 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupport for Stock Trend Prediction Using Transformers and Sentiment Analysis
May 18, 2023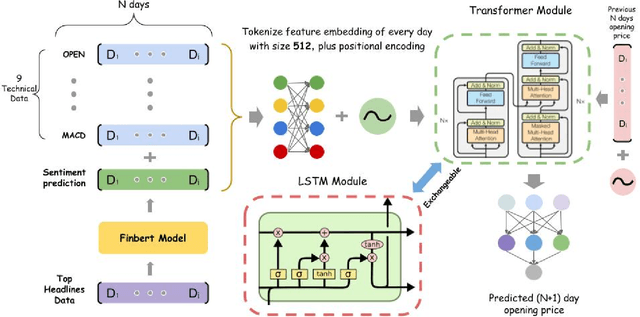
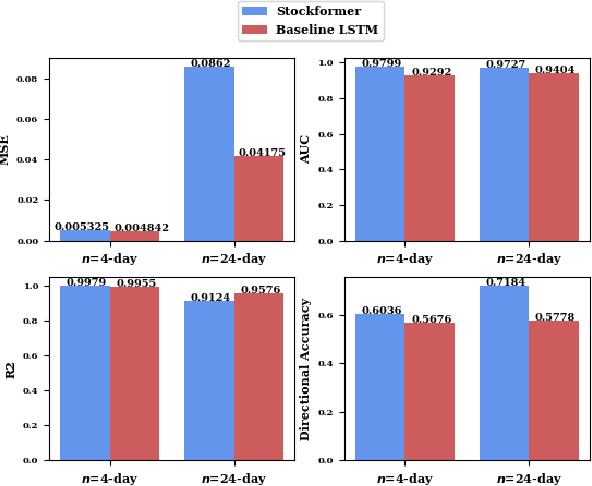
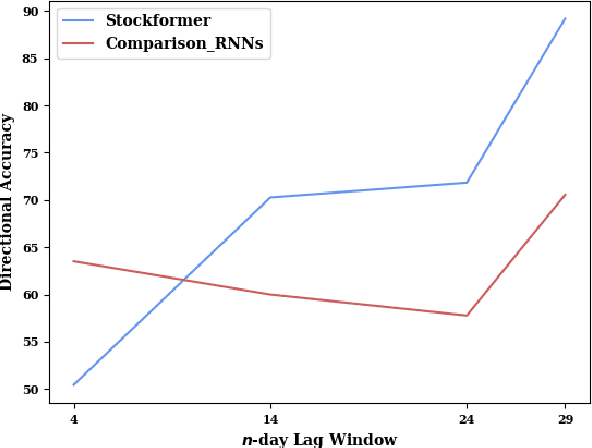

Stock trend analysis has been an influential time-series prediction topic due to its lucrative and inherently chaotic nature. Many models looking to accurately predict the trend of stocks have been based on Recurrent Neural Networks (RNNs). However, due to the limitations of RNNs, such as gradient vanish and long-term dependencies being lost as sequence length increases, in this paper we develop a Transformer based model that uses technical stock data and sentiment analysis to conduct accurate stock trend prediction over long time windows. This paper also introduces a novel dataset containing daily technical stock data and top news headline data spanning almost three years. Stock prediction based solely on technical data can suffer from lag caused by the inability of stock indicators to effectively factor in breaking market news. The use of sentiment analysis on top headlines can help account for unforeseen shifts in market conditions caused by news coverage. We measure the performance of our model against RNNs over sequence lengths spanning 5 business days to 30 business days to mimic different length trading strategies. This reveals an improvement in directional accuracy over RNNs as sequence length is increased, with the largest improvement being close to 18.63% at 30 business days.
