 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Optimization of Machine Learning Prediction Queries
May 31, 2022
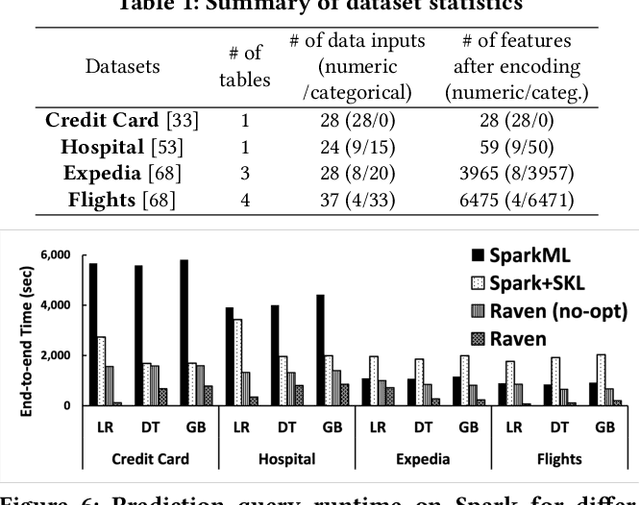
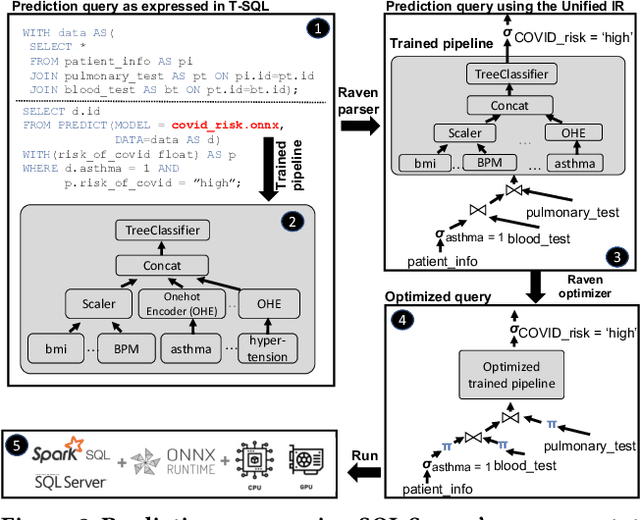
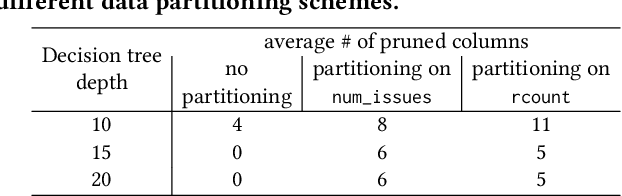
Prediction queries are widely used across industries to perform advanced analytics and draw insights from data. They include a data processing part (e.g., for joining, filtering, cleaning, featurizing the datasets) and a machine learning (ML) part invoking one or more trained models to perform predictions. These parts have so far been optimized in isolation, leaving significant opportunities for optimization unexplored. We present Raven, a production-ready system for optimizing prediction queries. Raven follows the enterprise architectural trend of collocating data and ML runtimes. It relies on a unified intermediate representation that captures both data and ML operators in a single graph structure to unlock two families of optimizations. First, it employs logical optimizations that pass information between the data part (and the properties of the underlying data) and the ML part to optimize each other. Second, it introduces logical-to-physical transformations that allow operators to be executed on different runtimes (relational, ML, and DNN) and hardware (CPU, GPU). Novel data-driven optimizations determine the runtime to be used for each part of the query to achieve optimal performance. Our evaluation shows that Raven improves performance of prediction queries on Apache Spark and SQL Server by up to 13.1x and 330x, respectively. For complex models where GPU acceleration is beneficial, Raven provides up to 8x speedup compared to state-of-the-art systems.
