 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealing Knowledge from Protected Deep Neural Networks Using Composite Unlabeled Data
Dec 09, 2019
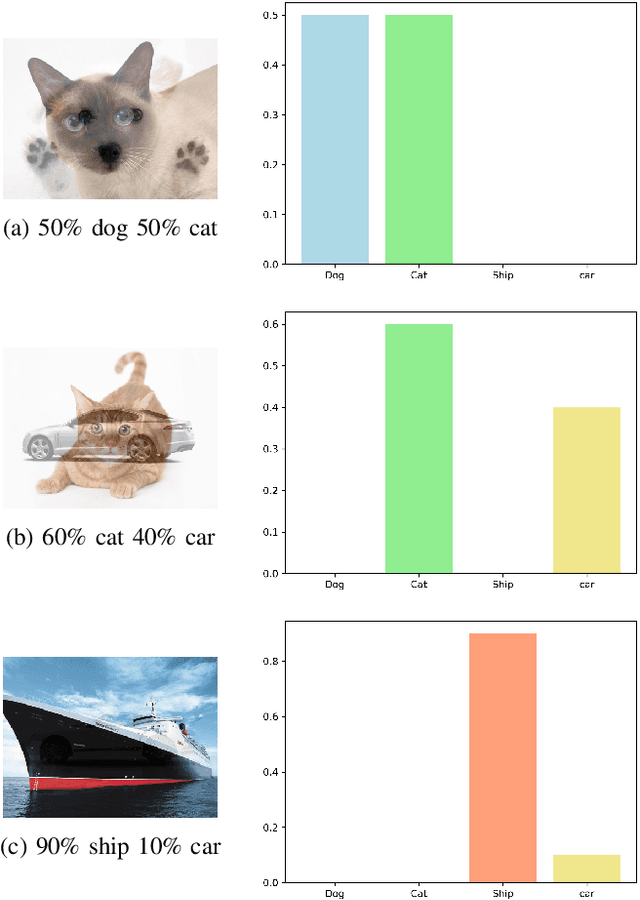

As state-of-the-art deep neural networks are deployed at the core of more advanced Al-based products and services, the incentive for copying them (i.e., their intellectual properties) by rival adversaries is expected to increase considerably over time. The best way to extract or steal knowledge from such networks is by querying them using a large dataset of random samples and recording their output, followed by training a student network to mimic these outputs, without making any assumption about the original networks. The most effective way to protect against such a mimicking attack is to provide only the classification result, without confidence values associated with the softmax layer.In this paper, we present a novel method for generating composite images for attacking a mentor neural network using a student model. Our method assumes no information regarding the mentor's training dataset, architecture, or weights. Further assuming no information regarding the mentor's softmax output values, our method successfully mimics the given neural network and steals all of its knowledge. We also demonstrate that our student network (which copies the mentor) is impervious to watermarking protection methods, and thus would not be detected as a stolen model.Our results imply, essentially, that all current neural networks are vulnerable to mimicking attacks, even if they do not divulge anything but the most basic required output, and that the student model which mimics them cannot be easily detected and singled out as a stolen copy using currently available techniques.
DeepMimic: Mentor-Student Unlabeled Data Based Training
Nov 24, 2019

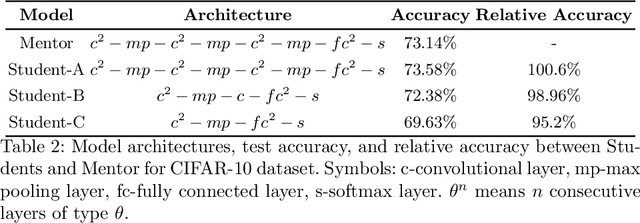

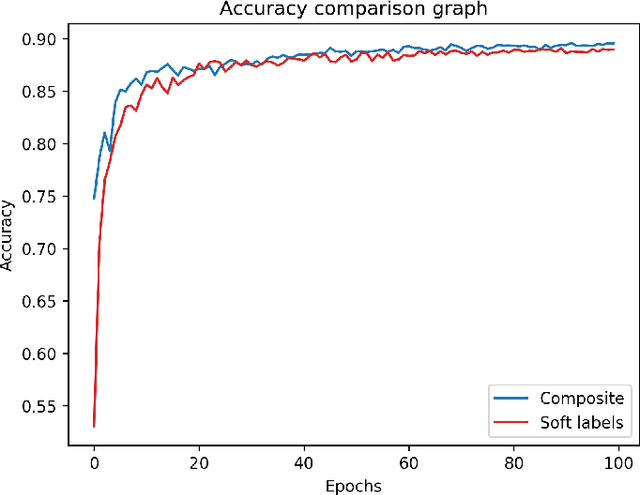
In this paper, we present a deep neural network (DNN) training approach called the "DeepMimic" training method. Enormous amounts of data are available nowadays for training usage. Yet, only a tiny portion of these data is manually labeled, whereas almost all of the data are unlabeled. The training approach presented utilizes, in a most simplified manner, the unlabeled data to the fullest, in order to achieve remarkable (classification) results. Our DeepMimic method uses a small portion of labeled data and a large amount of unlabeled data for the training process, as expected in a real-world scenario. It consists of a mentor model and a student model. Employing a mentor model trained on a small portion of the labeled data and then feeding it only with unlabeled data, we show how to obtain a (simplified) student model that reaches the same accuracy and loss as the mentor model, on the same test set, without using any of the original data labels in the training of the student model. Our experiments demonstrate that even on challenging classification tasks the student network architecture can be simplified significantly with a minor influence on the performance, i.e., we need not even know the original network architecture of the mentor. In addition, the time required for training the student model to reach the mentor's performance level is shorter, as a result of a simplified architecture and more available data. The proposed method highlights the disadvantages of regular supervised training and demonstrates the benefits of a less traditional training approach.