Stock Trend Prediction: A Semantic Segmentation Approach
Mar 09, 2023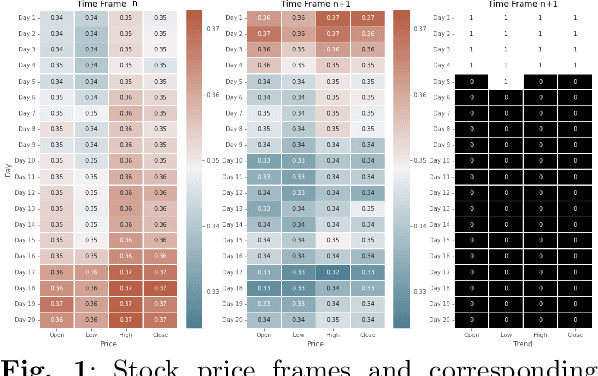
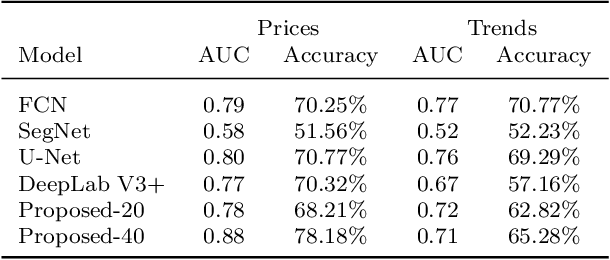
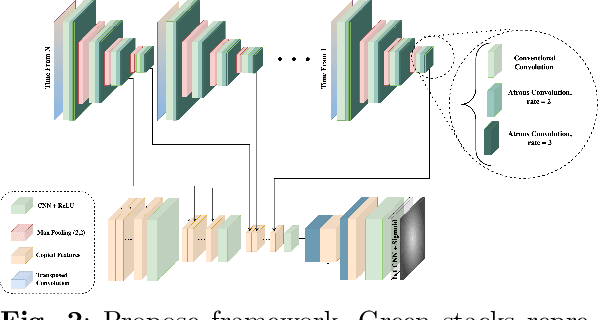
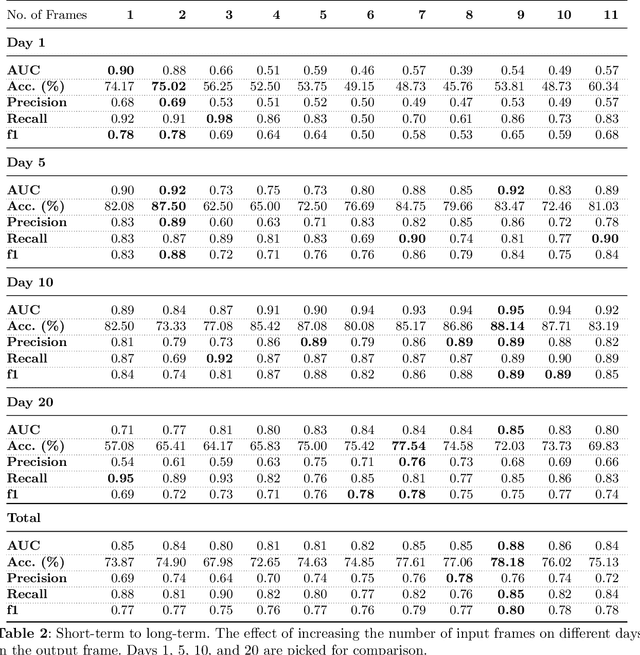
Market financial forecasting is a trending area in deep learning. Deep learning models are capable of tackling the classic challenges in stock market data, such as its extremely complicated dynamics as well as long-term temporal correlation. To capture the temporal relationship among these time series, recurrent neural networks are employed. However, it is difficult for recurrent models to learn to keep track of long-term information. Convolutional Neural Networks have been utilized to better capture the dynamics and extract features for both short- and long-term forecasting. However, semantic segmentation and its well-designed fully convolutional networks have never been studied for time-series dense classification. We present a novel approach to predict long-term daily stock price change trends with fully 2D-convolutional encoder-decoders. We generate input frames with daily prices for a time-frame of T days. The aim is to predict future trends by pixel-wise classification of the current price frame. We propose a hierarchical CNN structure to encode multiple price frames to multiscale latent representation in parallel using Atrous Spatial Pyramid Pooling blocks and take that temporal coarse feature stacks into account in the decoding stages. Our hierarchical structure of CNNs makes it capable of capturing both long and short-term temporal relationships effectively. The effect of increasing the input time horizon via incrementing parallel encoders has been studied with interesting and substantial changes in the output segmentation masks. We achieve overall accuracy and AUC of %78.18 and 0.88 for joint trend prediction over the next 20 days, surpassing other semantic segmentation approaches. We compared our proposed model with several deep models specifically designed for technical analysis and found that for different output horizons, our proposed models outperformed other models.
