 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexterous Point Policy: Learning Point-based Dexterous Hand Policies from Human Demonstrations
Jun 09, 2026Robotic foundation models pre-trained on human demonstration videos have shown promise, but a significant embodiment gap remains when the resulting policies are deployed on real robots. A common remedy is to fine-tune these models on robot-specific demonstrations. However, robot data collection can be prohibitively expensive and time-consuming, which is particularly acute in dexterous manipulation, e.g., teleoperating a multi-fingered hand for even a single atomic task can take days. To address this, we introduce Dexterous Point Policy, a framework that learns dexterous manipulation policies directly from human videos and requires no robot demonstrations. Our core insight is that a unified 3D keypoint representation can bridge human and robot embodiments when used for both observations and actions. Specifically, we extract 3D keypoints of task-relevant objects and human hands from raw videos, and train an autoregressive transformer over these keypoints. We observe that at the keypoint level, specifically the wrist and fingertips, human and robot behaviors closely align, enabling direct policy transfer. On a suite of real-robot tasks spanning pick-and-place and tool use, Dexterous Point Policy attains 75.0% success, whereas a state-of-the-art VLA baseline reaches only 1.0%. Furthermore, our method generalizes strongly to unseen scenarios, including multi-object environments and novel object categories.
RLDX-1 Technical Report
May 05, 2026While Vision-Language-Action models (VLAs) have shown remarkable progress toward human-like generalist robotic policies through the versatile intelligence (i.e. broad scene understanding and language-conditioned generalization) inherited from pre-trained Vision-Language Models, they still struggle with complex real-world tasks requiring broader functional capabilities (e.g. motion awareness, memory-aware decision making, and physical sensing). To address this, we introduce RLDX-1, a general-purpose robotic policy for dexterous manipulation built on the Multi-Stream Action Transformer (MSAT), an architecture that unifies these capabilities by integrating heterogeneous modalities through modality-specific streams with cross-modal joint self-attention. RLDX-1 further combines this architecture with system-level design choices, including synthesizing training data for rare manipulation scenarios, learning procedures specialized for human-like manipulation, and inference optimizations for real-time deployment. Through empirical evaluation, we show that RLDX-1 consistently outperforms recent frontier VLAs (e.g. $π_{0.5}$ and GR00T N1.6) across both simulation benchmarks and real-world tasks that require broad functional capabilities beyond general versatility. In particular, RLDX-1 shows superiority in ALLEX humanoid tasks by achieving success rates of 86.8% while $π_{0.5}$ and GR00T N1.6 achieve around 40%, highlighting the ability of RLDX-1 to control a high-DoF humanoid robot under diverse functional demands. Together, these results position RLDX-1 as a promising step toward reliable VLAs for complex, contact-rich, and dynamic real-world dexterous manipulation.
Embodied Agents Meet Personalization: Exploring Memory Utilization for Personalized Assistance
May 22, 2025Embodied agents empowered by large language models (LLMs) have shown strong performance in household object rearrangement tasks. However, these tasks primarily focus on single-turn interactions with simplified instructions, which do not truly reflect the challenges of providing meaningful assistance to users. To provide personalized assistance, embodied agents must understand the unique semantics that users assign to the physical world (e.g., favorite cup, breakfast routine) by leveraging prior interaction history to interpret dynamic, real-world instructions. Yet, the effectiveness of embodied agents in utilizing memory for personalized assistance remains largely underexplored. To address this gap, we present MEMENTO, a personalized embodied agent evaluation framework designed to comprehensively assess memory utilization capabilities to provide personalized assistance. Our framework consists of a two-stage memory evaluation process design that enables quantifying the impact of memory utilization on task performance. This process enables the evaluation of agents' understanding of personalized knowledge in object rearrangement tasks by focusing on its role in goal interpretation: (1) the ability to identify target objects based on personal meaning (object semantics), and (2) the ability to infer object-location configurations from consistent user patterns, such as routines (user patterns). Our experiments across various LLMs reveal significant limitations in memory utilization, with even frontier models like GPT-4o experiencing a 30.5% performance drop when required to reference multiple memories, particularly in tasks involving user patterns. These findings, along with our detailed analyses and case studies, provide valuable insights for future research in developing more effective personalized embodied agents. Project website: https://connoriginal.github.io/MEMENTO
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025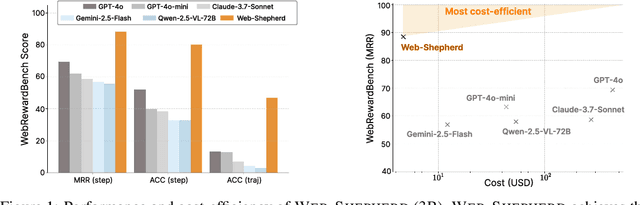


