 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation
Oct 17, 2024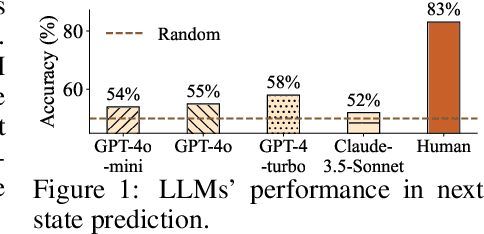
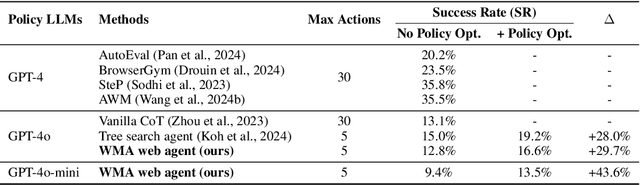
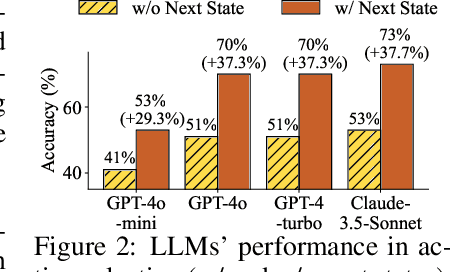

Large language models (LLMs) have recently gained much attention in building autonomous agents. However, the performance of current LLM-based web agents in long-horizon tasks is far from optimal, often yielding errors such as repeatedly buying a non-refundable flight ticket. By contrast, humans can avoid such an irreversible mistake, as we have an awareness of the potential outcomes (e.g., losing money) of our actions, also known as the "world model". Motivated by this, our study first starts with preliminary analyses, confirming the absence of world models in current LLMs (e.g., GPT-4o, Claude-3.5-Sonnet, etc.). Then, we present a World-model-augmented (WMA) web agent, which simulates the outcomes of its actions for better decision-making. To overcome the challenges in training LLMs as world models predicting next observations, such as repeated elements across observations and long HTML inputs, we propose a transition-focused observation abstraction, where the prediction objectives are free-form natural language descriptions exclusively highlighting important state differences between time steps. Experiments on WebArena and Mind2Web show that our world models improve agents' policy selection without training and demonstrate our agents' cost- and time-efficiency compared to recent tree-search-based agents.
Coffee-Gym: An Environment for Evaluating and Improving Natural Language Feedback on Erroneous Code
Sep 29, 2024



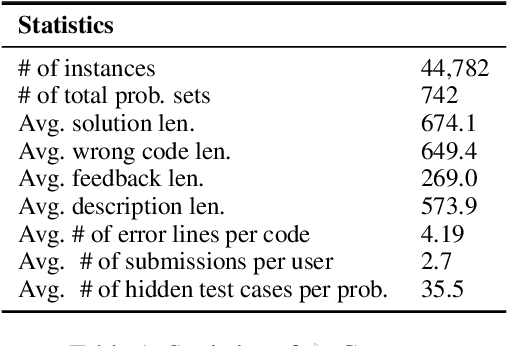
This paper presents Coffee-Gym, a comprehensive RL environment for training models that provide feedback on code editing. Coffee-Gym includes two major components: (1) Coffee, a dataset containing humans' code edit traces for coding questions and machine-written feedback for editing erroneous code; (2) CoffeeEval, a reward function that faithfully reflects the helpfulness of feedback by assessing the performance of the revised code in unit tests. With them, Coffee-Gym addresses the unavailability of high-quality datasets for training feedback models with RL, and provides more accurate rewards than the SOTA reward model (i.e., GPT-4). By applying Coffee-Gym, we elicit feedback models that outperform baselines in enhancing open-source code LLMs' code editing, making them comparable with closed-source LLMs. We make the dataset and the model checkpoint publicly available.
Large Language Models Are Self-Taught Reasoners: Enhancing LLM Applications via Tailored Problem-Solving Demonstrations
Aug 22, 2024Guiding large language models with a selected set of human-authored demonstrations is a common practice for improving LLM applications. However, human effort can be costly, especially in specialized domains (e.g., clinical diagnosis), and does not guarantee optimal performance due to the potential discrepancy of target skills between selected demonstrations and real test instances. Motivated by these, this paper explores the automatic creation of customized demonstrations, whose target skills align with the given target instance. We present SELF-TAUGHT, a problem-solving framework, which facilitates demonstrations that are "tailored" to the target problem and "filtered" for better quality (i.e., correctness) in a zero-shot manner. In 15 tasks of multiple-choice questions of diverse domains and the diagnosis of Alzheimer's disease (AD) with real-world patients, SELF-TAUGHT achieves superior performance to strong baselines (e.g., Few-shot CoT, Plan-and-Solve, Auto-CoT). We conduct comprehensive analyses on SELF-TAUGHT, including its generalizability to existing prompting methods and different LLMs, the quality of its intermediate generation, and more.
THEANINE: Revisiting Memory Management in Long-term Conversations with Timeline-augmented Response Generation
Jun 16, 2024