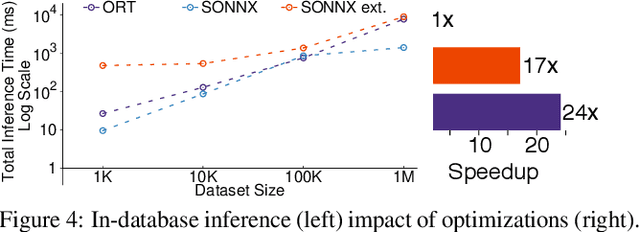
Query Processing on Tensor Computation Runtimes
Mar 03, 2022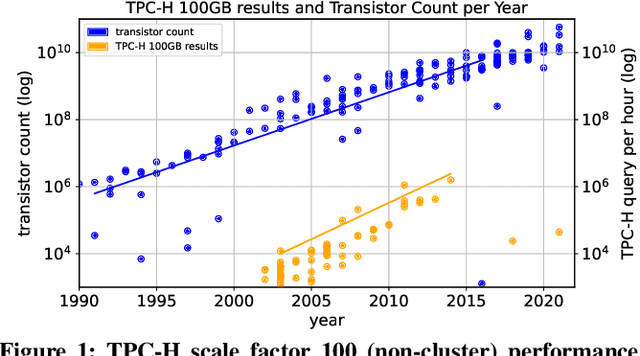

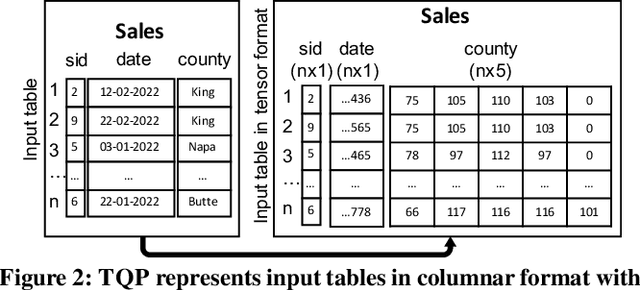
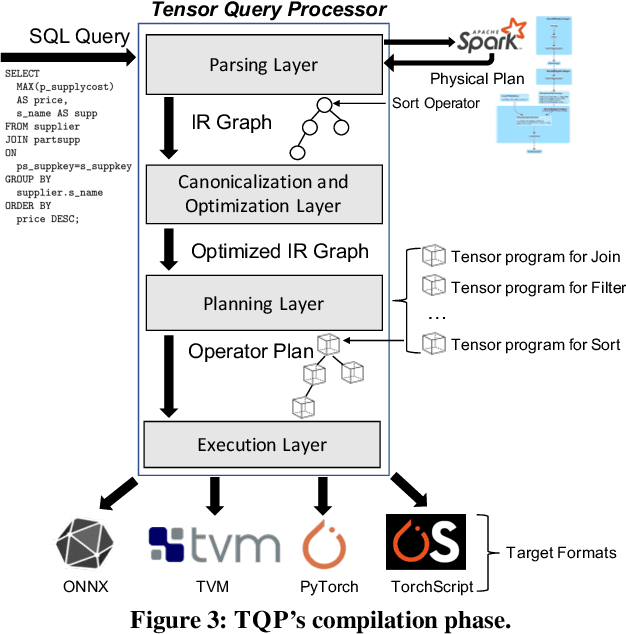
The huge demand for computation in artificial intelligence (AI) is driving unparalleled investments in new hardware and software systems for AI. This leads to an explosion in the number of specialized hardware devices, which are now part of the offerings of major cloud providers. Meanwhile, by hiding the low-level complexity through a tensor-based interface, tensor computation runtimes (TCRs) such as PyTorch allow data scientists to efficiently exploit the exciting capabilities offered by the new hardware. In this paper, we explore how databases can ride the wave of innovation happening in the AI space. Specifically, we present Tensor Query Processor (TQP): a SQL query processor leveraging the tensor interface of TCRs. TQP is able to efficiently run the full TPC-H benchmark by implementing novel algorithms for executing relational operators on the specialized tensor routines provided by TCRs. Meanwhile, TQP can target various hardware while only requiring a fraction of the usual development effort. Experiments show that TQP can improve query execution time by up to 20x over CPU-only systems, and up to 5x over specialized GPU solutions. Finally, TQP can accelerate queries mixing ML predictions and SQL end-to-end, and deliver up to 5x speedup over CPU baselines.
