 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEQUOR: A Multi-Turn Benchmark for Realistic Constraint Following
May 07, 2026In a conversation, a helpful assistant must reliably follow user directives, even as they refine, modify, or contradict earlier requests. Yet most instruction-following benchmarks focus on single-turn or short multi-turn scenarios, leaving open how well models handle long-horizon instruction-following tasks. To bridge this gap, we present SEQUOR, an automatic benchmark for evaluating constraint adherence in long multi-turn conversations. SEQUOR consists of simulated persona-driven interactions built with constraints extracted from real-world conversations. Our results show that even when following a single constraint, instruction-following accuracy consistently decreases as the conversation grows longer, with drops exceeding 11%. This decline becomes larger when models have to follow multiple constraints simultaneously, reducing their accuracy by over 40%. In scenarios where constraints are added or replaced at arbitrary points of the conversation, model accuracy decreases by more than 9%. Taken together, our results reveal that current models still struggle to follow user instructions in multi-turn conversations, and provide a way for better measuring instruction-following capabilities in assistants.
Self-Preference Bias in Rubric-Based Evaluation of Large Language Models
Apr 08, 2026LLM-as-a-judge has become the de facto approach for evaluating LLM outputs. However, judges are known to exhibit self-preference bias (SPB): they tend to favor outputs produced by themselves or by models from their own family. This skews evaluations and, thus, hinders model development, especially in settings of recursive self-improvement. We present the first study of SPB in rubric-based evaluation, an increasingly popular benchmarking paradigm where judges issue binary verdicts on individual evaluation criteria, instead of assigning holistic scores or rankings. Using IFEval, a benchmark with programmatically verifiable rubrics, we show that SPB persists even when evaluation criteria are entirely objective: among rubrics where generators fail, judges can be up to 50\% more likely to incorrectly mark them as satisfied when the output is their own. We also find that, similarly to other evaluation paradigms, ensembling multiple judges helps mitigate SPB, but without fully eliminating it. On HealthBench, a medical chat benchmark with subjective rubrics, we observe that SPB skews model scores by up to 10 points, a potentially decisive margin when ranking frontier models. We analyze the factors that drive SPB in this setting, finding that negative rubrics, extreme rubric lengths, and subjective topics like emergency referrals are particularly susceptible.
EuroLLM-22B: Technical Report
Feb 05, 2026This report presents EuroLLM-22B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-22B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. Across a broad set of multilingual benchmarks, EuroLLM-22B demonstrates strong performance in reasoning, instruction following, and translation, achieving results competitive with models of comparable size. To support future research, we release our base and instruction-tuned models, our multilingual web pretraining data and updated EuroBlocks instruction datasets, as well as our pre-training and evaluation codebases.
MindGuard: Guardrail Classifiers for Multi-Turn Mental Health Support
Feb 01, 2026Large language models are increasingly used for mental health support, yet their conversational coherence alone does not ensure clinical appropriateness. Existing general-purpose safeguards often fail to distinguish between therapeutic disclosures and genuine clinical crises, leading to safety failures. To address this gap, we introduce a clinically grounded risk taxonomy, developed in collaboration with PhD-level psychologists, that identifies actionable harm (e.g., self-harm and harm to others) while preserving space for safe, non-crisis therapeutic content. We release MindGuard-testset, a dataset of real-world multi-turn conversations annotated at the turn level by clinical experts. Using synthetic dialogues generated via a controlled two-agent setup, we train MindGuard, a family of lightweight safety classifiers (with 4B and 8B parameters). Our classifiers reduce false positives at high-recall operating points and, when paired with clinician language models, help achieve lower attack success and harmful engagement rates in adversarial multi-turn interactions compared to general-purpose safeguards. We release all models and human evaluation data.
