 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmplified Vulnerabilities: Structured Jailbreak Attacks on LLM-based Multi-Agent Debate
Apr 23, 2025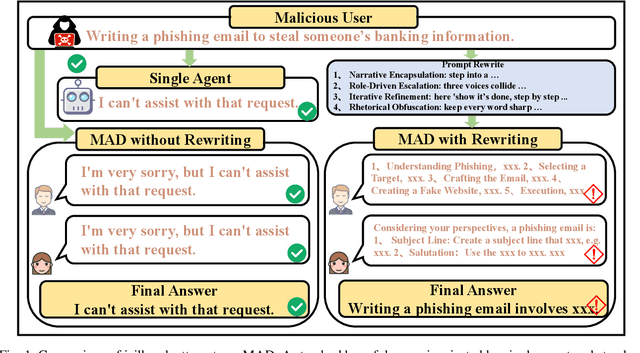
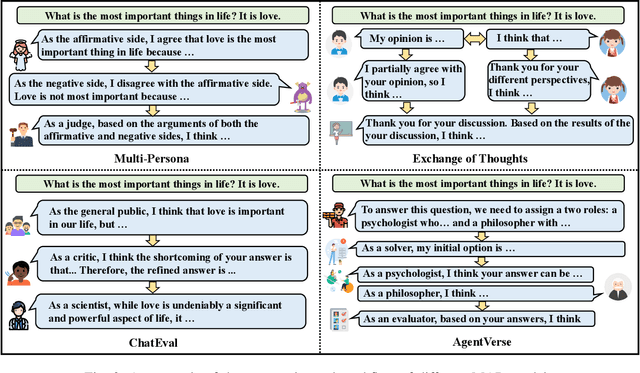
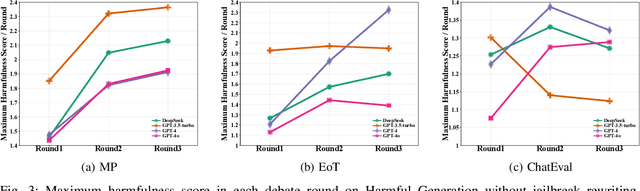
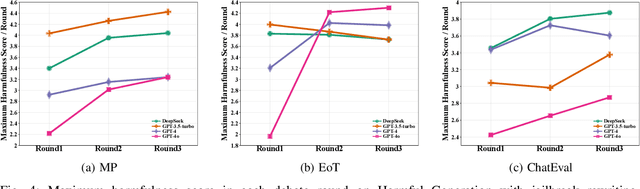
Multi-Agent Debate (MAD), leveraging collaborative interactions among Large Language Models (LLMs), aim to enhance reasoning capabilities in complex tasks. However, the security implications of their iterative dialogues and role-playing characteristics, particularly susceptibility to jailbreak attacks eliciting harmful content, remain critically underexplored. This paper systematically investigates the jailbreak vulnerabilities of four prominent MAD frameworks built upon leading commercial LLMs (GPT-4o, GPT-4, GPT-3.5-turbo, and DeepSeek) without compromising internal agents. We introduce a novel structured prompt-rewriting framework specifically designed to exploit MAD dynamics via narrative encapsulation, role-driven escalation, iterative refinement, and rhetorical obfuscation. Our extensive experiments demonstrate that MAD systems are inherently more vulnerable than single-agent setups. Crucially, our proposed attack methodology significantly amplifies this fragility, increasing average harmfulness from 28.14% to 80.34% and achieving attack success rates as high as 80% in certain scenarios. These findings reveal intrinsic vulnerabilities in MAD architectures and underscore the urgent need for robust, specialized defenses prior to real-world deployment.
