 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Textual Descriptions from Representations of Continuous Prompts
Paper and Code
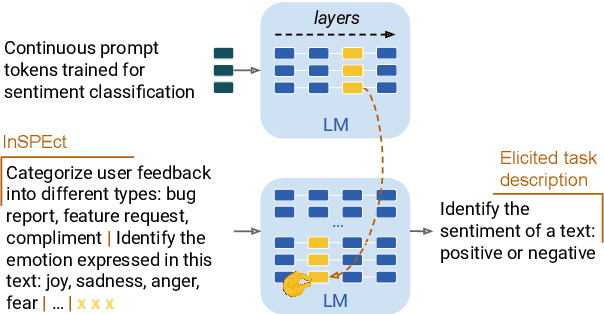

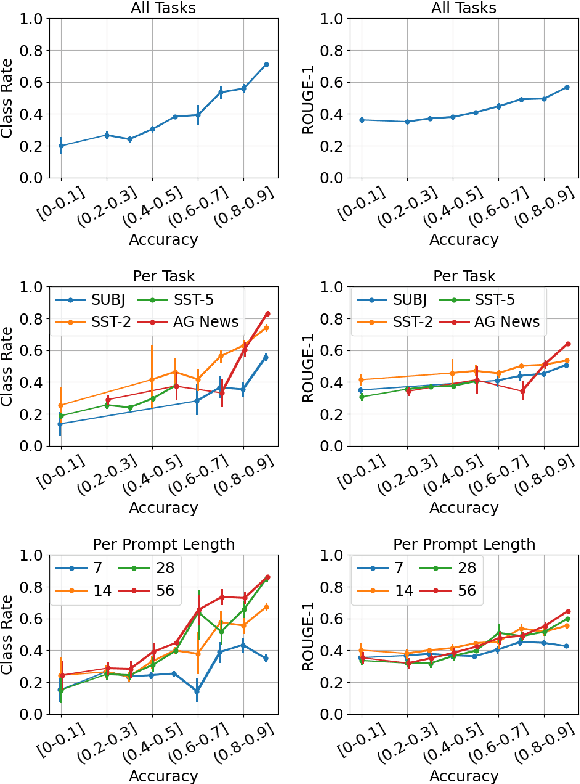
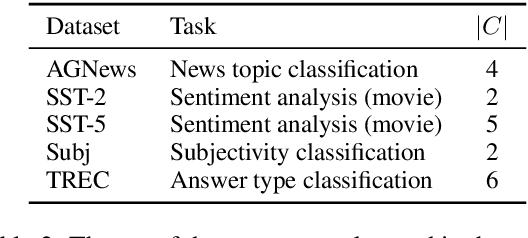
Continuous prompts, or "soft prompts", are a widely-adopted parameter-efficient tuning strategy for large language models, but are often less favorable due to their opaque nature. Prior attempts to interpret continuous prompts relied on projecting individual prompt tokens onto the vocabulary space. However, this approach is problematic as performant prompts can yield arbitrary or contradictory text, and it interprets prompt tokens individually. In this work, we propose a new approach to interpret continuous prompts that elicits textual descriptions from their representations during model inference. Using a Patchscopes variant (Ghandeharioun et al., 2024) called InSPEcT over various tasks, we show our method often yields accurate task descriptions which become more faithful as task performance increases. Moreover, an elaborated version of InSPEcT reveals biased features in continuous prompts, whose presence correlates with biased model predictions. Providing an effective interpretability solution, InSPEcT can be leveraged to debug unwanted properties in continuous prompts and inform developers on ways to mitigate them.