 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQAP-VLA: A Synergistic Quantization-Aware Pruning Framework for High-Performance Vision-Language-Action Models
Sep 11, 2025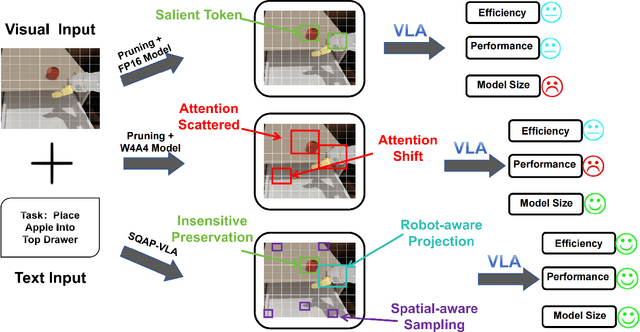
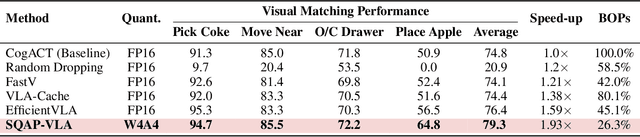
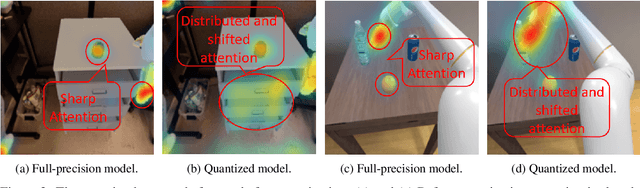
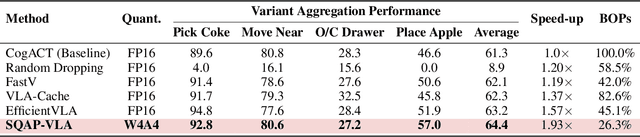
Vision-Language-Action (VLA) models exhibit unprecedented capabilities for embodied intelligence. However, their extensive computational and memory costs hinder their practical deployment. Existing VLA compression and acceleration approaches conduct quantization or token pruning in an ad-hoc manner but fail to enable both for a holistic efficiency improvement due to an observed incompatibility. This work introduces SQAP-VLA, the first structured, training-free VLA inference acceleration framework that simultaneously enables state-of-the-art quantization and token pruning. We overcome the incompatibility by co-designing the quantization and token pruning pipeline, where we propose new quantization-aware token pruning criteria that work on an aggressively quantized model while improving the quantizer design to enhance pruning effectiveness. When applied to standard VLA models, SQAP-VLA yields significant gains in computational efficiency and inference speed while successfully preserving core model performance, achieving a $\times$1.93 speedup and up to a 4.5\% average success rate enhancement compared to the original model.
PAT: Pruning-Aware Tuning for Large Language Models
Aug 27, 2024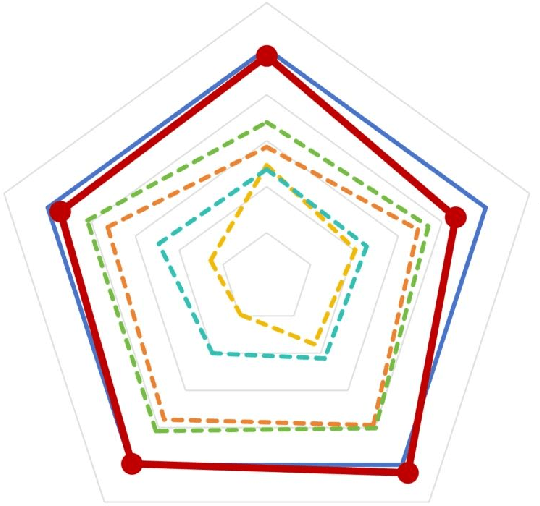
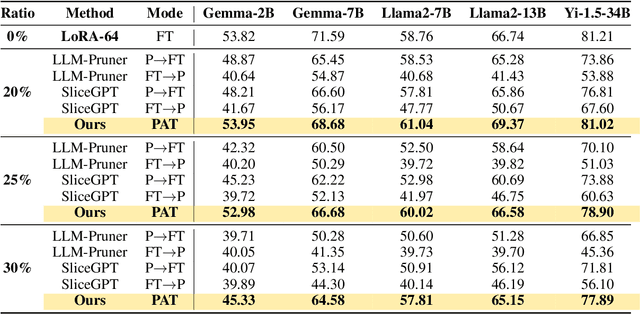
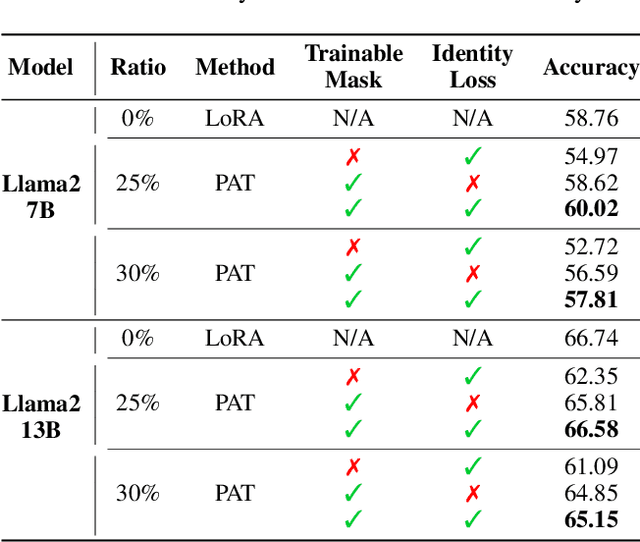
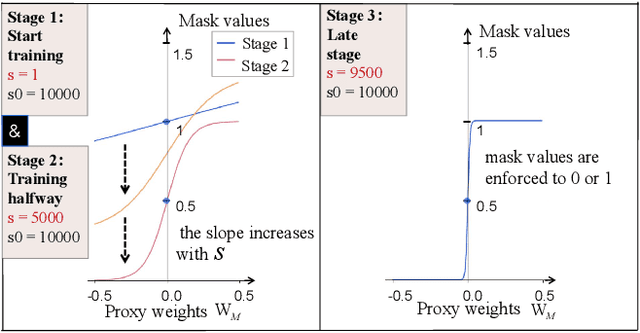