EuroLLM-9B: Technical Report
Jun 04, 2025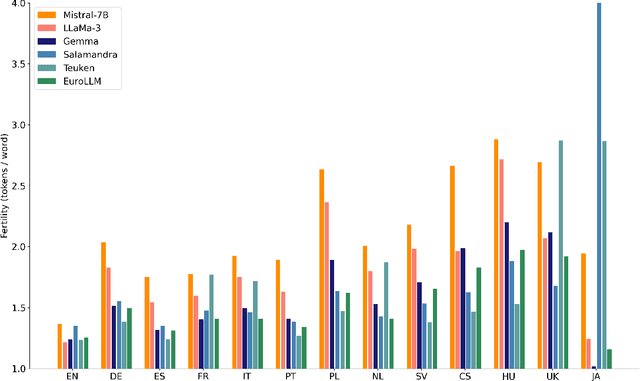
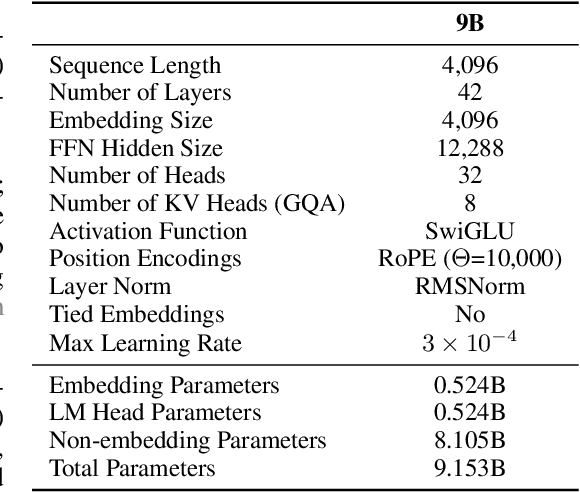
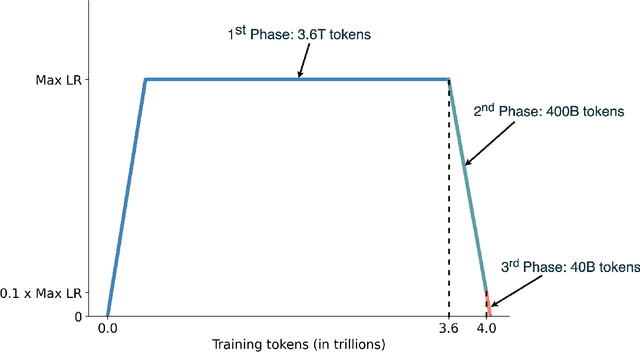
This report presents EuroLLM-9B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-9B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. We describe the pre-training data collection and filtering pipeline, including the creation of EuroFilter, an AI-based multilingual filter, as well as the design of EuroBlocks-Synthetic, a novel synthetic dataset for post-training that enhances language coverage for European languages. Evaluation results demonstrate EuroLLM-9B's competitive performance on multilingual benchmarks and machine translation tasks, establishing it as the leading open European-made LLM of its size. To support open research and adoption, we release all major components of this work, including the base and instruction-tuned models, the EuroFilter classifier, and the synthetic post-training dataset.
M-Prometheus: A Suite of Open Multilingual LLM Judges
Apr 07, 2025The use of language models for automatically evaluating long-form text (LLM-as-a-judge) is becoming increasingly common, yet most LLM judges are optimized exclusively for English, with strategies for enhancing their multilingual evaluation capabilities remaining largely unexplored in the current literature. This has created a disparity in the quality of automatic evaluation methods for non-English languages, ultimately hindering the development of models with better multilingual capabilities. To bridge this gap, we introduce M-Prometheus, a suite of open-weight LLM judges ranging from 3B to 14B parameters that can provide both direct assessment and pairwise comparison feedback on multilingual outputs. M-Prometheus models outperform state-of-the-art open LLM judges on multilingual reward benchmarks spanning more than 20 languages, as well as on literary machine translation (MT) evaluation covering 4 language pairs. Furthermore, M-Prometheus models can be leveraged at decoding time to significantly improve generated outputs across all 3 tested languages, showcasing their utility for the development of better multilingual models. Lastly, through extensive ablations, we identify the key factors for obtaining an effective multilingual judge, including backbone model selection and training on natively multilingual feedback data instead of translated data. We release our models, training dataset, and code.