A Tensor Compiler for Unified Machine Learning Prediction Serving
Oct 19, 2020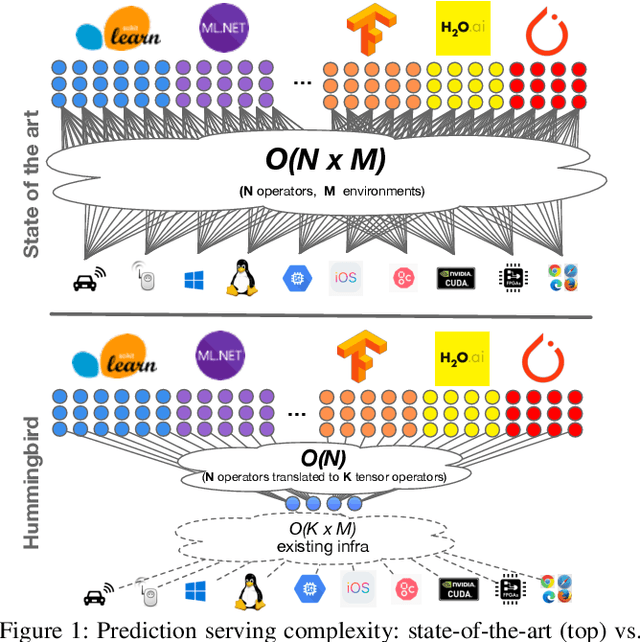

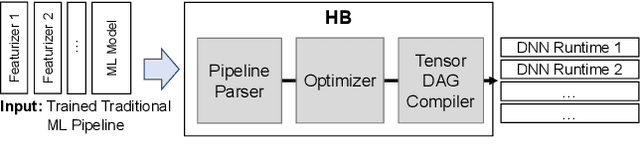

Machine Learning (ML) adoption in the enterprise requires simpler and more efficient software infrastructure---the bespoke solutions typical in large web companies are simply untenable. Model scoring, the process of obtaining predictions from a trained model over new data, is a primary contributor to infrastructure complexity and cost as models are trained once but used many times. In this paper we propose HUMMINGBIRD, a novel approach to model scoring, which compiles featurization operators and traditional ML models (e.g., decision trees) into a small set of tensor operations. This approach inherently reduces infrastructure complexity and directly leverages existing investments in Neural Network compilers and runtimes to generate efficient computations for both CPU and hardware accelerators. Our performance results are intriguing: despite replacing imperative computations (e.g., tree traversals) with tensor computation abstractions, HUMMINGBIRD is competitive and often outperforms hand-crafted kernels on micro-benchmarks on both CPU and GPU, while enabling seamless end-to-end acceleration of ML pipelines. We have released HUMMINGBIRD as open source.
Cloudy with high chance of DBMS: A 10-year prediction for Enterprise-Grade ML
Aug 30, 2019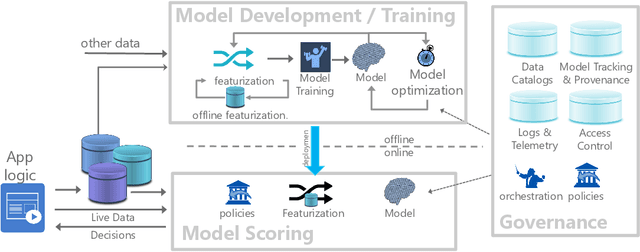
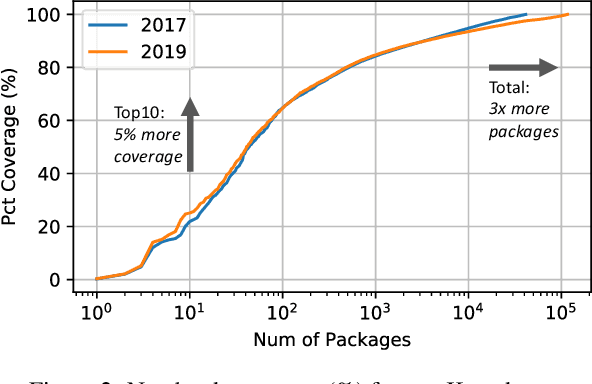
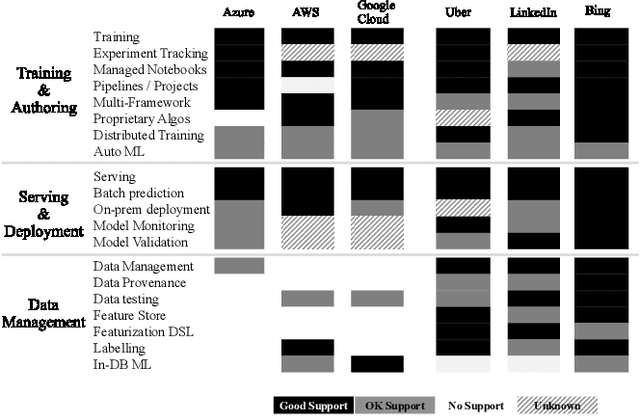
Machine learning (ML) has proven itself in high-value web applications such as search ranking and is emerging as a powerful tool in a much broader range of enterprise scenarios including voice recognition and conversational understanding for customer support, autotuning for videoconferencing, inteligent feedback loops in largescale sysops, manufacturing and autonomous vehicle management, complex financial predictions, just to name a few. Meanwhile, as the value of data is increasingly recognized and monetized, concerns about securing valuable data and risks to individual privacy have been growing. Consequently, rigorous data management has emerged as a key requirement in enterprise settings. How will these trends (ML growing popularity, and stricter data governance) intersect? What are the unmet requirements for applying ML in enterprise settings? What are the technical challenges for the DB community to solve? In this paper, we present our vision of how ML and database systems are likely to come together, and early steps we take towards making this vision a reality.