A Two-Stage Efficient 3-D CNN Framework for EEG Based Emotion Recognition
Jul 26, 2022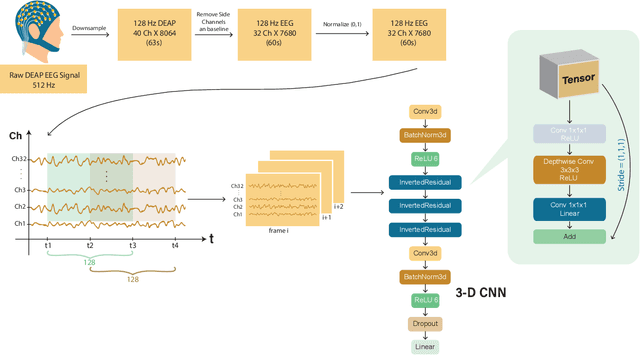
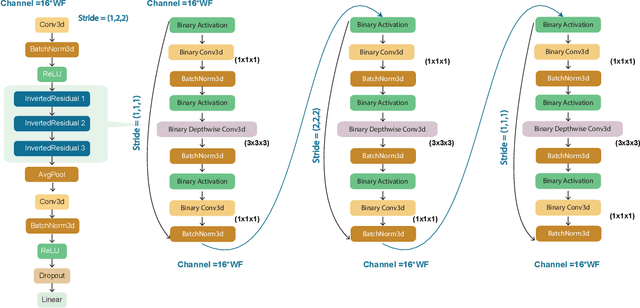
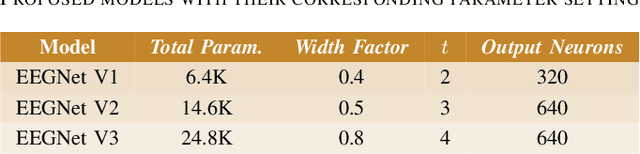
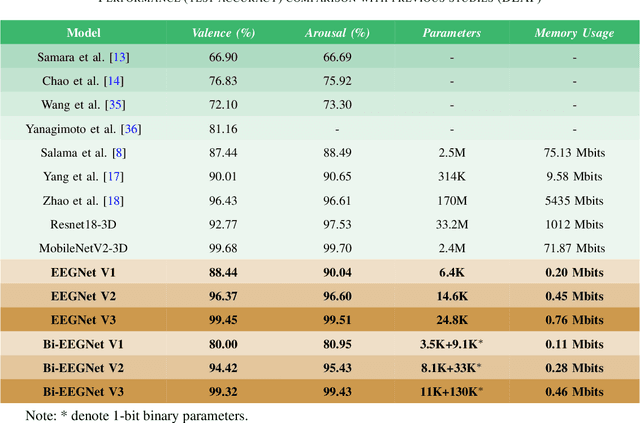
This paper proposes a novel two-stage framework for emotion recognition using EEG data that outperforms state-of-the-art models while keeping the model size small and computationally efficient. The framework consists of two stages; the first stage involves constructing efficient models named EEGNet, which is inspired by the state-of-the-art efficient architecture and employs inverted-residual blocks that contain depthwise separable convolutional layers. The EEGNet models on both valence and arousal labels achieve the average classification accuracy of 90%, 96.6%, and 99.5% with only 6.4k, 14k, and 25k parameters, respectively. In terms of accuracy and storage cost, these models outperform the previous state-of-the-art result by up to 9%. In the second stage, we binarize these models to further compress them and deploy them easily on edge devices. Binary Neural Networks (BNNs) typically degrade model accuracy. We improve the EEGNet binarized models in this paper by introducing three novel methods and achieving a 20\% improvement over the baseline binary models. The proposed binarized EEGNet models achieve accuracies of 81%, 95%, and 99% with storage costs of 0.11Mbits, 0.28Mbits, and 0.46Mbits, respectively. Those models help deploy a precise human emotion recognition system on the edge environment.