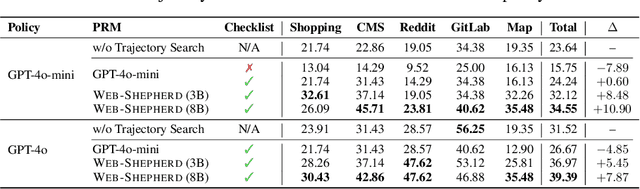
Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.
Coffee-Gym: An Environment for Evaluating and Improving Natural Language Feedback on Erroneous Code
Sep 29, 2024



This paper presents Coffee-Gym, a comprehensive RL environment for training models that provide feedback on code editing. Coffee-Gym includes two major components: (1) Coffee, a dataset containing humans' code edit traces for coding questions and machine-written feedback for editing erroneous code; (2) CoffeeEval, a reward function that faithfully reflects the helpfulness of feedback by assessing the performance of the revised code in unit tests. With them, Coffee-Gym addresses the unavailability of high-quality datasets for training feedback models with RL, and provides more accurate rewards than the SOTA reward model (i.e., GPT-4). By applying Coffee-Gym, we elicit feedback models that outperform baselines in enhancing open-source code LLMs' code editing, making them comparable with closed-source LLMs. We make the dataset and the model checkpoint publicly available.
Generative Unlearning for Any Identity
May 16, 2024



Recent advances in generative models trained on large-scale datasets have made it possible to synthesize high-quality samples across various domains. Moreover, the emergence of strong inversion networks enables not only a reconstruction of real-world images but also the modification of attributes through various editing methods. However, in certain domains related to privacy issues, e.g., human faces, advanced generative models along with strong inversion methods can lead to potential misuses. In this paper, we propose an essential yet under-explored task called generative identity unlearning, which steers the model not to generate an image of a specific identity. In the generative identity unlearning, we target the following objectives: (i) preventing the generation of images with a certain identity, and (ii) preserving the overall quality of the generative model. To satisfy these goals, we propose a novel framework, Generative Unlearning for Any Identity (GUIDE), which prevents the reconstruction of a specific identity by unlearning the generator with only a single image. GUIDE consists of two parts: (i) finding a target point for optimization that un-identifies the source latent code and (ii) novel loss functions that facilitate the unlearning procedure while less affecting the learned distribution. Our extensive experiments demonstrate that our proposed method achieves state-of-the-art performance in the generative machine unlearning task. The code is available at https://github.com/KHU-AGI/GUIDE.
Can Large Language Models be Good Emotional Supporter? Mitigating Preference Bias on Emotional Support Conversation
Feb 20, 2024Emotional Support Conversation (ESC) is a task aimed at alleviating individuals' emotional distress through daily conversation. Given its inherent complexity and non-intuitive nature, ESConv dataset incorporates support strategies to facilitate the generation of appropriate responses. Recently, despite the remarkable conversational ability of large language models (LLMs), previous studies have suggested that they often struggle with providing useful emotional support. Hence, this work initially analyzes the results of LLMs on ESConv, revealing challenges in selecting the correct strategy and a notable preference for a specific strategy. Motivated by these, we explore the impact of the inherent preference in LLMs on providing emotional support, and consequently, we observe that exhibiting high preference for specific strategies hinders effective emotional support, aggravating its robustness in predicting the appropriate strategy. Moreover, we conduct a methodological study to offer insights into the necessary approaches for LLMs to serve as proficient emotional supporters. Our findings emphasize that (1) low preference for specific strategies hinders the progress of emotional support, (2) external assistance helps reduce preference bias, and (3) LLMs alone cannot become good emotional supporters. These insights suggest promising avenues for future research to enhance the emotional intelligence of LLMs.
Large Language Models are Clinical Reasoners: Reasoning-Aware Diagnosis Framework with Prompt-Generated Rationales
Dec 12, 2023Machine reasoning has made great progress in recent years owing to large language models (LLMs). In the clinical domain, however, most NLP-driven projects mainly focus on clinical classification or reading comprehension, and under-explore clinical reasoning for disease diagnosis due to the expensive rationale annotation with clinicians. In this work, we present a ``reasoning-aware'' diagnosis framework that rationalizes the diagnostic process via prompt-based learning in a time- and labor-efficient manner, and learns to reason over the prompt-generated rationales. Specifically, we address the clinical reasoning for disease diagnosis, where the LLM generates diagnostic rationales providing its insight on presented patient data and the reasoning path towards the diagnosis, namely Clinical Chain-of-Thought (Clinical CoT). We empirically demonstrate LLMs/LMs' ability of clinical reasoning via extensive experiments and analyses on both rationale generation and disease diagnosis in various settings. We further propose a novel set of criteria for evaluating machine-generated rationales' potential for real-world clinical settings, facilitating and benefiting future research in this area.
Coffee: Boost Your Code LLMs by Fixing Bugs with Feedback
Nov 13, 2023
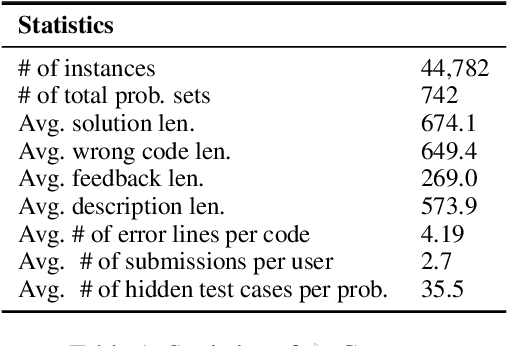


