 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoffee-Gym: An Environment for Evaluating and Improving Natural Language Feedback on Erroneous Code
Sep 29, 2024



This paper presents Coffee-Gym, a comprehensive RL environment for training models that provide feedback on code editing. Coffee-Gym includes two major components: (1) Coffee, a dataset containing humans' code edit traces for coding questions and machine-written feedback for editing erroneous code; (2) CoffeeEval, a reward function that faithfully reflects the helpfulness of feedback by assessing the performance of the revised code in unit tests. With them, Coffee-Gym addresses the unavailability of high-quality datasets for training feedback models with RL, and provides more accurate rewards than the SOTA reward model (i.e., GPT-4). By applying Coffee-Gym, we elicit feedback models that outperform baselines in enhancing open-source code LLMs' code editing, making them comparable with closed-source LLMs. We make the dataset and the model checkpoint publicly available.
Coffee: Boost Your Code LLMs by Fixing Bugs with Feedback
Nov 13, 2023
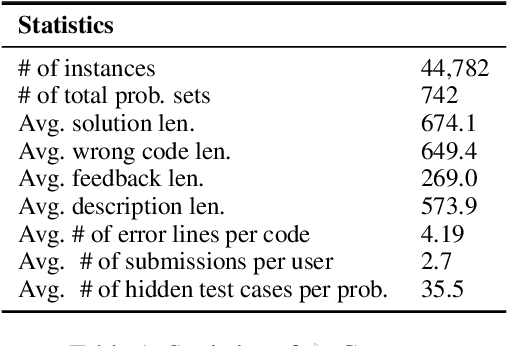


Code editing is an essential step towards reliable program synthesis to automatically correct critical errors generated from code LLMs. Recent studies have demonstrated that closed-source LLMs (i.e., ChatGPT and GPT-4) are capable of generating corrective feedback to edit erroneous inputs. However, it remains challenging for open-source code LLMs to generate feedback for code editing, since these models tend to adhere to the superficial formats of feedback and provide feedback with misleading information. Hence, the focus of our work is to leverage open-source code LLMs to generate helpful feedback with correct guidance for code editing. To this end, we present Coffee, a collected dataset specifically designed for code fixing with feedback. Using this dataset, we construct CoffeePots, a framework for COde Fixing with FEEdback via Preference-Optimized Tuning and Selection. The proposed framework aims to automatically generate helpful feedback for code editing while minimizing the potential risk of superficial feedback. The combination of Coffee and CoffeePots marks a significant advancement, achieving state-of-the-art performance on HumanEvalFix benchmark. Codes and model checkpoints are publicly available at https://github.com/Lune-Blue/COFFEE.
Dialogue Chain-of-Thought Distillation for Commonsense-aware Conversational Agents
Oct 22, 2023

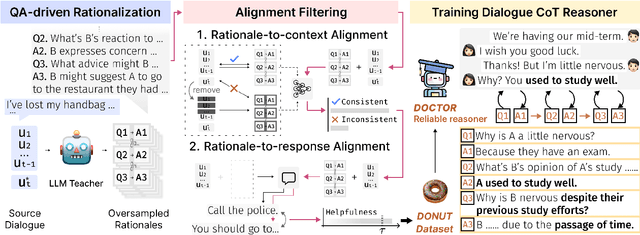

Human-like chatbots necessitate the use of commonsense reasoning in order to effectively comprehend and respond to implicit information present within conversations. Achieving such coherence and informativeness in responses, however, is a non-trivial task. Even for large language models (LLMs), the task of identifying and aggregating key evidence within a single hop presents a substantial challenge. This complexity arises because such evidence is scattered across multiple turns in a conversation, thus necessitating integration over multiple hops. Hence, our focus is to facilitate such multi-hop reasoning over a dialogue context, namely dialogue chain-of-thought (CoT) reasoning. To this end, we propose a knowledge distillation framework that leverages LLMs as unreliable teachers and selectively distills consistent and helpful rationales via alignment filters. We further present DOCTOR, a DialOgue Chain-of-ThOught Reasoner that provides reliable CoT rationales for response generation. We conduct extensive experiments to show that enhancing dialogue agents with high-quality rationales from DOCTOR significantly improves the quality of their responses.
Revisiting Dense Retrieval with Unanswerable Counterfactuals
Apr 12, 2023The retriever-reader framework is popular for open-domain question answering (ODQA), where a retriever samples for the reader a set of relevant candidate passages from a large corpus. A key assumption behind this method is that high relevance scores from the retriever likely indicate high answerability from the reader, which implies a high probability that the retrieved passages contain answers to a given question. In this work, we empirically dispel this belief and observe that recent dense retrieval models based on DPR often rank unanswerable counterfactual passages higher than their answerable original passages. To address such answer-unawareness in dense retrievers, we seek to use counterfactual samples as additional training resources to better synchronize the relevance measurement of DPR with the answerability of question-passage pairs. Specifically, we present counterfactually-Pivoting Contrastive Learning (PiCL), a novel representation learning approach for passage retrieval that leverages counterfactual samples as pivots between positive and negative samples in their learned embedding space. We incorporate PiCL into the retriever training to show the effectiveness of PiCL on ODQA benchmarks and the robustness of the learned models.
BotsTalk: Machine-sourced Framework for Automatic Curation of Large-scale Multi-skill Dialogue Datasets
Oct 23, 2022To build open-domain chatbots that are able to use diverse communicative skills, we propose a novel framework BotsTalk, where multiple agents grounded to the specific target skills participate in a conversation to automatically annotate multi-skill dialogues. We further present Blended Skill BotsTalk (BSBT), a large-scale multi-skill dialogue dataset comprising 300K conversations. Through extensive experiments, we demonstrate that our dataset can be effective for multi-skill dialogue systems which require an understanding of skill blending as well as skill grounding. Our code and data are available at https://github.com/convei-lab/BotsTalk.