 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothing and Shrinking the Sparse Seq2Seq Search Space
Paper and Code


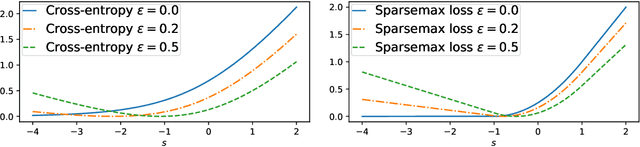
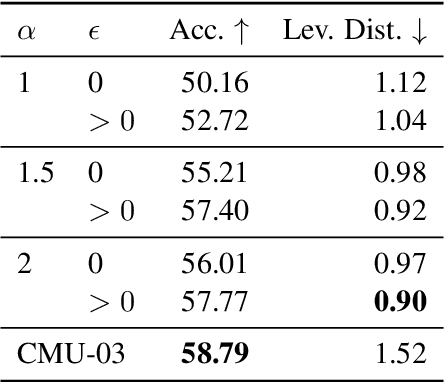
Current sequence-to-sequence models are trained to minimize cross-entropy and use softmax to compute the locally normalized probabilities over target sequences. While this setup has led to strong results in a variety of tasks, one unsatisfying aspect is its length bias: models give high scores to short, inadequate hypotheses and often make the empty string the argmax -- the so-called cat got your tongue problem. Recently proposed entmax-based sparse sequence-to-sequence models present a possible solution, since they can shrink the search space by assigning zero probability to bad hypotheses, but their ability to handle word-level tasks with transformers has never been tested. In this work, we show that entmax-based models effectively solve the cat got your tongue problem, removing a major source of model error for neural machine translation. In addition, we generalize label smoothing, a critical regularization technique, to the broader family of Fenchel-Young losses, which includes both cross-entropy and the entmax losses. Our resulting label-smoothed entmax loss models set a new state of the art on multilingual grapheme-to-phoneme conversion and deliver improvements and better calibration properties on cross-lingual morphological inflection and machine translation for 6 language pairs.