 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL
Feb 03, 2026Large Language Models (LLMs) that can continually improve beyond their training budgets are able to solve increasingly difficult problems by adapting at test time, a property we refer to as extrapolation. However, standard reinforcement learning (RL) operates over fixed problem distributions and training budgets, which limits extrapolation amidst distribution shift at test time. To address this, we introduce RC, an iterative decoding algorithm that replaces standard autoregressive decoding during both training and inference. RC exploits an asymmetry between the response generation and summarization capabilities of LLMs to construct reasoning chains that consistently improve across iterations. Models trained to use RC can extrapolate and continually improve over reasoning horizons more than an order of magnitude longer than those seen during training. Empirically, training a 4B model with RC using a 16k-token training budget improves performance on HMMT 2025 from 40% to nearly 70% with 0.5m tokens at test time, outperforming both comparably sized models and many larger reasoning LLMs. Finally, we also show that models trained with RC can more effectively leverage existing scaffolds to further scale test-time performance, due to the improved summary-conditioned generation abilities learned through training.
InT: Self-Proposed Interventions Enable Credit Assignment in LLM Reasoning
Jan 20, 2026Outcome-reward reinforcement learning (RL) has proven effective at improving the reasoning capabilities of large language models (LLMs). However, standard RL assigns credit only at the level of the final answer, penalizing entire reasoning traces when the outcome is incorrect and uniformly reinforcing all steps when it is correct. As a result, correct intermediate steps may be discouraged in failed traces, while spurious steps may be reinforced in successful ones. We refer to this failure mode as the problem of credit assignment. While a natural remedy is to train a process reward model, accurately optimizing such models to identify corrective reasoning steps remains challenging. We introduce Intervention Training (InT), a training paradigm in which the model performs fine-grained credit assignment on its own reasoning traces by proposing short, targeted corrections that steer trajectories toward higher reward. Using reference solutions commonly available in mathematical reasoning datasets and exploiting the fact that verifying a model-generated solution is easier than generating a correct one from scratch, the model identifies the first error in its reasoning and proposes a single-step intervention to redirect the trajectory toward the correct solution. We then apply supervised fine-tuning (SFT) to the on-policy rollout up to the point of error concatenated with the intervention, localizing error to the specific step that caused failure. We show that the resulting model serves as a far better initialization for RL training. After running InT and subsequent fine-tuning with RL, we improve accuracy by nearly 14% over a 4B-parameter base model on IMO-AnswerBench, outperforming larger open-source models such as gpt-oss-20b.
e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs
Jun 10, 2025Test-time scaling offers a promising path to improve LLM reasoning by utilizing more compute at inference time; however, the true promise of this paradigm lies in extrapolation (i.e., improvement in performance on hard problems as LLMs keep "thinking" for longer, beyond the maximum token budget they were trained on). Surprisingly, we find that most existing reasoning models do not extrapolate well. We show that one way to enable extrapolation is by training the LLM to perform in-context exploration: training the LLM to effectively spend its test time budget by chaining operations (such as generation, verification, refinement, etc.), or testing multiple hypotheses before it commits to an answer. To enable in-context exploration, we identify three key ingredients as part of our recipe e3: (1) chaining skills that the base LLM has asymmetric competence in, e.g., chaining verification (easy) with generation (hard), as a way to implement in-context search; (2) leveraging "negative" gradients from incorrect traces to amplify exploration during RL, resulting in longer search traces that chains additional asymmetries; and (3) coupling task difficulty with training token budget during training via a specifically-designed curriculum to structure in-context exploration. Our recipe e3 produces the best known 1.7B model according to AIME'25 and HMMT'25 scores, and extrapolates to 2x the training token budget. Our e3-1.7B model not only attains high pass@1 scores, but also improves pass@k over the base model.