Large language models (LLMs) are capable of processing lengthy dialogue histories during prolonged interaction with users without additional memory modules; however, their responses tend to overlook or incorrectly recall information from the past. In this paper, we revisit memory-augmented response generation in the era of LLMs. While prior work focuses on getting rid of outdated memories, we argue that such memories can provide contextual cues that help dialogue systems understand the development of past events and, therefore, benefit response generation. We present Theanine, a framework that augments LLMs' response generation with memory timelines -- series of memories that demonstrate the development and causality of relevant past events. Along with Theanine, we introduce TeaFarm, a counterfactual-driven question-answering pipeline addressing the limitation of G-Eval in long-term conversations. Supplementary videos of our methods and the TeaBag dataset for TeaFarm evaluation are in https://theanine-693b0.web.app/.
Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models
Apr 03, 2024



Algorithmic reasoning refers to the ability to understand the complex patterns behind the problem and decompose them into a sequence of reasoning steps towards the solution. Such nature of algorithmic reasoning makes it a challenge for large language models (LLMs), even though they have demonstrated promising performance in other reasoning tasks. Within this context, some recent studies use programming languages (e.g., Python) to express the necessary logic for solving a given instance/question (e.g., Program-of-Thought) as inspired by their strict and precise syntaxes. However, it is non-trivial to write an executable code that expresses the correct logic on the fly within a single inference call. Also, the code generated specifically for an instance cannot be reused for others, even if they are from the same task and might require identical logic to solve. This paper presents Think-and-Execute, a novel framework that decomposes the reasoning process of language models into two steps. (1) In Think, we discover a task-level logic that is shared across all instances for solving a given task and then express the logic with pseudocode; (2) In Execute, we further tailor the generated pseudocode to each instance and simulate the execution of the code. With extensive experiments on seven algorithmic reasoning tasks, we demonstrate the effectiveness of Think-and-Execute. Our approach better improves LMs' reasoning compared to several strong baselines performing instance-specific reasoning (e.g., CoT and PoT), suggesting the helpfulness of discovering task-level logic. Also, we show that compared to natural language, pseudocode can better guide the reasoning of LMs, even though they are trained to follow natural language instructions.
Commonsense-augmented Memory Construction and Management in Long-term Conversations via Context-aware Persona Refinement
Jan 29, 2024



Memorizing and utilizing speakers' personas is a common practice for response generation in long-term conversations. Yet, human-authored datasets often provide uninformative persona sentences that hinder response quality. This paper presents a novel framework that leverages commonsense-based persona expansion to address such issues in long-term conversation. While prior work focuses on not producing personas that contradict others, we focus on transforming contradictory personas into sentences that contain rich speaker information, by refining them based on their contextual backgrounds with designed strategies. As the pioneer of persona expansion in multi-session settings, our framework facilitates better response generation via human-like persona refinement. The supplementary video of our work is available at https://caffeine-15bbf.web.app/.
Large Language Models are Clinical Reasoners: Reasoning-Aware Diagnosis Framework with Prompt-Generated Rationales
Dec 12, 2023Machine reasoning has made great progress in recent years owing to large language models (LLMs). In the clinical domain, however, most NLP-driven projects mainly focus on clinical classification or reading comprehension, and under-explore clinical reasoning for disease diagnosis due to the expensive rationale annotation with clinicians. In this work, we present a ``reasoning-aware'' diagnosis framework that rationalizes the diagnostic process via prompt-based learning in a time- and labor-efficient manner, and learns to reason over the prompt-generated rationales. Specifically, we address the clinical reasoning for disease diagnosis, where the LLM generates diagnostic rationales providing its insight on presented patient data and the reasoning path towards the diagnosis, namely Clinical Chain-of-Thought (Clinical CoT). We empirically demonstrate LLMs/LMs' ability of clinical reasoning via extensive experiments and analyses on both rationale generation and disease diagnosis in various settings. We further propose a novel set of criteria for evaluating machine-generated rationales' potential for real-world clinical settings, facilitating and benefiting future research in this area.
Coffee: Boost Your Code LLMs by Fixing Bugs with Feedback
Nov 13, 2023


