 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Predict Sentence by Sentence
May 28, 2025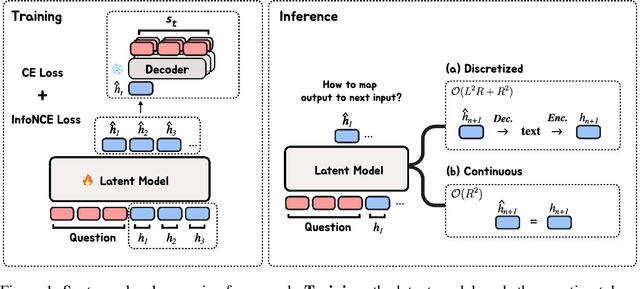
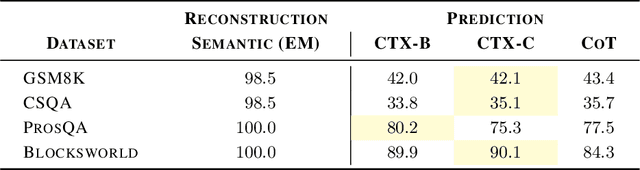
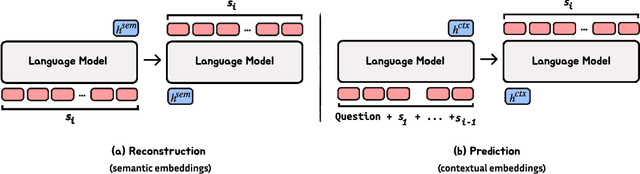
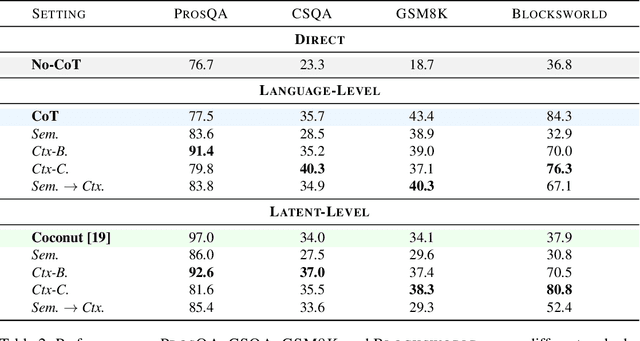
Autoregressive language models (LMs) generate one token at a time, yet human reasoning operates over higher-level abstractions - sentences, propositions, and concepts. This contrast raises a central question- Can LMs likewise learn to reason over structured semantic units rather than raw token sequences? In this work, we investigate whether pretrained LMs can be lifted into such abstract reasoning spaces by building on their learned representations. We present a framework that adapts a pretrained token-level LM to operate in sentence space by autoregressively predicting continuous embeddings of next sentences. We explore two embedding paradigms inspired by classical representation learning: 1) semantic embeddings, learned via autoencoding to preserve surface meaning; and 2) contextual embeddings, trained via next-sentence prediction to encode anticipatory structure. We evaluate both under two inference regimes: Discretized, which decodes each predicted embedding into text before re-encoding; and Continuous, which reasons entirely in embedding space for improved efficiency. Across four domains - mathematics, logic, commonsense, and planning - contextual embeddings under continuous inference show competitive performance with Chain-of-Thought (CoT) while reducing inference-time FLOPs on average by half. We also present early signs of scalability and modular adaptation. Finally, to visualize latent trajectories, we introduce SentenceLens, a diagnostic tool that decodes intermediate model states into interpretable sentences. Together, our results indicate that pretrained LMs can effectively transition to abstract, structured reasoning within latent embedding spaces.
Latent Action Pretraining from Videos
Oct 15, 2024



We introduce Latent Action Pretraining for general Action models (LAPA), an unsupervised method for pretraining Vision-Language-Action (VLA) models without ground-truth robot action labels. Existing Vision-Language-Action models require action labels typically collected by human teleoperators during pretraining, which significantly limits possible data sources and scale. In this work, we propose a method to learn from internet-scale videos that do not have robot action labels. We first train an action quantization model leveraging VQ-VAE-based objective to learn discrete latent actions between image frames, then pretrain a latent VLA model to predict these latent actions from observations and task descriptions, and finally finetune the VLA on small-scale robot manipulation data to map from latent to robot actions. Experimental results demonstrate that our method significantly outperforms existing techniques that train robot manipulation policies from large-scale videos. Furthermore, it outperforms the state-of-the-art VLA model trained with robotic action labels on real-world manipulation tasks that require language conditioning, generalization to unseen objects, and semantic generalization to unseen instructions. Training only on human manipulation videos also shows positive transfer, opening up the potential for leveraging web-scale data for robotics foundation model.
Ask Optimal Questions: Aligning Large Language Models with Retriever's Preference in Conversational Search
Feb 19, 2024



Conversational search, unlike single-turn retrieval tasks, requires understanding the current question within a dialogue context. The common approach of rewrite-then-retrieve aims to decontextualize questions to be self-sufficient for off-the-shelf retrievers, but most existing methods produce sub-optimal query rewrites due to the limited ability to incorporate signals from the retrieval results. To overcome this limitation, we present a novel framework RetPO (Retriever's Preference Optimization), which is designed to optimize a language model (LM) for reformulating search queries in line with the preferences of the target retrieval systems. The process begins by prompting a large LM to produce various potential rewrites and then collects retrieval performance for these rewrites as the retrievers' preferences. Through the process, we construct a large-scale dataset called RF collection, containing Retrievers' Feedback on over 410K query rewrites across 12K conversations. Furthermore, we fine-tune a smaller LM using this dataset to align it with the retrievers' preferences as feedback. The resulting model achieves state-of-the-art performance on two recent conversational search benchmarks, significantly outperforming existing baselines, including GPT-3.5.
Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models
Oct 23, 2023Questions in open-domain question answering are often ambiguous, allowing multiple interpretations. One approach to handling them is to identify all possible interpretations of the ambiguous question (AQ) and to generate a long-form answer addressing them all, as suggested by Stelmakh et al., (2022). While it provides a comprehensive response without bothering the user for clarification, considering multiple dimensions of ambiguity and gathering corresponding knowledge remains a challenge. To cope with the challenge, we propose a novel framework, Tree of Clarifications (ToC): It recursively constructs a tree of disambiguations for the AQ -- via few-shot prompting leveraging external knowledge -- and uses it to generate a long-form answer. ToC outperforms existing baselines on ASQA in a few-shot setup across the metrics, while surpassing fully-supervised baselines trained on the whole training set in terms of Disambig-F1 and Disambig-ROUGE. Code is available at https://github.com/gankim/tree-of-clarifications.