M-Prometheus: A Suite of Open Multilingual LLM Judges
Apr 07, 2025The use of language models for automatically evaluating long-form text (LLM-as-a-judge) is becoming increasingly common, yet most LLM judges are optimized exclusively for English, with strategies for enhancing their multilingual evaluation capabilities remaining largely unexplored in the current literature. This has created a disparity in the quality of automatic evaluation methods for non-English languages, ultimately hindering the development of models with better multilingual capabilities. To bridge this gap, we introduce M-Prometheus, a suite of open-weight LLM judges ranging from 3B to 14B parameters that can provide both direct assessment and pairwise comparison feedback on multilingual outputs. M-Prometheus models outperform state-of-the-art open LLM judges on multilingual reward benchmarks spanning more than 20 languages, as well as on literary machine translation (MT) evaluation covering 4 language pairs. Furthermore, M-Prometheus models can be leveraged at decoding time to significantly improve generated outputs across all 3 tested languages, showcasing their utility for the development of better multilingual models. Lastly, through extensive ablations, we identify the key factors for obtaining an effective multilingual judge, including backbone model selection and training on natively multilingual feedback data instead of translated data. We release our models, training dataset, and code.
Scaling Evaluation-time Compute with Reasoning Models as Process Evaluators
Mar 25, 2025As language model (LM) outputs get more and more natural, it is becoming more difficult than ever to evaluate their quality. Simultaneously, increasing LMs' "thinking" time through scaling test-time compute has proven an effective technique to solve challenging problems in domains such as math and code. This raises a natural question: can an LM's evaluation capability also be improved by spending more test-time compute? To answer this, we investigate employing reasoning models-LMs that natively generate long chain-of-thought reasoning-as evaluators. Specifically, we examine methods to leverage more test-time compute by (1) using reasoning models, and (2) prompting these models to evaluate not only the response as a whole (i.e., outcome evaluation) but also assess each step in the response separately (i.e., process evaluation). In experiments, we observe that the evaluator's performance improves monotonically when generating more reasoning tokens, similar to the trends observed in LM-based generation. Furthermore, we use these more accurate evaluators to rerank multiple generations, and demonstrate that spending more compute at evaluation time can be as effective as using more compute at generation time in improving an LM's problem-solving capability.
Better Instruction-Following Through Minimum Bayes Risk
Oct 07, 2024General-purpose LLM judges capable of human-level evaluation provide not only a scalable and accurate way of evaluating instruction-following LLMs but also new avenues for supervising and improving their performance. One promising way of leveraging LLM judges for supervision is through Minimum Bayes Risk (MBR) decoding, which uses a reference-based evaluator to select a high-quality output from amongst a set of candidate outputs. In the first part of this work, we explore using MBR decoding as a method for improving the test-time performance of instruction-following LLMs. We find that MBR decoding with reference-based LLM judges substantially improves over greedy decoding, best-of-N decoding with reference-free judges and MBR decoding with lexical and embedding-based metrics on AlpacaEval and MT-Bench. These gains are consistent across LLMs with up to 70B parameters, demonstrating that smaller LLM judges can be used to supervise much larger LLMs. Then, seeking to retain the improvements from MBR decoding while mitigating additional test-time costs, we explore iterative self-training on MBR-decoded outputs. We find that self-training using Direct Preference Optimisation leads to significant performance gains, such that the self-trained models with greedy decoding generally match and sometimes exceed the performance of their base models with MBR decoding.
Synthetic Multimodal Question Generation
Jul 02, 2024



Multimodal Retrieval Augmented Generation (MMRAG) is a powerful approach to question-answering over multimodal documents. A key challenge with evaluating MMRAG is the paucity of high-quality datasets matching the question styles and modalities of interest. In light of this, we propose SMMQG, a synthetic data generation framework. SMMQG leverages interplay between a retriever, large language model (LLM) and large multimodal model (LMM) to generate question and answer pairs directly from multimodal documents, with the questions conforming to specified styles and modalities. We use SMMQG to generate an MMRAG dataset of 1024 questions over Wikipedia documents and evaluate state-of-the-art models using it, revealing insights into model performance that are attainable only through style- and modality-specific evaluation data. Next, we measure the quality of data produced by SMMQG via a human study. We find that the quality of our synthetic data is on par with the quality of the crowdsourced benchmark MMQA and that downstream evaluation results using both datasets strongly concur.