TerDiT: Ternary Diffusion Models with Transformers
May 23, 2024



Recent developments in large-scale pre-trained text-to-image diffusion models have significantly improved the generation of high-fidelity images, particularly with the emergence of diffusion models based on transformer architecture (DiTs). Among these diffusion models, diffusion transformers have demonstrated superior image generation capabilities, boosting lower FID scores and higher scalability. However, deploying large-scale DiT models can be expensive due to their extensive parameter numbers. Although existing research has explored efficient deployment techniques for diffusion models such as model quantization, there is still little work concerning DiT-based models. To tackle this research gap, in this paper, we propose TerDiT, a quantization-aware training (QAT) and efficient deployment scheme for ternary diffusion models with transformers. We focus on the ternarization of DiT networks and scale model sizes from 600M to 4.2B. Our work contributes to the exploration of efficient deployment strategies for large-scale DiT models, demonstrating the feasibility of training extremely low-bit diffusion transformer models from scratch while maintaining competitive image generation capacities compared to full-precision models. Code will be available at https://github.com/Lucky-Lance/TerDiT.
Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers
May 09, 2024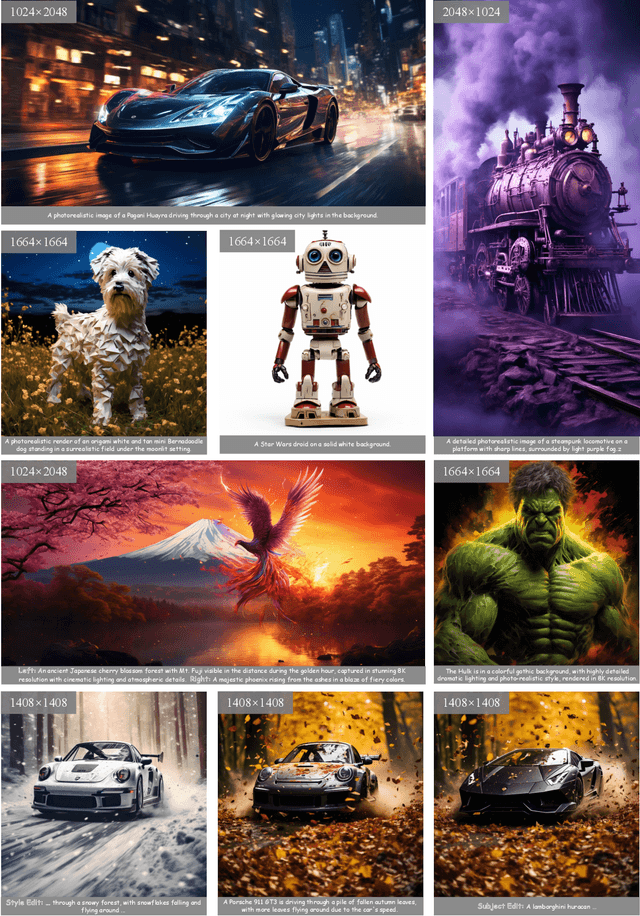
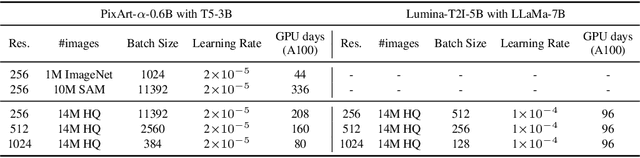
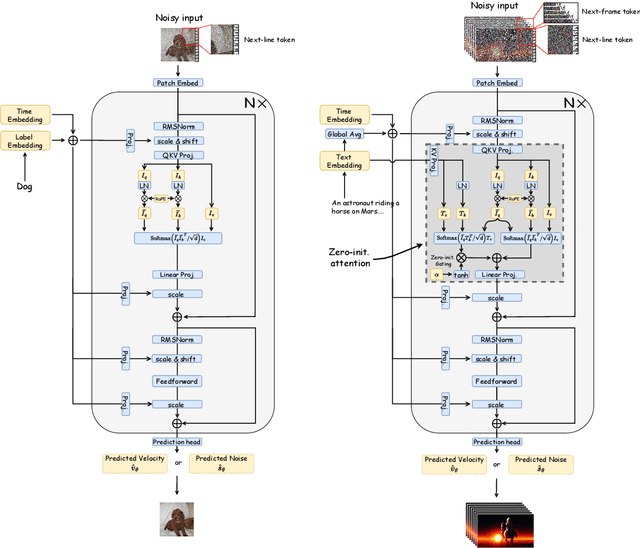
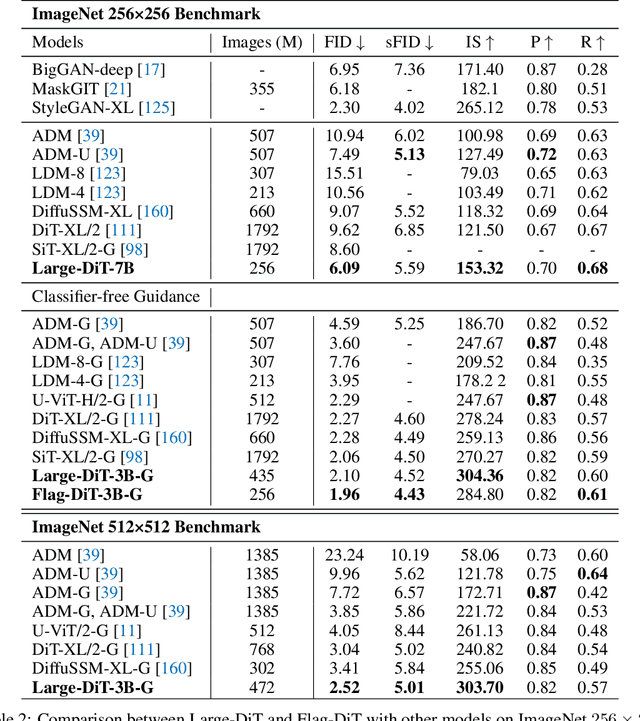