Code editing is an essential step towards reliable program synthesis to automatically correct critical errors generated from code LLMs. Recent studies have demonstrated that closed-source LLMs (i.e., ChatGPT and GPT-4) are capable of generating corrective feedback to edit erroneous inputs. However, it remains challenging for open-source code LLMs to generate feedback for code editing, since these models tend to adhere to the superficial formats of feedback and provide feedback with misleading information. Hence, the focus of our work is to leverage open-source code LLMs to generate helpful feedback with correct guidance for code editing. To this end, we present Coffee, a collected dataset specifically designed for code fixing with feedback. Using this dataset, we construct CoffeePots, a framework for COde Fixing with FEEdback via Preference-Optimized Tuning and Selection. The proposed framework aims to automatically generate helpful feedback for code editing while minimizing the potential risk of superficial feedback. The combination of Coffee and CoffeePots marks a significant advancement, achieving state-of-the-art performance on HumanEvalFix benchmark. Codes and model checkpoints are publicly available at https://github.com/Lune-Blue/COFFEE.
Dialogue Chain-of-Thought Distillation for Commonsense-aware Conversational Agents
Oct 22, 2023

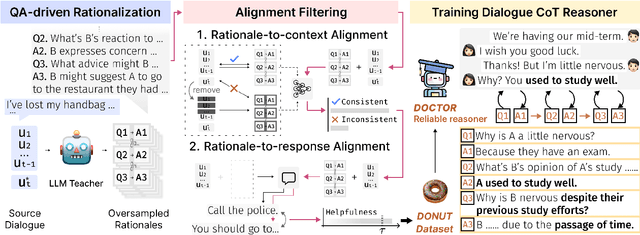

Human-like chatbots necessitate the use of commonsense reasoning in order to effectively comprehend and respond to implicit information present within conversations. Achieving such coherence and informativeness in responses, however, is a non-trivial task. Even for large language models (LLMs), the task of identifying and aggregating key evidence within a single hop presents a substantial challenge. This complexity arises because such evidence is scattered across multiple turns in a conversation, thus necessitating integration over multiple hops. Hence, our focus is to facilitate such multi-hop reasoning over a dialogue context, namely dialogue chain-of-thought (CoT) reasoning. To this end, we propose a knowledge distillation framework that leverages LLMs as unreliable teachers and selectively distills consistent and helpful rationales via alignment filters. We further present DOCTOR, a DialOgue Chain-of-ThOught Reasoner that provides reliable CoT rationales for response generation. We conduct extensive experiments to show that enhancing dialogue agents with high-quality rationales from DOCTOR significantly improves the quality of their responses.
Evidence-empowered Transfer Learning for Alzheimer's Disease
Mar 03, 2023
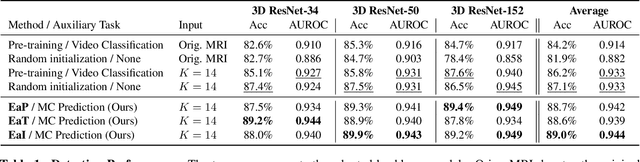
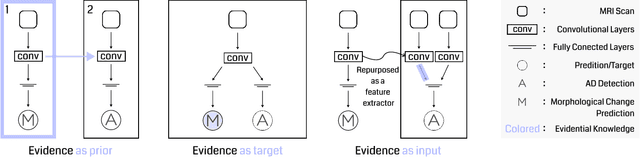

Transfer learning has been widely utilized to mitigate the data scarcity problem in the field of Alzheimer's disease (AD). Conventional transfer learning relies on re-using models trained on AD-irrelevant tasks such as natural image classification. However, it often leads to negative transfer due to the discrepancy between the non-medical source and target medical domains. To address this, we present evidence-empowered transfer learning for AD diagnosis. Unlike conventional approaches, we leverage an AD-relevant auxiliary task, namely morphological change prediction, without requiring additional MRI data. In this auxiliary task, the diagnosis model learns the evidential and transferable knowledge from morphological features in MRI scans. Experimental results demonstrate that our framework is not only effective in improving detection performance regardless of model capacity, but also more data-efficient and faithful.