Be Selfish, But Wisely: Investigating the Impact of Agent Personality in Mixed-Motive Human-Agent Interactions
Oct 22, 2023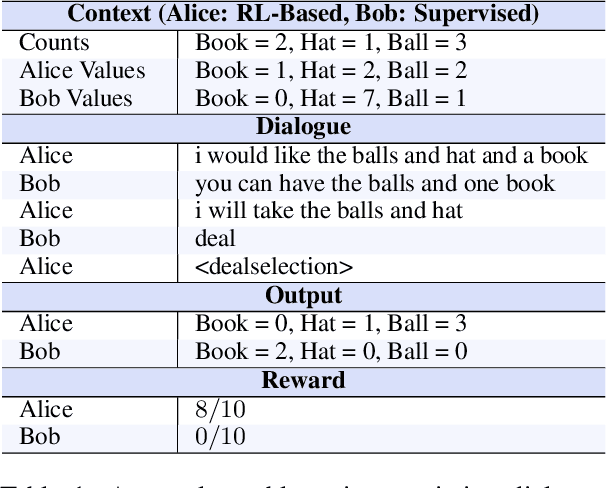
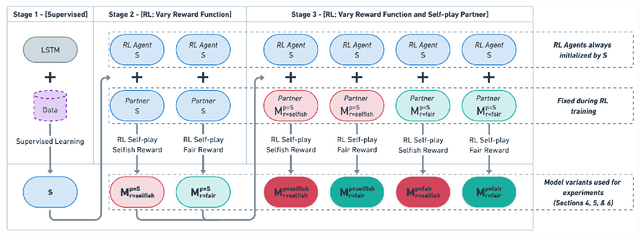

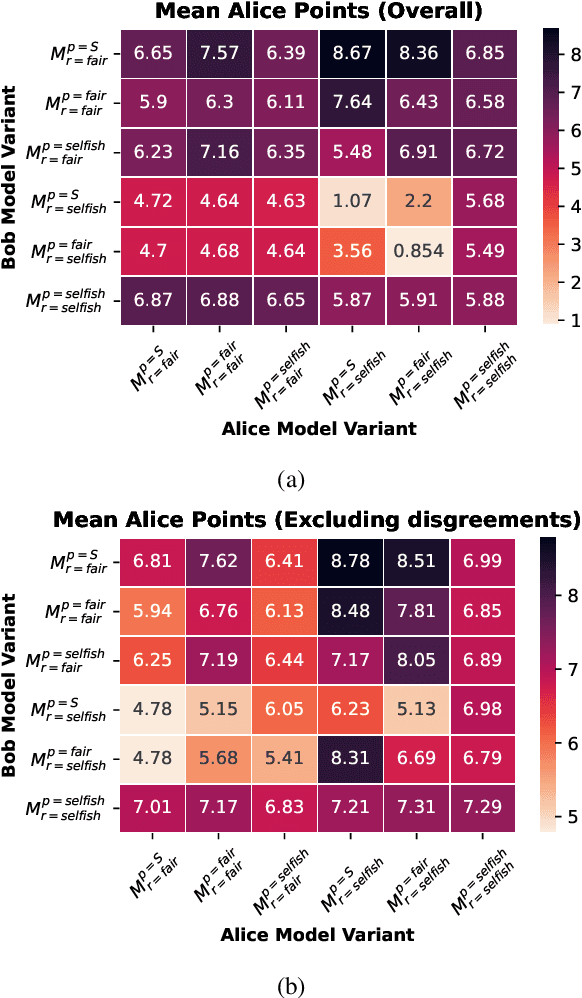
A natural way to design a negotiation dialogue system is via self-play RL: train an agent that learns to maximize its performance by interacting with a simulated user that has been designed to imitate human-human dialogue data. Although this procedure has been adopted in prior work, we find that it results in a fundamentally flawed system that fails to learn the value of compromise in a negotiation, which can often lead to no agreements (i.e., the partner walking away without a deal), ultimately hurting the model's overall performance. We investigate this observation in the context of the DealOrNoDeal task, a multi-issue negotiation over books, hats, and balls. Grounded in negotiation theory from Economics, we modify the training procedure in two novel ways to design agents with diverse personalities and analyze their performance with human partners. We find that although both techniques show promise, a selfish agent, which maximizes its own performance while also avoiding walkaways, performs superior to other variants by implicitly learning to generate value for both itself and the negotiation partner. We discuss the implications of our findings for what it means to be a successful negotiation dialogue system and how these systems should be designed in the future.