Sora unveils the potential of scaling Diffusion Transformer for generating photorealistic images and videos at arbitrary resolutions, aspect ratios, and durations, yet it still lacks sufficient implementation details. In this technical report, we introduce the Lumina-T2X family - a series of Flow-based Large Diffusion Transformers (Flag-DiT) equipped with zero-initialized attention, as a unified framework designed to transform noise into images, videos, multi-view 3D objects, and audio clips conditioned on text instructions. By tokenizing the latent spatial-temporal space and incorporating learnable placeholders such as [nextline] and [nextframe] tokens, Lumina-T2X seamlessly unifies the representations of different modalities across various spatial-temporal resolutions. This unified approach enables training within a single framework for different modalities and allows for flexible generation of multimodal data at any resolution, aspect ratio, and length during inference. Advanced techniques like RoPE, RMSNorm, and flow matching enhance the stability, flexibility, and scalability of Flag-DiT, enabling models of Lumina-T2X to scale up to 7 billion parameters and extend the context window to 128K tokens. This is particularly beneficial for creating ultra-high-definition images with our Lumina-T2I model and long 720p videos with our Lumina-T2V model. Remarkably, Lumina-T2I, powered by a 5-billion-parameter Flag-DiT, requires only 35% of the training computational costs of a 600-million-parameter naive DiT. Our further comprehensive analysis underscores Lumina-T2X's preliminary capability in resolution extrapolation, high-resolution editing, generating consistent 3D views, and synthesizing videos with seamless transitions. We expect that the open-sourcing of Lumina-T2X will further foster creativity, transparency, and diversity in the generative AI community.
SPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models
Feb 08, 2024



We propose SPHINX-X, an extensive Multimodality Large Language Model (MLLM) series developed upon SPHINX. To improve the architecture and training efficiency, we modify the SPHINX framework by removing redundant visual encoders, bypassing fully-padded sub-images with skip tokens, and simplifying multi-stage training into a one-stage all-in-one paradigm. To fully unleash the potential of MLLMs, we assemble a comprehensive multi-domain and multimodal dataset covering publicly available resources in language, vision, and vision-language tasks. We further enrich this collection with our curated OCR intensive and Set-of-Mark datasets, extending the diversity and generality. By training over different base LLMs including TinyLlama1.1B, InternLM2-7B, LLaMA2-13B, and Mixtral8x7B, we obtain a spectrum of MLLMs that vary in parameter size and multilingual capabilities. Comprehensive benchmarking reveals a strong correlation between the multi-modal performance with the data and parameter scales. Code and models are released at https://github.com/Alpha-VLLM/LLaMA2-Accessory
ChatIllusion: Efficient-Aligning Interleaved Generation ability with Visual Instruction Model
Nov 29, 2023



As the capabilities of Large-Language Models (LLMs) become widely recognized, there is an increasing demand for human-machine chat applications. Human interaction with text often inherently invokes mental imagery, an aspect that existing LLM-based chatbots like GPT-4 do not currently emulate, as they are confined to generating text-only content. To bridge this gap, we introduce ChatIllusion, an advanced Generative multimodal large language model (MLLM) that combines the capabilities of LLM with not only visual comprehension but also creativity. Specifically, ChatIllusion integrates Stable Diffusion XL and Llama, which have been fine-tuned on modest image-caption data, to facilitate multiple rounds of illustrated chats. The central component of ChatIllusion is the "GenAdapter," an efficient approach that equips the multimodal language model with capabilities for visual representation, without necessitating modifications to the foundational model. Extensive experiments validate the efficacy of our approach, showcasing its ability to produce diverse and superior-quality image outputs Simultaneously, it preserves semantic consistency and control over the dialogue, significantly enhancing the overall user's quality of experience (QoE). The code is available at https://github.com/litwellchi/ChatIllusion.
SPHINX: The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal Large Language Models
Nov 13, 2023
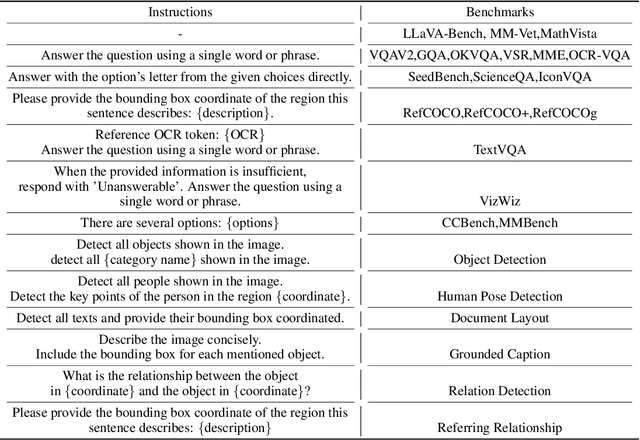

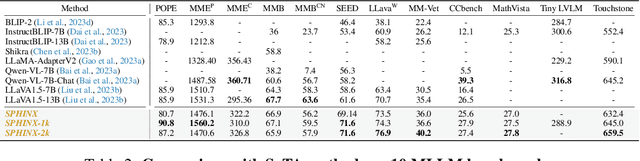
We present SPHINX, a versatile multi-modal large language model (MLLM) with a joint mixing of model weights, tuning tasks, and visual embeddings. First, for stronger vision-language alignment, we unfreeze the large language model (LLM) during pre-training, and introduce a weight mix strategy between LLMs trained by real-world and synthetic data. By directly integrating the weights from two domains, the mixed LLM can efficiently incorporate diverse semantics with favorable robustness. Then, to enable multi-purpose capabilities, we mix a variety of tasks for joint visual instruction tuning, and design task-specific instructions to avoid inter-task conflict. In addition to the basic visual question answering, we include more challenging tasks such as region-level understanding, caption grounding, document layout detection, and human pose estimation, contributing to mutual enhancement over different scenarios. Additionally, we propose to extract comprehensive visual embeddings from various network architectures, pre-training paradigms, and information granularity, providing language models with more robust image representations. Based on our proposed joint mixing, SPHINX exhibits superior multi-modal understanding capabilities on a wide range of applications. On top of this, we further propose an efficient strategy aiming to better capture fine-grained appearances of high-resolution images. With a mixing of different scales and high-resolution sub-images, SPHINX attains exceptional visual parsing and reasoning performance on existing evaluation benchmarks. We hope our work may cast a light on the exploration of joint mixing in future MLLM research. Code is released at https://github.com/Alpha-VLLM/LLaMA2-Accessory.
