 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
From TOWER to SPIRE: Adding the Speech Modality to a Text-Only LLM
Mar 13, 2025Large language models (LLMs) have shown remarkable performance and generalization capabilities across multiple languages and tasks, making them very attractive targets for multi-modality integration (e.g., images or speech). In this work, we extend an existing LLM to the speech modality via speech discretization and continued pre-training. In particular, we are interested in multilingual LLMs, such as TOWER, as their pre-training setting allows us to treat discretized speech input as an additional translation language. The resulting open-source model, SPIRE, is able to transcribe and translate English speech input while maintaining TOWER's original performance on translation-related tasks, showcasing that discretized speech input integration as an additional language is feasible during LLM adaptation. We make our code and models available to the community.
Did Translation Models Get More Robust Without Anyone Even Noticing?
Mar 06, 2024


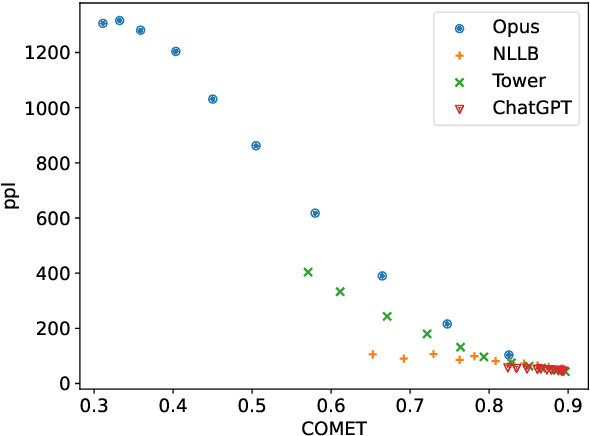
Neural machine translation (MT) models achieve strong results across a variety of settings, but it is widely believed that they are highly sensitive to "noisy" inputs, such as spelling errors, abbreviations, and other formatting issues. In this paper, we revisit this insight in light of recent multilingual MT models and large language models (LLMs) applied to machine translation. Somewhat surprisingly, we show through controlled experiments that these models are far more robust to many kinds of noise than previous models, even when they perform similarly on clean data. This is notable because, even though LLMs have more parameters and more complex training processes than past models, none of the open ones we consider use any techniques specifically designed to encourage robustness. Next, we show that similar trends hold for social media translation experiments -- LLMs are more robust to social media text. We include an analysis of the circumstances in which source correction techniques can be used to mitigate the effects of noise. Altogether, we show that robustness to many types of noise has increased.
Tower: An Open Multilingual Large Language Model for Translation-Related Tasks
Feb 27, 2024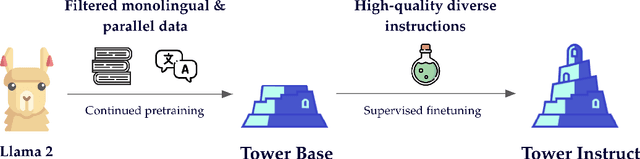



While general-purpose large language models (LLMs) demonstrate proficiency on multiple tasks within the domain of translation, approaches based on open LLMs are competitive only when specializing on a single task. In this paper, we propose a recipe for tailoring LLMs to multiple tasks present in translation workflows. We perform continued pretraining on a multilingual mixture of monolingual and parallel data, creating TowerBase, followed by finetuning on instructions relevant for translation processes, creating TowerInstruct. Our final model surpasses open alternatives on several tasks relevant to translation workflows and is competitive with general-purpose closed LLMs. To facilitate future research, we release the Tower models, our specialization dataset, an evaluation framework for LLMs focusing on the translation ecosystem, and a collection of model generations, including ours, on our benchmark.
Smoothing and Shrinking the Sparse Seq2Seq Search Space
Mar 18, 2021

