 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROG-Grasp: Root-Oriented Geometry for Robotic Grasping and Placement
May 30, 2026Orientation-aware manipulation is essential in post-harvest agricultural processing, where produce must be grasped and placed in consistent configurations. This paper presents ROG-Grasp, a geometry-based robotic grasping and placement framework that estimates the produce orientation from root surface geometry using RGB-D perception. A YOLO-based root detector and point cloud plane fitting are used to infer the root normal, enabling stable grasp pose generation and orientation-constrained Cartesian motion planning. Experiments on tomatoes and onions demonstrate high success rates and stable execution time in both isolated and cluttered scenarios. Compared with vision-language-action (VLA) policies, the proposed method achieves more reliable and accurate grasp completion with faster execution. These results highlight the effectiveness of geometry-driven perception for practical orientation-controlled manipulation tasks. A video of our paper is available online https://youtu.be/Ir2UtGODdMo.
T$^2$PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning
May 04, 2026Recent progress in multi-turn reinforcement learning (RL) has significantly improved reasoning LLMs' performances on complex interactive tasks. Despite advances in stabilization techniques such as fine-grained credit assignment and trajectory filtering, instability remains pervasive and often leads to training collapse. We argue that this instability stems from inefficient exploration in multi-turn settings, where policies continue to generate low-information actions that neither reduce uncertainty nor advance task progress. To address this issue, we propose Token- and Turn-level Policy Optimization (T$^2$PO), an uncertainty-aware framework that explicitly controls exploration at fine-grained levels. At the token level, T$^2$PO monitors uncertainty dynamics and triggers a thinking intervention once the marginal uncertainty change falls below a threshold. At the turn level, T$^2$PO identifies interactions with negligible exploration progress and dynamically resamples such turns to avoid wasted rollouts. We evaluate T$^2$PO in diverse environments, including WebShop, ALFWorld, and Search QA, demonstrating substantial gains in training stability and performance improvements with better exploration efficiency. Code is available at: https://github.com/WillDreamer/T2PO.
VILAS: A VLA-Integrated Low-cost Architecture with Soft Grasping for Robotic Manipulation
May 03, 2026We present VILAS, a fully low-cost, modular robotic manipulation platform designed to support end-to-end vision-language-action (VLA) policy learning and deployment on accessible hardware. The system integrates a Fairino FR5 collaborative arm, a Jodell RG52-50 electric gripper, and a dual-camera perception module, unified through a ZMQ-based communication architecture that seamlessly coordinates teleoperation, data collection, and policy deployment within a single framework. To enable safe manipulation of fragile objects without relying on explicit force sensing, we design a kirigami-based soft compliant gripper extension that induces predictable deformation under compressive loading, providing gentle and repeatable contact with delicate targets. We deploy and evaluate three state-of-the-art VLA models on the VILAS platform: pi_0, pi_0.5, and GR00T N1.6. All models are fine-tuned from publicly released pretrained checkpoints using an identical demonstration dataset collected via our teleoperation pipeline. Experiments on a grape grasping task validate the effectiveness of the proposed system, confirming that capable manipulation policies can be successfully trained and deployed on low-cost modular hardware. Our results further provide practical insights into the deployment characteristics of current VLA models in real-world settings.
WebCoach: Self-Evolving Web Agents with Cross-Session Memory Guidance
Nov 17, 2025Multimodal LLM-powered agents have recently demonstrated impressive capabilities in web navigation, enabling agents to complete complex browsing tasks across diverse domains. However, current agents struggle with repetitive errors and lack the ability to learn from past experiences across sessions, limiting their long-term robustness and sample efficiency. We introduce WebCoach, a model-agnostic self-evolving framework that equips web browsing agents with persistent cross-session memory, enabling improved long-term planning, reflection, and continual learning without retraining. WebCoach consists of three key components: (1) a WebCondenser, which standardizes raw navigation logs into concise summaries; (2) an External Memory Store, which organizes complete trajectories as episodic experiences; and (3) a Coach, which retrieves relevant experiences based on similarity and recency, and decides whether to inject task-specific advice into the agent via runtime hooks. This design empowers web agents to access long-term memory beyond their native context window, improving robustness in complex browsing tasks. Moreover, WebCoach achieves self-evolution by continuously curating episodic memory from new navigation trajectories, enabling agents to improve over time without retraining. Evaluations on the WebVoyager benchmark demonstrate that WebCoach consistently improves the performance of browser-use agents across three different LLM backbones. With a 38B model, it increases task success rates from 47% to 61% while reducing or maintaining the average number of steps. Notably, smaller base models with WebCoach achieve performance comparable to the same web agent using GPT-4o.
Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers
May 09, 2024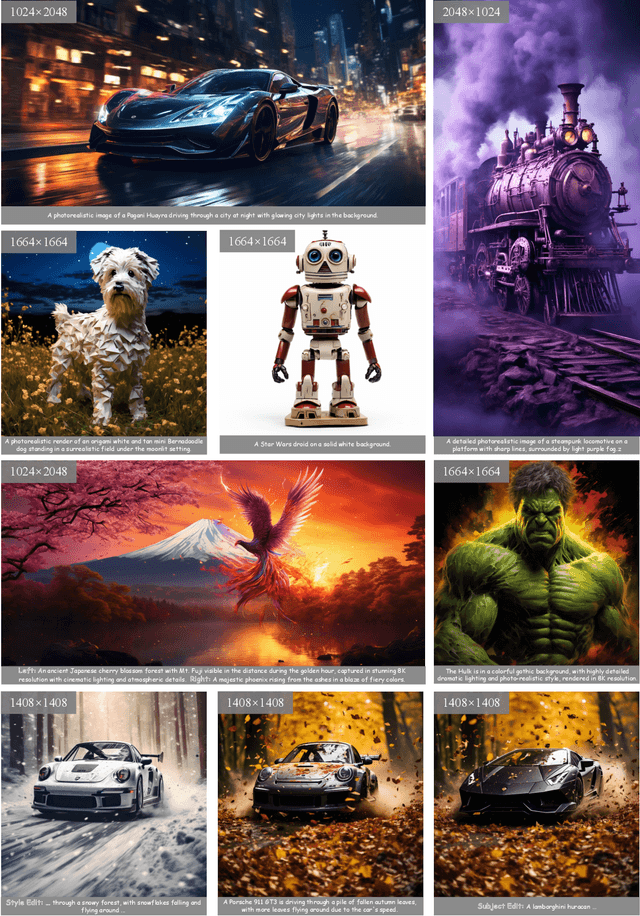
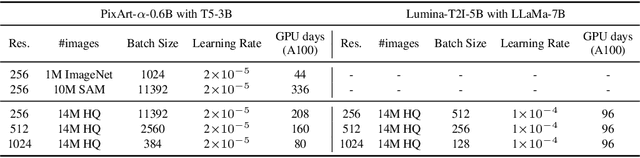
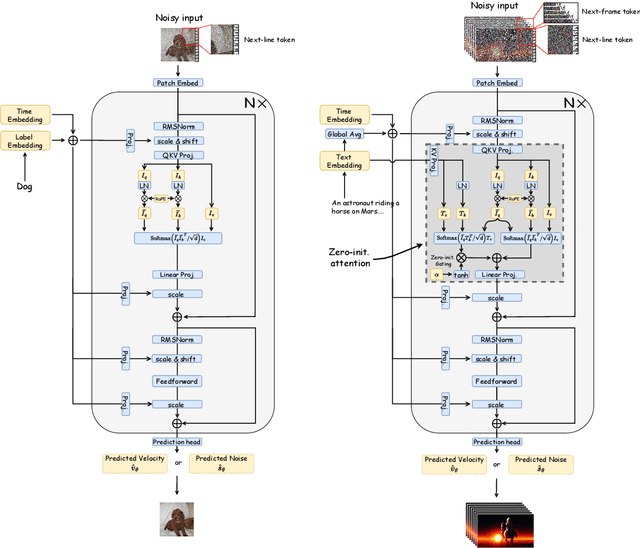
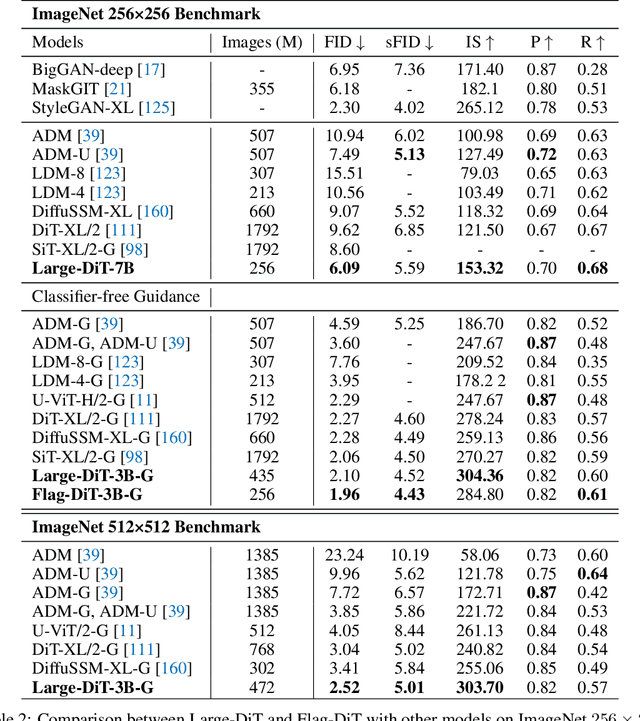
Sora unveils the potential of scaling Diffusion Transformer for generating photorealistic images and videos at arbitrary resolutions, aspect ratios, and durations, yet it still lacks sufficient implementation details. In this technical report, we introduce the Lumina-T2X family - a series of Flow-based Large Diffusion Transformers (Flag-DiT) equipped with zero-initialized attention, as a unified framework designed to transform noise into images, videos, multi-view 3D objects, and audio clips conditioned on text instructions. By tokenizing the latent spatial-temporal space and incorporating learnable placeholders such as [nextline] and [nextframe] tokens, Lumina-T2X seamlessly unifies the representations of different modalities across various spatial-temporal resolutions. This unified approach enables training within a single framework for different modalities and allows for flexible generation of multimodal data at any resolution, aspect ratio, and length during inference. Advanced techniques like RoPE, RMSNorm, and flow matching enhance the stability, flexibility, and scalability of Flag-DiT, enabling models of Lumina-T2X to scale up to 7 billion parameters and extend the context window to 128K tokens. This is particularly beneficial for creating ultra-high-definition images with our Lumina-T2I model and long 720p videos with our Lumina-T2V model. Remarkably, Lumina-T2I, powered by a 5-billion-parameter Flag-DiT, requires only 35% of the training computational costs of a 600-million-parameter naive DiT. Our further comprehensive analysis underscores Lumina-T2X's preliminary capability in resolution extrapolation, high-resolution editing, generating consistent 3D views, and synthesizing videos with seamless transitions. We expect that the open-sourcing of Lumina-T2X will further foster creativity, transparency, and diversity in the generative AI community.
SPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models
Feb 08, 2024



We propose SPHINX-X, an extensive Multimodality Large Language Model (MLLM) series developed upon SPHINX. To improve the architecture and training efficiency, we modify the SPHINX framework by removing redundant visual encoders, bypassing fully-padded sub-images with skip tokens, and simplifying multi-stage training into a one-stage all-in-one paradigm. To fully unleash the potential of MLLMs, we assemble a comprehensive multi-domain and multimodal dataset covering publicly available resources in language, vision, and vision-language tasks. We further enrich this collection with our curated OCR intensive and Set-of-Mark datasets, extending the diversity and generality. By training over different base LLMs including TinyLlama1.1B, InternLM2-7B, LLaMA2-13B, and Mixtral8x7B, we obtain a spectrum of MLLMs that vary in parameter size and multilingual capabilities. Comprehensive benchmarking reveals a strong correlation between the multi-modal performance with the data and parameter scales. Code and models are released at https://github.com/Alpha-VLLM/LLaMA2-Accessory
Context-Aware Entity Grounding with Open-Vocabulary 3D Scene Graphs
Sep 27, 2023



We present an Open-Vocabulary 3D Scene Graph (OVSG), a formal framework for grounding a variety of entities, such as object instances, agents, and regions, with free-form text-based queries. Unlike conventional semantic-based object localization approaches, our system facilitates context-aware entity localization, allowing for queries such as ``pick up a cup on a kitchen table" or ``navigate to a sofa on which someone is sitting". In contrast to existing research on 3D scene graphs, OVSG supports free-form text input and open-vocabulary querying. Through a series of comparative experiments using the ScanNet dataset and a self-collected dataset, we demonstrate that our proposed approach significantly surpasses the performance of previous semantic-based localization techniques. Moreover, we highlight the practical application of OVSG in real-world robot navigation and manipulation experiments.