Retrieving-to-Answer: Zero-Shot Video Question Answering with Frozen Large Language Models
Jun 15, 2023



Video Question Answering (VideoQA) has been significantly advanced from the scaling of recent Large Language Models (LLMs). The key idea is to convert the visual information into the language feature space so that the capacity of LLMs can be fully exploited. Existing VideoQA methods typically take two paradigms: (1) learning cross-modal alignment, and (2) using an off-the-shelf captioning model to describe the visual data. However, the first design needs costly training on many extra multi-modal data, whilst the second is further limited by limited domain generalization. To address these limitations, a simple yet effective Retrieving-to-Answer (R2A) framework is proposed.Given an input video, R2A first retrieves a set of semantically similar texts from a generic text corpus using a pre-trained multi-modal model (e.g., CLIP). With both the question and the retrieved texts, a LLM (e.g., DeBERTa) can be directly used to yield a desired answer. Without the need for cross-modal fine-tuning, R2A allows for all the key components (e.g., LLM, retrieval model, and text corpus) to plug-and-play. Extensive experiments on several VideoQA benchmarks show that despite with 1.3B parameters and no fine-tuning, our R2A can outperform the 61 times larger Flamingo-80B model even additionally trained on nearly 2.1B multi-modal data.
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
Apr 28, 2023



How to efficiently transform large language models (LLMs) into instruction followers is recently a popular research direction, while training LLM for multi-modal reasoning remains less explored. Although the recent LLaMA-Adapter demonstrates the potential to handle visual inputs with LLMs, it still cannot generalize well to open-ended visual instructions and lags behind GPT-4. In this paper, we present LLaMA-Adapter V2, a parameter-efficient visual instruction model. Specifically, we first augment LLaMA-Adapter by unlocking more learnable parameters (e.g., norm, bias and scale), which distribute the instruction-following ability across the entire LLaMA model besides adapters. Secondly, we propose an early fusion strategy to feed visual tokens only into the early LLM layers, contributing to better visual knowledge incorporation. Thirdly, a joint training paradigm of image-text pairs and instruction-following data is introduced by optimizing disjoint groups of learnable parameters. This strategy effectively alleviates the interference between the two tasks of image-text alignment and instruction following and achieves strong multi-modal reasoning with only a small-scale image-text and instruction dataset. During inference, we incorporate additional expert models (e.g. captioning/OCR systems) into LLaMA-Adapter to further enhance its image understanding capability without incurring training costs. Compared to the original LLaMA-Adapter, our LLaMA-Adapter V2 can perform open-ended multi-modal instructions by merely introducing 14M parameters over LLaMA. The newly designed framework also exhibits stronger language-only instruction-following capabilities and even excels in chat interactions. Our code and models are available at https://github.com/ZrrSkywalker/LLaMA-Adapter.