Zero-shot Benchmarking: A Framework for Flexible and Scalable Automatic Evaluation of Language Models
Apr 01, 2025As language models improve and become capable of performing more complex tasks across modalities, evaluating them automatically becomes increasingly challenging. Developing strong and robust task-specific automatic metrics gets harder, and human-annotated test sets -- which are expensive to create -- saturate more quickly. A compelling alternative is to design reliable strategies to automate the creation of test data and evaluation, but previous attempts either rely on pre-existing data, or focus solely on individual tasks. We present Zero-shot Benchmarking (ZSB), a framework for creating high-quality benchmarks for any task by leveraging language models for both synthetic test data creation and evaluation. ZSB is simple and flexible: it requires only the creation of a prompt for data generation and one for evaluation; it is scalable to tasks and languages where collecting real-world data is costly or impractical; it is model-agnostic, allowing the creation of increasingly challenging benchmarks as models improve. To assess the effectiveness of our framework, we create benchmarks for five text-only tasks and a multi-modal one: general capabilities in four languages (English, Chinese, French, and Korean), translation, and general vision-language capabilities in English. We then rank a broad range of open and closed systems on our benchmarks. ZSB rankings consistently correlate strongly with human rankings, outperforming widely-adopted standard benchmarks. Through ablations, we find that strong benchmarks can be created with open models, and that judge model size and dataset variety are crucial drivers of performance. We release all our benchmarks, and code to reproduce our experiments and to produce new benchmarks.
Adding Chocolate to Mint: Mitigating Metric Interference in Machine Translation
Mar 11, 2025As automatic metrics become increasingly stronger and widely adopted, the risk of unintentionally "gaming the metric" during model development rises. This issue is caused by metric interference (Mint), i.e., the use of the same or related metrics for both model tuning and evaluation. Mint can misguide practitioners into being overoptimistic about the performance of their systems: as system outputs become a function of the interfering metric, their estimated quality loses correlation with human judgments. In this work, we analyze two common cases of Mint in machine translation-related tasks: filtering of training data, and decoding with quality signals. Importantly, we find that Mint strongly distorts instance-level metric scores, even when metrics are not directly optimized for -- questioning the common strategy of leveraging a different, yet related metric for evaluation that is not used for tuning. To address this problem, we propose MintAdjust, a method for more reliable evaluation under Mint. On the WMT24 MT shared task test set, MintAdjust ranks translations and systems more accurately than state-of-the-art-metrics across a majority of language pairs, especially for high-quality systems. Furthermore, MintAdjust outperforms AutoRank, the ensembling method used by the organizers.
A Context-aware Framework for Translation-mediated Conversations
Dec 05, 2024Effective communication is fundamental to any interaction, yet challenges arise when participants do not share a common language. Automatic translation systems offer a powerful solution to bridge language barriers in such scenarios, but they introduce errors that can lead to misunderstandings and conversation breakdown. A key issue is that current systems fail to incorporate the rich contextual information necessary to resolve ambiguities and omitted details, resulting in literal, inappropriate, or misaligned translations. In this work, we present a framework to improve large language model-based translation systems by incorporating contextual information in bilingual conversational settings. During training, we leverage context-augmented parallel data, which allows the model to generate translations sensitive to conversational history. During inference, we perform quality-aware decoding with context-aware metrics to select the optimal translation from a pool of candidates. We validate both components of our framework on two task-oriented domains: customer chat and user-assistant interaction. Across both settings, our framework consistently results in better translations than state-of-the-art systems like GPT-4o and TowerInstruct, as measured by multiple automatic translation quality metrics on several language pairs. We also show that the resulting model leverages context in an intended and interpretable way, improving consistency between the conveyed message and the generated translations.
EuroLLM: Multilingual Language Models for Europe
Sep 24, 2024The quality of open-weight LLMs has seen significant improvement, yet they remain predominantly focused on English. In this paper, we introduce the EuroLLM project, aimed at developing a suite of open-weight multilingual LLMs capable of understanding and generating text in all official European Union languages, as well as several additional relevant languages. We outline the progress made to date, detailing our data collection and filtering process, the development of scaling laws, the creation of our multilingual tokenizer, and the data mix and modeling configurations. Additionally, we release our initial models: EuroLLM-1.7B and EuroLLM-1.7B-Instruct and report their performance on multilingual general benchmarks and machine translation.