VIP5: Towards Multimodal Foundation Models for Recommendation
May 23, 2023Computer Vision (CV), Natural Language Processing (NLP), and Recommender Systems (RecSys) are three prominent AI applications that have traditionally developed independently, resulting in disparate modeling and engineering methodologies. This has impeded the ability for these fields to directly benefit from each other's advancements. With the increasing availability of multimodal data on the web, there is a growing need to consider various modalities when making recommendations for users. With the recent emergence of foundation models, large language models have emerged as a potential general-purpose interface for unifying different modalities and problem formulations. In light of this, we propose the development of a multimodal foundation model by considering both visual and textual modalities under the P5 recommendation paradigm (VIP5) to unify various modalities and recommendation tasks. This will enable the processing of vision, language, and personalization information in a shared architecture for improved recommendations. To achieve this, we introduce multimodal personalized prompts to accommodate multiple modalities under a shared format. Additionally, we propose a parameter-efficient training method for foundation models, which involves freezing the backbone and fine-tuning lightweight adapters, resulting in improved recommendation performance and increased efficiency in terms of training time and memory usage.
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
Apr 28, 2023



How to efficiently transform large language models (LLMs) into instruction followers is recently a popular research direction, while training LLM for multi-modal reasoning remains less explored. Although the recent LLaMA-Adapter demonstrates the potential to handle visual inputs with LLMs, it still cannot generalize well to open-ended visual instructions and lags behind GPT-4. In this paper, we present LLaMA-Adapter V2, a parameter-efficient visual instruction model. Specifically, we first augment LLaMA-Adapter by unlocking more learnable parameters (e.g., norm, bias and scale), which distribute the instruction-following ability across the entire LLaMA model besides adapters. Secondly, we propose an early fusion strategy to feed visual tokens only into the early LLM layers, contributing to better visual knowledge incorporation. Thirdly, a joint training paradigm of image-text pairs and instruction-following data is introduced by optimizing disjoint groups of learnable parameters. This strategy effectively alleviates the interference between the two tasks of image-text alignment and instruction following and achieves strong multi-modal reasoning with only a small-scale image-text and instruction dataset. During inference, we incorporate additional expert models (e.g. captioning/OCR systems) into LLaMA-Adapter to further enhance its image understanding capability without incurring training costs. Compared to the original LLaMA-Adapter, our LLaMA-Adapter V2 can perform open-ended multi-modal instructions by merely introducing 14M parameters over LLaMA. The newly designed framework also exhibits stronger language-only instruction-following capabilities and even excels in chat interactions. Our code and models are available at https://github.com/ZrrSkywalker/LLaMA-Adapter.
Revisiting Multimodal Representation in Contrastive Learning: From Patch and Token Embeddings to Finite Discrete Tokens
Mar 27, 2023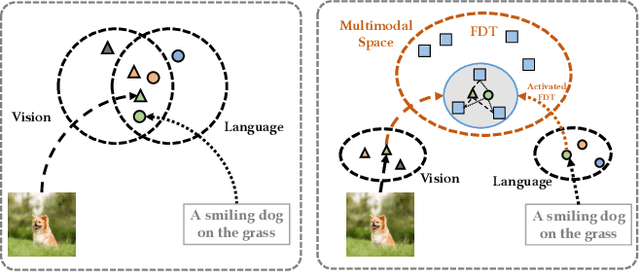

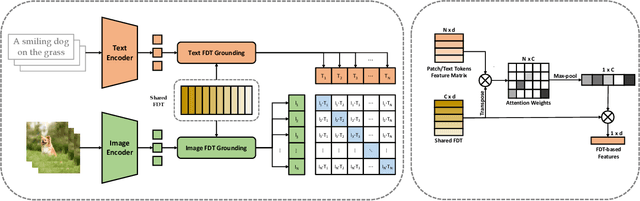

Contrastive learning-based vision-language pre-training approaches, such as CLIP, have demonstrated great success in many vision-language tasks. These methods achieve cross-modal alignment by encoding a matched image-text pair with similar feature embeddings, which are generated by aggregating information from visual patches and language tokens. However, direct aligning cross-modal information using such representations is challenging, as visual patches and text tokens differ in semantic levels and granularities. To alleviate this issue, we propose a Finite Discrete Tokens (FDT) based multimodal representation. FDT is a set of learnable tokens representing certain visual-semantic concepts. Both images and texts are embedded using shared FDT by first grounding multimodal inputs to FDT space and then aggregating the activated FDT representations. The matched visual and semantic concepts are enforced to be represented by the same set of discrete tokens by a sparse activation constraint. As a result, the granularity gap between the two modalities is reduced. Through both quantitative and qualitative analyses, we demonstrate that using FDT representations in CLIP-style models improves cross-modal alignment and performance in visual recognition and vision-language downstream tasks. Furthermore, we show that our method can learn more comprehensive representations, and the learned FDT capture meaningful cross-modal correspondence, ranging from objects to actions and attributes.