 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePearl: A Review-driven Persona-Knowledge Grounded Conversational Recommendation Dataset
Mar 08, 2024



Conversational recommender system is an emerging area that has garnered an increasing interest in the community, especially with the advancements in large language models (LLMs) that enable diverse reasoning over conversational input. Despite the progress, the field has many aspects left to explore. The currently available public datasets for conversational recommendation lack specific user preferences and explanations for recommendations, hindering high-quality recommendations. To address such challenges, we present a novel conversational recommendation dataset named PEARL, synthesized with persona- and knowledge-augmented LLM simulators. We obtain detailed persona and knowledge from real-world reviews and construct a large-scale dataset with over 57k dialogues. Our experimental results demonstrate that utterances in PEARL include more specific user preferences, show expertise in the target domain, and provide recommendations more relevant to the dialogue context than those in prior datasets.
Commonsense-augmented Memory Construction and Management in Long-term Conversations via Context-aware Persona Refinement
Jan 29, 2024



Memorizing and utilizing speakers' personas is a common practice for response generation in long-term conversations. Yet, human-authored datasets often provide uninformative persona sentences that hinder response quality. This paper presents a novel framework that leverages commonsense-based persona expansion to address such issues in long-term conversation. While prior work focuses on not producing personas that contradict others, we focus on transforming contradictory personas into sentences that contain rich speaker information, by refining them based on their contextual backgrounds with designed strategies. As the pioneer of persona expansion in multi-session settings, our framework facilitates better response generation via human-like persona refinement. The supplementary video of our work is available at https://caffeine-15bbf.web.app/.
Evidence-empowered Transfer Learning for Alzheimer's Disease
Mar 03, 2023
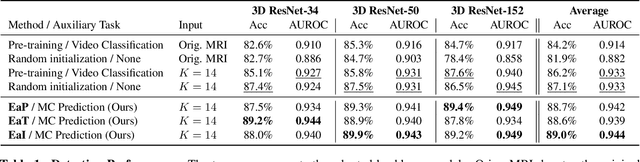
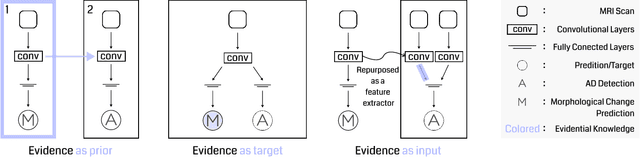

Transfer learning has been widely utilized to mitigate the data scarcity problem in the field of Alzheimer's disease (AD). Conventional transfer learning relies on re-using models trained on AD-irrelevant tasks such as natural image classification. However, it often leads to negative transfer due to the discrepancy between the non-medical source and target medical domains. To address this, we present evidence-empowered transfer learning for AD diagnosis. Unlike conventional approaches, we leverage an AD-relevant auxiliary task, namely morphological change prediction, without requiring additional MRI data. In this auxiliary task, the diagnosis model learns the evidential and transferable knowledge from morphological features in MRI scans. Experimental results demonstrate that our framework is not only effective in improving detection performance regardless of model capacity, but also more data-efficient and faithful.