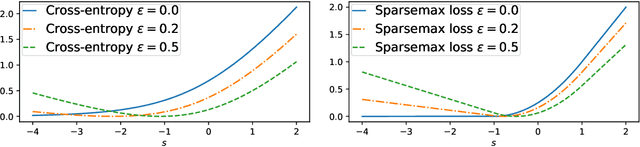
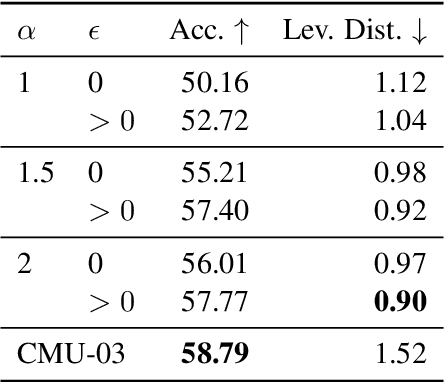
Current sequence-to-sequence models are trained to minimize cross-entropy and use softmax to compute the locally normalized probabilities over target sequences. While this setup has led to strong results in a variety of tasks, one unsatisfying aspect is its length bias: models give high scores to short, inadequate hypotheses and often make the empty string the argmax -- the so-called cat got your tongue problem. Recently proposed entmax-based sparse sequence-to-sequence models present a possible solution, since they can shrink the search space by assigning zero probability to bad hypotheses, but their ability to handle word-level tasks with transformers has never been tested. In this work, we show that entmax-based models effectively solve the cat got your tongue problem, removing a major source of model error for neural machine translation. In addition, we generalize label smoothing, a critical regularization technique, to the broader family of Fenchel-Young losses, which includes both cross-entropy and the entmax losses. Our resulting label-smoothed entmax loss models set a new state of the art on multilingual grapheme-to-phoneme conversion and deliver improvements and better calibration properties on cross-lingual morphological inflection and machine translation for 6 language pairs.
Sparse Sequence-to-Sequence Models
May 14, 2019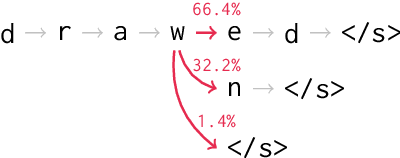



Sequence-to-sequence models are a powerful workhorse of NLP. Most variants employ a softmax transformation in both their attention mechanism and output layer, leading to dense alignments and strictly positive output probabilities. This density is wasteful, making models less interpretable and assigning probability mass to many implausible outputs. In this paper, we propose sparse sequence-to-sequence models, rooted in a new family of $\alpha$-entmax transformations, which includes softmax and sparsemax as particular cases, and is sparse for any $\alpha > 1$. We provide fast algorithms to evaluate these transformations and their gradients, which scale well for large vocabulary sizes. Our models are able to produce sparse alignments and to assign nonzero probability to a short list of plausible outputs, sometimes rendering beam search exact. Experiments on morphological inflection and machine translation reveal consistent gains over dense models.
Massively Multilingual Neural Grapheme-to-Phoneme Conversion
Aug 04, 2017


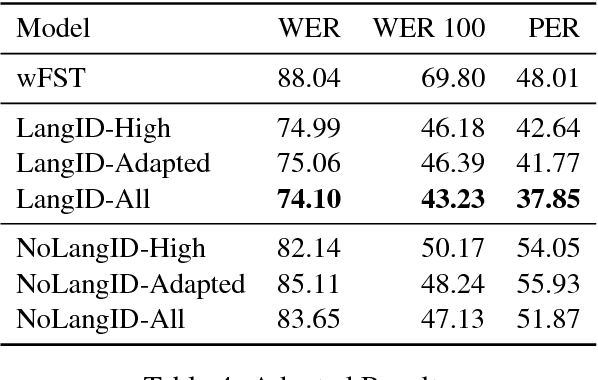
Grapheme-to-phoneme conversion (g2p) is necessary for text-to-speech and automatic speech recognition systems. Most g2p systems are monolingual: they require language-specific data or handcrafting of rules. Such systems are difficult to extend to low resource languages, for which data and handcrafted rules are not available. As an alternative, we present a neural sequence-to-sequence approach to g2p which is trained on spelling--pronunciation pairs in hundreds of languages. The system shares a single encoder and decoder across all languages, allowing it to utilize the intrinsic similarities between different writing systems. We show an 11% improvement in phoneme error rate over an approach based on adapting high-resource monolingual g2p models to low-resource languages. Our model is also much more compact relative to previous approaches.