PLAM: a Posit Logarithm-Approximate Multiplier for Power Efficient Posit-based DNNs
Feb 18, 2021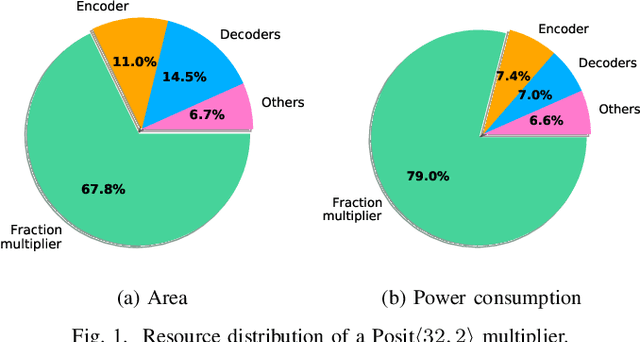

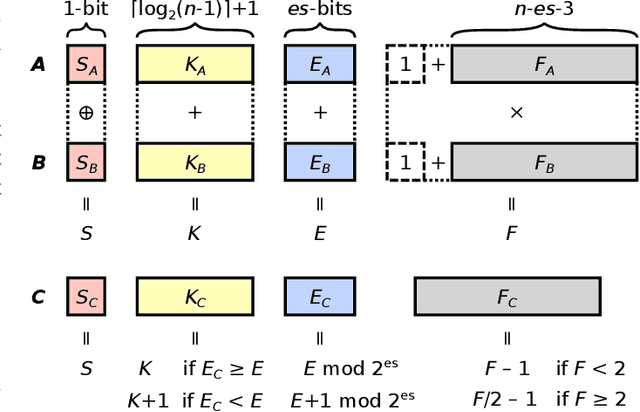
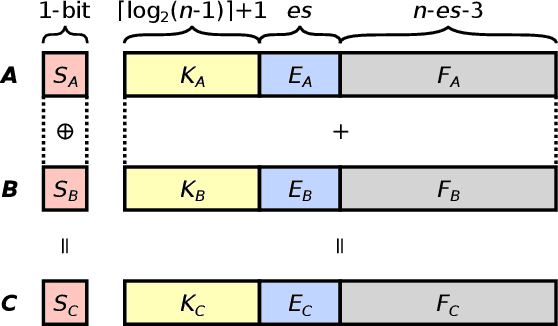
The Posit Number System was introduced in 2017 as a replacement for floating-point numbers. Since then, the community has explored its application in Neural Network related tasks and produced some unit designs which are still far from being competitive with their floating-point counterparts. This paper proposes a Posit Logarithm-Approximate Multiplication (PLAM) scheme to significantly reduce the complexity of posit multipliers, the most power-hungry units within Deep Neural Network architectures. When comparing with state-of-the-art posit multipliers, experiments show that the proposed technique reduces the area, power, and delay of hardware multipliers up to 72.86%, 81.79%, and 17.01%, respectively, without accuracy degradation.
Effects of Approximate Multiplication on Convolutional Neural Networks
Jul 20, 2020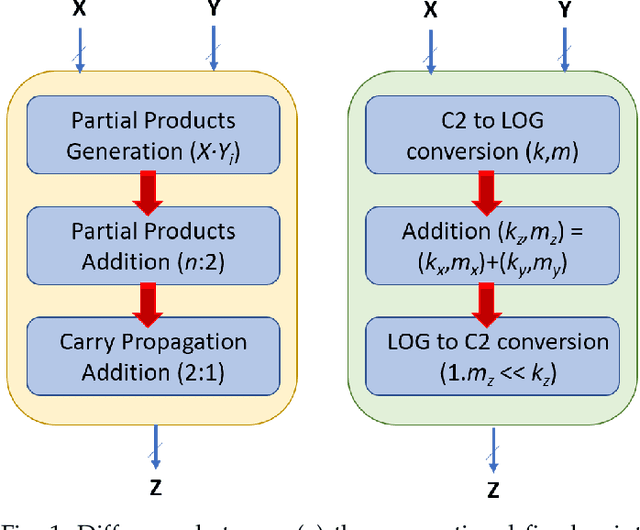
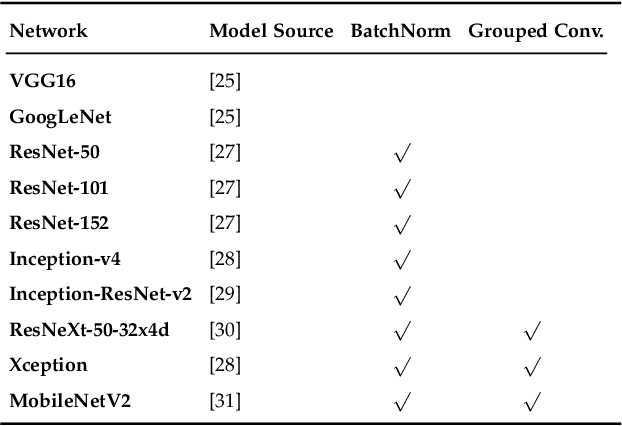
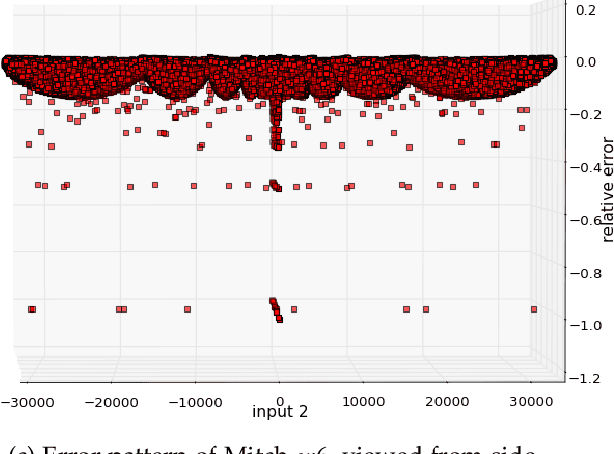

This paper analyzes the effects of approximate multiplication when performing inferences on deep convolutional neural networks (CNNs). The approximate multiplication can reduce the cost of underlying circuits so that CNN inferences can be performed more efficiently in hardware accelerators. The study identifies the critical factors in the convolution, fully-connected, and batch normalization layers that allow more accurate CNN predictions despite the errors from approximate multiplication. The same factors also provide an arithmetic explanation of why bfloat16 multiplication performs well on CNNs. The experiments are performed with recognized network