 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMimic: Mentor-Student Unlabeled Data Based Training
Paper and Code
Nov 24, 2019

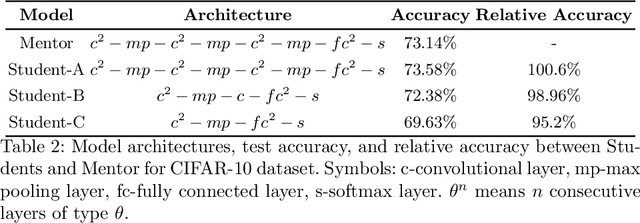

In this paper, we present a deep neural network (DNN) training approach called the "DeepMimic" training method. Enormous amounts of data are available nowadays for training usage. Yet, only a tiny portion of these data is manually labeled, whereas almost all of the data are unlabeled. The training approach presented utilizes, in a most simplified manner, the unlabeled data to the fullest, in order to achieve remarkable (classification) results. Our DeepMimic method uses a small portion of labeled data and a large amount of unlabeled data for the training process, as expected in a real-world scenario. It consists of a mentor model and a student model. Employing a mentor model trained on a small portion of the labeled data and then feeding it only with unlabeled data, we show how to obtain a (simplified) student model that reaches the same accuracy and loss as the mentor model, on the same test set, without using any of the original data labels in the training of the student model. Our experiments demonstrate that even on challenging classification tasks the student network architecture can be simplified significantly with a minor influence on the performance, i.e., we need not even know the original network architecture of the mentor. In addition, the time required for training the student model to reach the mentor's performance level is shorter, as a result of a simplified architecture and more available data. The proposed method highlights the disadvantages of regular supervised training and demonstrates the benefits of a less traditional training approach.