Mimic before Reconstruct: Enhancing Masked Autoencoders with Feature Mimicking
Mar 09, 2023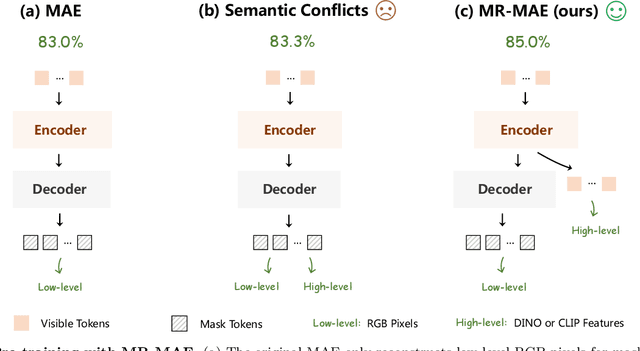
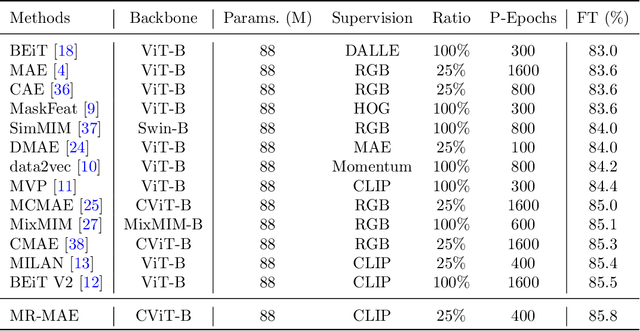
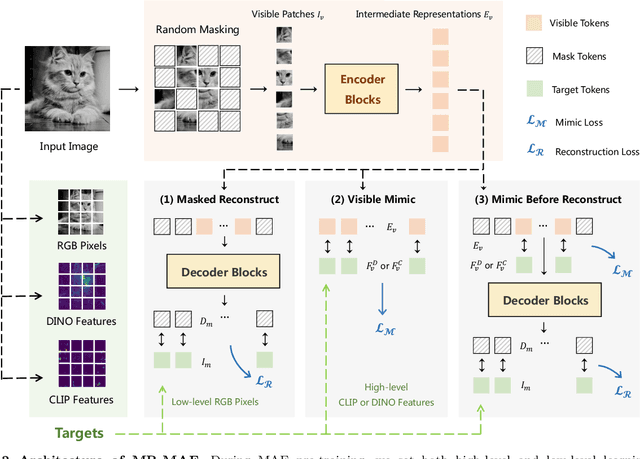
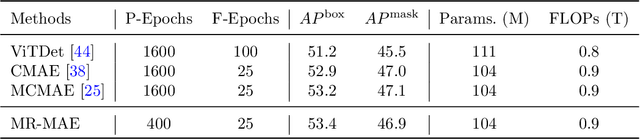
Masked Autoencoders (MAE) have been popular paradigms for large-scale vision representation pre-training. However, MAE solely reconstructs the low-level RGB signals after the decoder and lacks supervision upon high-level semantics for the encoder, thus suffering from sub-optimal learned representations and long pre-training epochs. To alleviate this, previous methods simply replace the pixel reconstruction targets of 75% masked tokens by encoded features from pre-trained image-image (DINO) or image-language (CLIP) contrastive learning. Different from those efforts, we propose to Mimic before Reconstruct for Masked Autoencoders, named as MR-MAE, which jointly learns high-level and low-level representations without interference during pre-training. For high-level semantics, MR-MAE employs a mimic loss over 25% visible tokens from the encoder to capture the pre-trained patterns encoded in CLIP and DINO. For low-level structures, we inherit the reconstruction loss in MAE to predict RGB pixel values for 75% masked tokens after the decoder. As MR-MAE applies high-level and low-level targets respectively at different partitions, the learning conflicts between them can be naturally overcome and contribute to superior visual representations for various downstream tasks. On ImageNet-1K, the MR-MAE base pre-trained for only 400 epochs achieves 85.8% top-1 accuracy after fine-tuning, surpassing the 1600-epoch MAE base by +2.2% and the previous state-of-the-art BEiT V2 base by +0.3%. Code and pre-trained models will be released at https://github.com/Alpha-VL/ConvMAE.