Large language models (LLMs) excel in language tasks, especially with supervised fine-tuning after pre-training. However, their substantial memory and computational requirements hinder practical applications. Structural pruning, which reduces less significant weight dimensions, is one solution. Yet, traditional post-hoc pruning often leads to significant performance loss, with limited recovery from further fine-tuning due to reduced capacity. Since the model fine-tuning refines the general and chaotic knowledge in pre-trained models, we aim to incorporate structural pruning with the fine-tuning, and propose the Pruning-Aware Tuning (PAT) paradigm to eliminate model redundancy while preserving the model performance to the maximum extend. Specifically, we insert the innovative Hybrid Sparsification Modules (HSMs) between the Attention and FFN components to accordingly sparsify the upstream and downstream linear modules. The HSM comprises a lightweight operator and a globally shared trainable mask. The lightweight operator maintains a training overhead comparable to that of LoRA, while the trainable mask unifies the channels to be sparsified, ensuring structural pruning. Additionally, we propose the Identity Loss which decouples the transformation and scaling properties of the HSMs to enhance training robustness. Extensive experiments demonstrate that PAT excels in both performance and efficiency. For example, our Llama2-7b model with a 25\% pruning ratio achieves 1.33$\times$ speedup while outperforming the LoRA-finetuned model by up to 1.26\% in accuracy with a similar training cost. Code: https://github.com/kriskrisliu/PAT_Pruning-Aware-Tuning
Intuition-aware Mixture-of-Rank-1-Experts for Parameter Efficient Finetuning
Apr 13, 2024