architectures to show that the approximate multipliers can produce predictions that are nearly as accurate as the FP32 references, without additional training. For example, the ResNet and Inception-v4 models with Mitch-$w$6 multiplication produces Top-5 errors that are within 0.2% compared to the FP32 references. A brief cost comparison of Mitch-$w$6 against bfloat16 is presented, where a MAC operation saves up to 80% of energy compared to the bfloat16 arithmetic. The most far-reaching contribution of this paper is the analytical justification that multiplications can be approximated while additions need to be exact in CNN MAC operations.
Reliable and Energy Efficient MLC STT-RAM Buffer for CNN Accelerators
Jan 14, 2020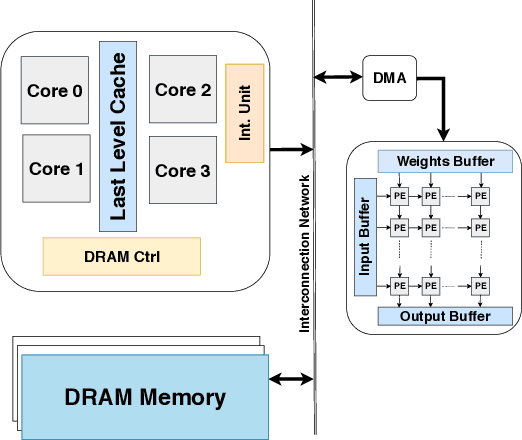
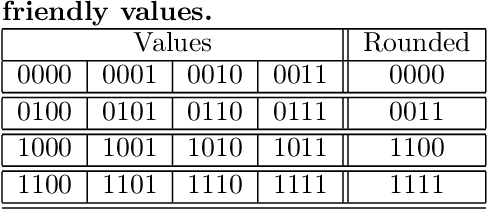
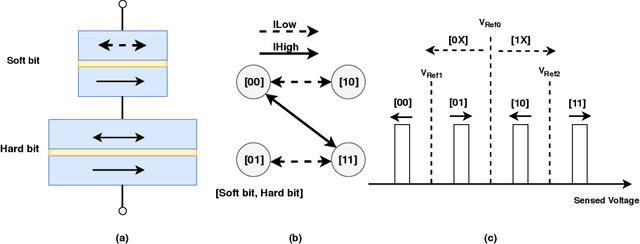
We propose a lightweight scheme where the formation of a data block is changed in such a way that it can tolerate soft errors significantly better than the baseline. The key insight behind our work is that CNN weights are normalized between -1 and 1 after each convolutional layer, and this leaves one bit unused in half-precision floating-point representation. By taking advantage of the unused bit, we create a backup for the most significant bit to protect it against the soft errors. Also, considering the fact that in MLC STT-RAMs the cost of memory operations (read and write), and reliability of a cell are content-dependent (some patterns take larger current and longer time, while they are more susceptible to soft error), we rearrange the data block to minimize the number of costly bit patterns. Combining these two techniques provides the same level of accuracy compared to an error-free baseline while improving the read and write energy by 9% and 6%, respectively.