 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexTower: A Multilingual LLM for Explaining and Correcting Translation Errors
Jun 27, 2024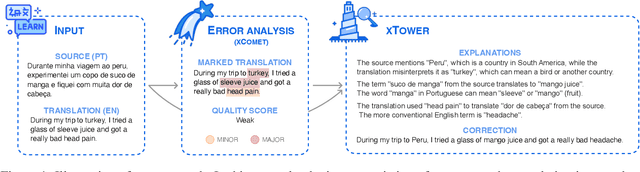

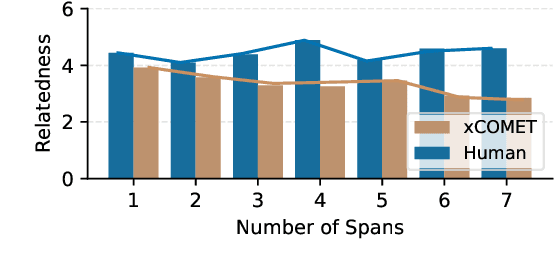

While machine translation (MT) systems are achieving increasingly strong performance on benchmarks, they often produce translations with errors and anomalies. Understanding these errors can potentially help improve the translation quality and user experience. This paper introduces xTower, an open large language model (LLM) built on top of TowerBase designed to provide free-text explanations for translation errors in order to guide the generation of a corrected translation. The quality of the generated explanations by xTower are assessed via both intrinsic and extrinsic evaluation. We ask expert translators to evaluate the quality of the explanations across two dimensions: relatedness towards the error span being explained and helpfulness in error understanding and improving translation quality. Extrinsically, we test xTower across various experimental setups in generating translation corrections, demonstrating significant improvements in translation quality. Our findings highlight xTower's potential towards not only producing plausible and helpful explanations of automatic translations, but also leveraging them to suggest corrected translations.
xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection
Oct 16, 2023Widely used learned metrics for machine translation evaluation, such as COMET and BLEURT, estimate the quality of a translation hypothesis by providing a single sentence-level score. As such, they offer little insight into translation errors (e.g., what are the errors and what is their severity). On the other hand, generative large language models (LLMs) are amplifying the adoption of more granular strategies to evaluation, attempting to detail and categorize translation errors. In this work, we introduce xCOMET, an open-source learned metric designed to bridge the gap between these approaches. xCOMET integrates both sentence-level evaluation and error span detection capabilities, exhibiting state-of-the-art performance across all types of evaluation (sentence-level, system-level, and error span detection). Moreover, it does so while highlighting and categorizing error spans, thus enriching the quality assessment. We also provide a robustness analysis with stress tests, and show that xCOMET is largely capable of identifying localized critical errors and hallucinations.
Scaling up COMETKIWI: Unbabel-IST 2023 Submission for the Quality Estimation Shared Task
Sep 21, 2023



We present the joint contribution of Unbabel and Instituto Superior T\'ecnico to the WMT 2023 Shared Task on Quality Estimation (QE). Our team participated on all tasks: sentence- and word-level quality prediction (task 1) and fine-grained error span detection (task 2). For all tasks, we build on the COMETKIWI-22 model (Rei et al., 2022b). Our multilingual approaches are ranked first for all tasks, reaching state-of-the-art performance for quality estimation at word-, span- and sentence-level granularity. Compared to the previous state-of-the-art COMETKIWI-22, we show large improvements in correlation with human judgements (up to 10 Spearman points). Moreover, we surpass the second-best multilingual submission to the shared-task with up to 3.8 absolute points.