Code editing is an essential step towards reliable program synthesis to automatically correct critical errors generated from code LLMs. Recent studies have demonstrated that closed-source LLMs (i.e., ChatGPT and GPT-4) are capable of generating corrective feedback to edit erroneous inputs. However, it remains challenging for open-source code LLMs to generate feedback for code editing, since these models tend to adhere to the superficial formats of feedback and provide feedback with misleading information. Hence, the focus of our work is to leverage open-source code LLMs to generate helpful feedback with correct guidance for code editing. To this end, we present Coffee, a collected dataset specifically designed for code fixing with feedback. Using this dataset, we construct CoffeePots, a framework for COde Fixing with FEEdback via Preference-Optimized Tuning and Selection. The proposed framework aims to automatically generate helpful feedback for code editing while minimizing the potential risk of superficial feedback. The combination of Coffee and CoffeePots marks a significant advancement, achieving state-of-the-art performance on HumanEvalFix benchmark. Codes and model checkpoints are publicly available at https://github.com/Lune-Blue/COFFEE.
IntereStyle: Encoding an Interest Region for Robust StyleGAN Inversion
Sep 22, 2022


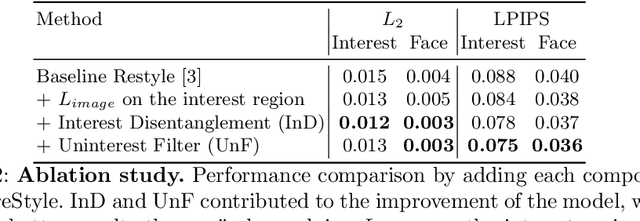
Recently, manipulation of real-world images has been highly elaborated along with the development of Generative Adversarial Networks (GANs) and corresponding encoders, which embed real-world images into the latent space. However, designing encoders of GAN still remains a challenging task due to the trade-off between distortion and perception. In this paper, we point out that the existing encoders try to lower the distortion not only on the interest region, e.g., human facial region but also on the uninterest region, e.g., background patterns and obstacles. However, most uninterest regions in real-world images are located at out-of-distribution (OOD), which are infeasible to be ideally reconstructed by generative models. Moreover, we empirically find that the uninterest region overlapped with the interest region can mangle the original feature of the interest region, e.g., a microphone overlapped with a facial region is inverted into the white beard. As a result, lowering the distortion of the whole image while maintaining the perceptual quality is very challenging. To overcome this trade-off, we propose a simple yet effective encoder training scheme, coined IntereStyle, which facilitates encoding by focusing on the interest region. IntereStyle steers the encoder to disentangle the encodings of the interest and uninterest regions. To this end, we filter the information of the uninterest region iteratively to regulate the negative impact of the uninterest region. We demonstrate that IntereStyle achieves both lower distortion and higher perceptual quality compared to the existing state-of-the-art encoders. Especially, our model robustly conserves features of the original images, which shows the robust image editing and style mixing results. We will release our code with the pre-trained model after the review.