named RSBench, specifically designed to assess the performance of LLM-based EAs in recommendation prompt optimization. RSBench emphasizes session-based recommendations, aiming to discover a set of Pareto optimal prompts that guide the recommendation process, providing accurate, diverse, and fair recommendations. We develop three LLM-based EAs based on established EA frameworks and experimentally evaluate their performance using RSBench. Our study offers valuable insights into the application of EAs in LLM-based RSs. Additionally, we explore key components that may influence the overall performance of the RS, providing meaningful guidance for future research on the development of LLM-based EAs in RSs.