Large Language Models (LLMs) have demonstrated significant potential in performing multiple tasks in multimedia applications, ranging from content generation to interactive entertainment, and artistic creation. However, the diversity of downstream tasks in multitask scenarios presents substantial adaptation challenges for LLMs. While traditional methods often succumb to knowledge confusion on their monolithic dense models, Mixture-of-Experts (MoE) has been emerged as a promising solution with its sparse architecture for effective task decoupling. Inspired by the principles of human cognitive neuroscience, we design a novel framework \texttt{Intuition-MoR1E} that leverages the inherent semantic clustering of instances to mimic the human brain to deal with multitask, offering implicit guidance to router for optimized feature allocation. Moreover, we introduce cutting-edge Rank-1 Experts formulation designed to manage a spectrum of intuitions, demonstrating enhanced parameter efficiency and effectiveness in multitask LLM finetuning. Extensive experiments demonstrate that Intuition-MoR1E achieves superior efficiency and 2.15\% overall accuracy improvement across 14 public datasets against other state-of-the-art baselines.
Cloud-Device Collaborative Learning for Multimodal Large Language Models
Dec 26, 2023



The burgeoning field of Multimodal Large Language Models (MLLMs) has exhibited remarkable performance in diverse tasks such as captioning, commonsense reasoning, and visual scene understanding. However, the deployment of these large-scale MLLMs on client devices is hindered by their extensive model parameters, leading to a notable decline in generalization capabilities when these models are compressed for device deployment. Addressing this challenge, we introduce a Cloud-Device Collaborative Continual Adaptation framework, designed to enhance the performance of compressed, device-deployed MLLMs by leveraging the robust capabilities of cloud-based, larger-scale MLLMs. Our framework is structured into three key components: a device-to-cloud uplink for efficient data transmission, cloud-based knowledge adaptation, and an optimized cloud-to-device downlink for model deployment. In the uplink phase, we employ an Uncertainty-guided Token Sampling (UTS) strategy to effectively filter out-of-distribution tokens, thereby reducing transmission costs and improving training efficiency. On the cloud side, we propose Adapter-based Knowledge Distillation (AKD) method to transfer refined knowledge from large-scale to compressed, pocket-size MLLMs. Furthermore, we propose a Dynamic Weight update Compression (DWC) strategy for the downlink, which adaptively selects and quantizes updated weight parameters, enhancing transmission efficiency and reducing the representational disparity between cloud and device models. Extensive experiments on several multimodal benchmarks demonstrate the superiority of our proposed framework over prior Knowledge Distillation and device-cloud collaboration methods. Notably, we also validate the feasibility of our approach to real-world experiments.
ChatIllusion: Efficient-Aligning Interleaved Generation ability with Visual Instruction Model
Nov 29, 2023



As the capabilities of Large-Language Models (LLMs) become widely recognized, there is an increasing demand for human-machine chat applications. Human interaction with text often inherently invokes mental imagery, an aspect that existing LLM-based chatbots like GPT-4 do not currently emulate, as they are confined to generating text-only content. To bridge this gap, we introduce ChatIllusion, an advanced Generative multimodal large language model (MLLM) that combines the capabilities of LLM with not only visual comprehension but also creativity. Specifically, ChatIllusion integrates Stable Diffusion XL and Llama, which have been fine-tuned on modest image-caption data, to facilitate multiple rounds of illustrated chats. The central component of ChatIllusion is the "GenAdapter," an efficient approach that equips the multimodal language model with capabilities for visual representation, without necessitating modifications to the foundational model. Extensive experiments validate the efficacy of our approach, showcasing its ability to produce diverse and superior-quality image outputs Simultaneously, it preserves semantic consistency and control over the dialogue, significantly enhancing the overall user's quality of experience (QoE). The code is available at https://github.com/litwellchi/ChatIllusion.
Q-Diffusion: Quantizing Diffusion Models
Feb 10, 2023



Diffusion models have achieved great success in synthesizing diverse and high-fidelity images. However, sampling speed and memory constraints remain a major barrier to the practical adoption of diffusion models, since the generation process for these models can be slow due to the need for iterative noise estimation using compute-intensive neural networks. We propose to tackle this problem by compressing the noise estimation network to accelerate the generation process through post-training quantization (PTQ). While existing PTQ approaches have not been able to effectively deal with the changing output distributions of noise estimation networks in diffusion models over multiple time steps, we are able to formulate a PTQ method that is specifically designed to handle the unique multi-timestep structure of diffusion models with a data calibration scheme using data sampled from different time steps. Experimental results show that our proposed method is able to directly quantize full-precision diffusion models into 8-bit or 4-bit models while maintaining comparable performance in a training-free manner, achieving a FID change of at most 1.88. Our approach can also be applied to text-guided image generation, and for the first time we can run stable diffusion in 4-bit weights without losing much perceptual quality, as shown in Figure 5 and Figure 9.
NoisyQuant: Noisy Bias-Enhanced Post-Training Activation Quantization for Vision Transformers
Nov 29, 2022The complicated architecture and high training cost of vision transformers urge the exploration of post-training quantization. However, the heavy-tailed distribution of vision transformer activations hinders the effectiveness of previous post-training quantization methods, even with advanced quantizer designs. Instead of tuning the quantizer to better fit the complicated activation distribution, this paper proposes NoisyQuant, a quantizer-agnostic enhancement for the post-training activation quantization performance of vision transformers. We make a surprising theoretical discovery that for a given quantizer, adding a fixed Uniform noisy bias to the values being quantized can significantly reduce the quantization error under provable conditions. Building on the theoretical insight, NoisyQuant achieves the first success on actively altering the heavy-tailed activation distribution with additive noisy bias to fit a given quantizer. Extensive experiments show NoisyQuant largely improves the post-training quantization performance of vision transformer with minimal computation overhead. For instance, on linear uniform 6-bit activation quantization, NoisyQuant improves SOTA top-1 accuracy on ImageNet by up to 1.7%, 1.1% and 0.5% for ViT, DeiT, and Swin Transformer respectively, achieving on-par or even higher performance than previous nonlinear, mixed-precision quantization.
DiaASQ : A Benchmark of Conversational Aspect-based Sentiment Quadruple Analysis
Nov 20, 2022