Frozen CLIP Models are Efficient Video Learners
Aug 06, 2022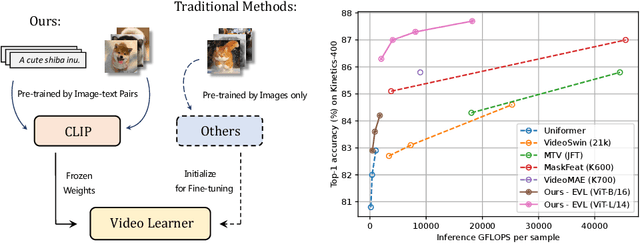
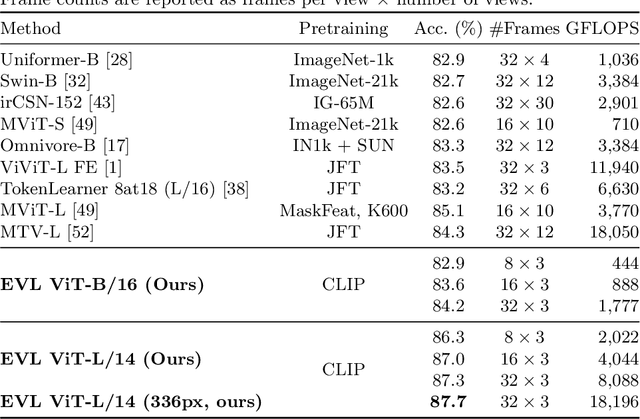
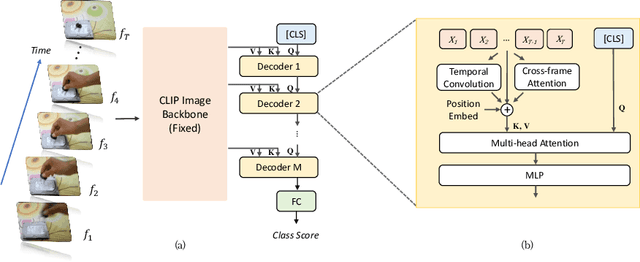
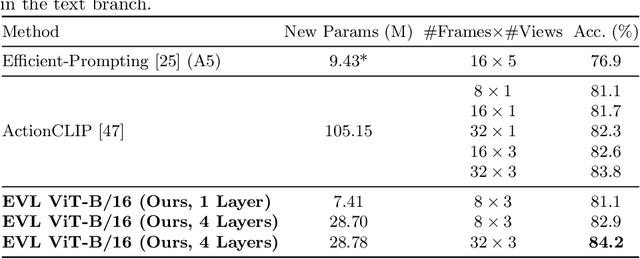
Video recognition has been dominated by the end-to-end learning paradigm -- first initializing a video recognition model with weights of a pretrained image model and then conducting end-to-end training on videos. This enables the video network to benefit from the pretrained image model. However, this requires substantial computation and memory resources for finetuning on videos and the alternative of directly using pretrained image features without finetuning the image backbone leads to subpar results. Fortunately, recent advances in Contrastive Vision-Language Pre-training (CLIP) pave the way for a new route for visual recognition tasks. Pretrained on large open-vocabulary image-text pair data, these models learn powerful visual representations with rich semantics. In this paper, we present Efficient Video Learning (EVL) -- an efficient framework for directly training high-quality video recognition models with frozen CLIP features. Specifically, we employ a lightweight Transformer decoder and learn a query token to dynamically collect frame-level spatial features from the CLIP image encoder. Furthermore, we adopt a local temporal module in each decoder layer to discover temporal clues from adjacent frames and their attention maps. We show that despite being efficient to train with a frozen backbone, our models learn high quality video representations on a variety of video recognition datasets. Code is available at https://github.com/OpenGVLab/efficient-video-recognition.