 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho is Real Bob? Adversarial Attacks on Speaker Recognition Systems
Paper and Code
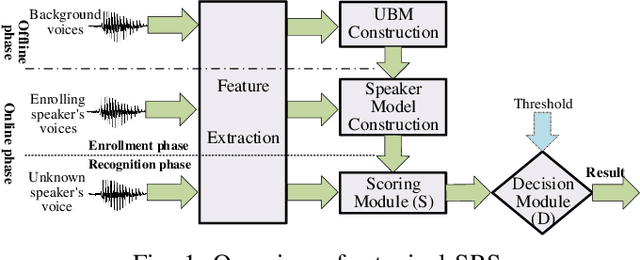


Speaker recognition (SR) is widely used in our daily life as a biometric authentication mechanism. The popularity of SR brings in serious security concerns, as demonstrated by recent adversarial attacks. However, the impacts of such threats in the practical black-box setting are still open, since current attacks consider the white-box setting only. In this paper, we conduct the first comprehensive and systematic study of the adversarial attacks on SR systems (SRSs) to understand their security weakness in the practical black-box setting. For this purpose, we propose an adversarial attack, named FakeBob, to craft adversarial samples. Specifically, we formulate the adversarial sample generation as an optimization problem, incorporated with the confidence of adversarial samples and maximal distortion to balance between the strength and imperceptibility of adversarial voices. One key contribution is to propose a novel algorithm to estimate the score threshold, a feature in SRSs, and use it in the optimization problem to solve the optimization problem. We demonstrate that FakeBob achieves close to 100% targeted attack success rate on both open-source and commercial systems. We further demonstrate that FakeBob is also effective (at least 65% untargeted success rate) on both open-source and commercial systems when playing over the air in the physical world. Moreover, we have conducted a human study which reveals that it is hard for human to differentiate the speakers of the original and adversarial voices. Last but not least, we show that three promising defense methods for adversarial attack from the speech recognition domain become ineffective on SRSs against FakeBob, which calls for more effective defense methods. We highlight that our study peeks into the security implications of adversarial attacks on SRSs, and realistically fosters to improve the security robustness of SRSs.