The rapid development of aspect-based sentiment analysis (ABSA) within recent decades shows great potential for real-world society. The current ABSA works, however, are mostly limited to the scenario of a single text piece, leaving the study in dialogue contexts unexplored. In this work, we introduce a novel task of conversational aspect-based sentiment quadruple analysis, namely DiaASQ, aiming to detect the sentiment quadruple of \emph{target-aspect-opinion-sentiment} in a dialogue. DiaASQ bridges the gap between fine-grained sentiment analysis and conversational opinion mining. We manually construct a large-scale high-quality DiaASQ dataset in both Chinese and English languages. We deliberately develop a neural model to benchmark the task, which advances in effectively performing end-to-end quadruple prediction, and manages to incorporate rich dialogue-specific and discourse feature representations for better cross-utterance quadruple extraction. We finally point out several potential future works to facilitate the follow-up research of this new task.
End to End Chinese Lexical Fusion Recognition with Sememe Knowledge
Apr 11, 2020
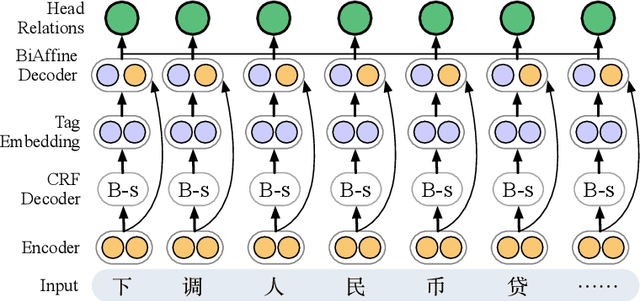


In this paper, we present Chinese lexical fusion recognition, a new task which could be regarded as one kind of coreference recognition. First, we introduce the task in detail, showing the relationship with coreference recognition and differences from the existing tasks. Second, we propose an end-to-end joint model for the task, which exploits the state-of-the-art BERT representations as encoder, and is further enhanced with the sememe knowledge from HowNet by graph attention networks. We manually annotate a benchmark dataset for the task and then conduct experiments on it. Results demonstrate that our joint model is effective and competitive for the task. Detailed analysis is offered for comprehensively understanding the new task and our proposed model.
Multi-Task Learning with Auxiliary Speaker Identification for Conversational Emotion Recognition
Mar 05, 2020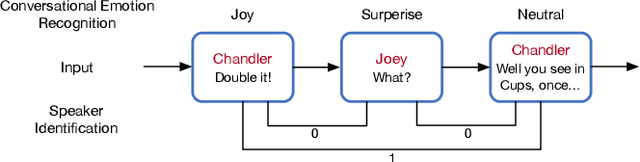
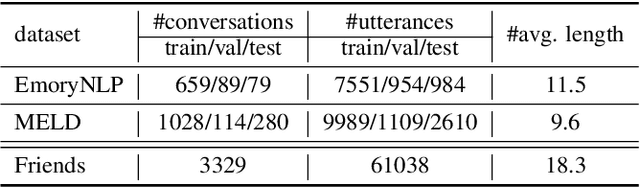


Conversational emotion recognition (CER) has attracted increasing interests in the natural language processing (NLP) community. Different from the vanilla emotion recognition, effective speaker-sensitive utterance representation is one major challenge for CER. In this paper, we exploit speaker identification (SI) as an auxiliary task to enhance the utterance representation in conversations. By this method, we can learn better speaker-aware contextual representations from the additional SI corpus. Experiments on two benchmark datasets demonstrate that the proposed architecture is highly effective for CER, obtaining new state-of-the-art results on two datasets.