 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Instruction-Following Through Minimum Bayes Risk
Oct 07, 2024General-purpose LLM judges capable of human-level evaluation provide not only a scalable and accurate way of evaluating instruction-following LLMs but also new avenues for supervising and improving their performance. One promising way of leveraging LLM judges for supervision is through Minimum Bayes Risk (MBR) decoding, which uses a reference-based evaluator to select a high-quality output from amongst a set of candidate outputs. In the first part of this work, we explore using MBR decoding as a method for improving the test-time performance of instruction-following LLMs. We find that MBR decoding with reference-based LLM judges substantially improves over greedy decoding, best-of-N decoding with reference-free judges and MBR decoding with lexical and embedding-based metrics on AlpacaEval and MT-Bench. These gains are consistent across LLMs with up to 70B parameters, demonstrating that smaller LLM judges can be used to supervise much larger LLMs. Then, seeking to retain the improvements from MBR decoding while mitigating additional test-time costs, we explore iterative self-training on MBR-decoded outputs. We find that self-training using Direct Preference Optimisation leads to significant performance gains, such that the self-trained models with greedy decoding generally match and sometimes exceed the performance of their base models with MBR decoding.
Synthetic Multimodal Question Generation
Jul 02, 2024



Multimodal Retrieval Augmented Generation (MMRAG) is a powerful approach to question-answering over multimodal documents. A key challenge with evaluating MMRAG is the paucity of high-quality datasets matching the question styles and modalities of interest. In light of this, we propose SMMQG, a synthetic data generation framework. SMMQG leverages interplay between a retriever, large language model (LLM) and large multimodal model (LMM) to generate question and answer pairs directly from multimodal documents, with the questions conforming to specified styles and modalities. We use SMMQG to generate an MMRAG dataset of 1024 questions over Wikipedia documents and evaluate state-of-the-art models using it, revealing insights into model performance that are attainable only through style- and modality-specific evaluation data. Next, we measure the quality of data produced by SMMQG via a human study. We find that the quality of our synthetic data is on par with the quality of the crowdsourced benchmark MMQA and that downstream evaluation results using both datasets strongly concur.
Expert-guided Regularization via Distance Metric Learning
Dec 09, 2019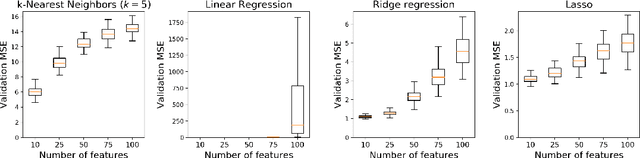

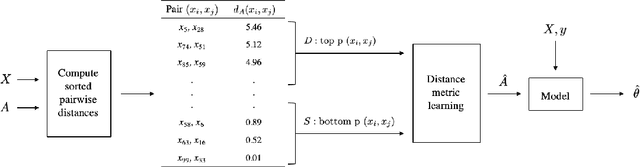
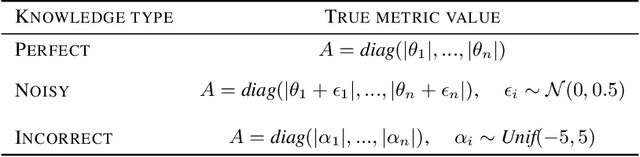
High-dimensional prediction is a challenging problem setting for traditional statistical models. Although regularization improves model performance in high dimensions, it does not sufficiently leverage knowledge on feature importances held by domain experts. As an alternative to standard regularization techniques, we propose Distance Metric Learning Regularization (DMLreg), an approach for eliciting prior knowledge from domain experts and integrating that knowledge into a regularized linear model. First, we learn a Mahalanobis distance metric between observations from pairwise similarity comparisons provided by an expert. Then, we use the learned distance metric to place prior distributions on coefficients in a linear model. Through experimental results on a simulated high-dimensional prediction problem, we show that DMLreg leads to improvements in model performance when the domain expert is knowledgeable.