 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNexus: Inferring Join Graphs from Metadata Alone via Iterative Low-Rank Matrix Completion
Feb 09, 2026Automatically inferring join relationships is a critical task for effective data discovery, integration, querying and reuse. However, accurately and efficiently identifying these relationships in large and complex schemas can be challenging, especially in enterprise settings where access to data values is constrained. In this paper, we introduce the problem of join graph inference when only metadata is available. We conduct an empirical study on a large number of real-world schemas and observe that join graphs when represented as adjacency matrices exhibit two key properties: high sparsity and low-rank structure. Based on these novel observations, we formulate join graph inference as a low-rank matrix completion problem and propose Nexus, an end-to-end solution using only metadata. To further enhance accuracy, we propose a novel Expectation-Maximization algorithm that alternates between low-rank matrix completion and refining join candidate probabilities by leveraging Large Language Models. Our extensive experiments demonstrate that Nexus outperforms existing methods by a significant margin on four datasets including a real-world production dataset. Additionally, Nexus can operate in a fast mode, providing comparable results with up to 6x speedup, offering a practical and efficient solution for real-world deployments.
JoinBoost: Grow Trees Over Normalized Data Using Only SQL
Jul 01, 2023
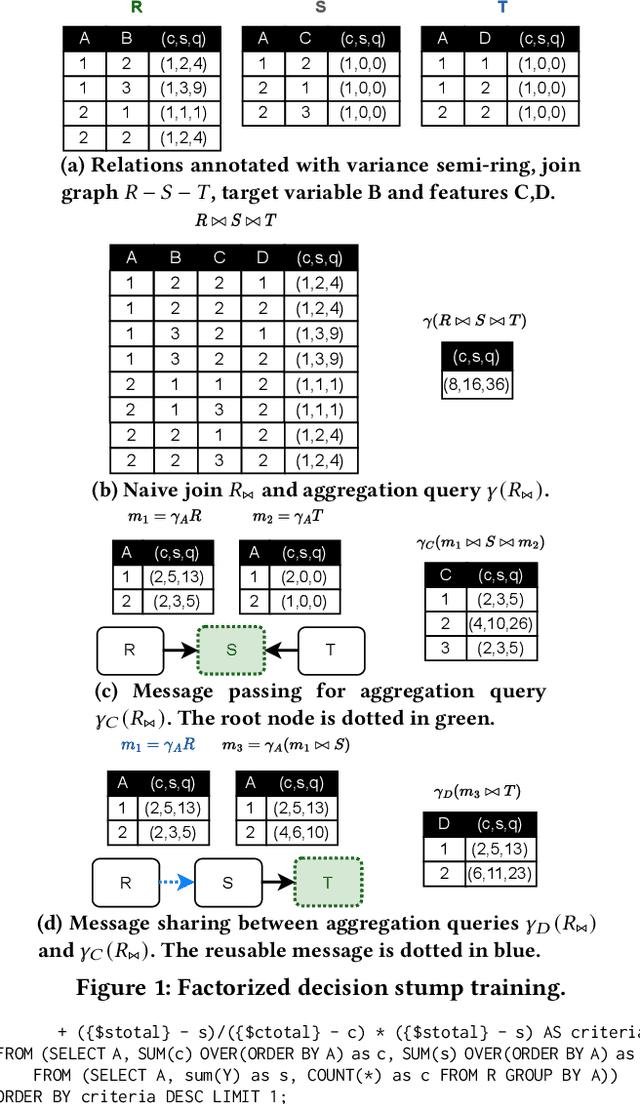
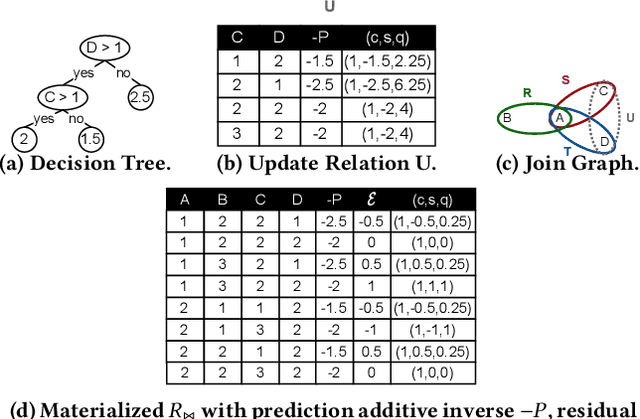

Although dominant for tabular data, ML libraries that train tree models over normalized databases (e.g., LightGBM, XGBoost) require the data to be denormalized as a single table, materialized, and exported. This process is not scalable, slow, and poses security risks. In-DB ML aims to train models within DBMSes to avoid data movement and provide data governance. Rather than modify a DBMS to support In-DB ML, is it possible to offer competitive tree training performance to specialized ML libraries...with only SQL? We present JoinBoost, a Python library that rewrites tree training algorithms over normalized databases into pure SQL. It is portable to any DBMS, offers performance competitive with specialized ML libraries, and scales with the underlying DBMS capabilities. JoinBoost extends prior work from both algorithmic and systems perspectives. Algorithmically, we support factorized gradient boosting, by updating the $Y$ variable to the residual in the non-materialized join result. Although this view update problem is generally ambiguous, we identify addition-to-multiplication preserving, the key property of variance semi-ring to support rmse, the most widely used criterion. System-wise, we identify residual updates as a performance bottleneck. Such overhead can be natively minimized on columnar DBMSes by creating a new column of residual values and adding it as a projection. We validate this with two implementations on DuckDB, with no or minimal modifications to its internals for portability. Our experiment shows that JoinBoost is 3x (1.1x) faster for random forests (gradient boosting) compared to LightGBM, and over an order magnitude faster than state-of-the-art In-DB ML systems. Further, JoinBoost scales well beyond LightGBM in terms of the # features, DB size (TPC-DS SF=1000), and join graph complexity (galaxy schemas).
The Tensor Data Platform: Towards an AI-centric Database System
Nov 04, 2022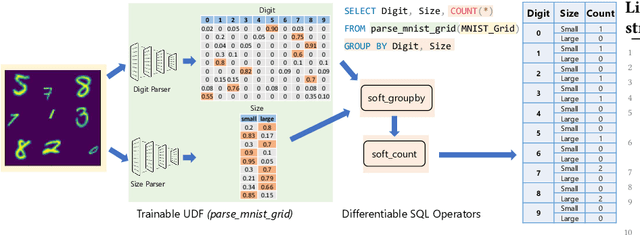
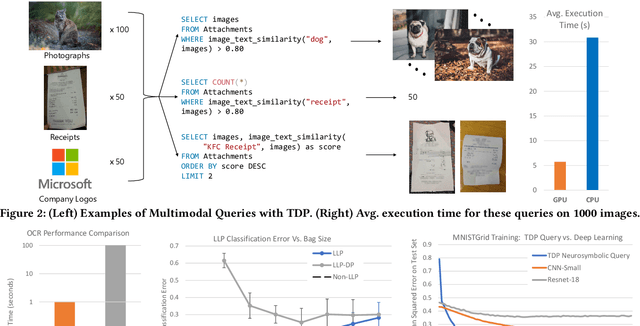
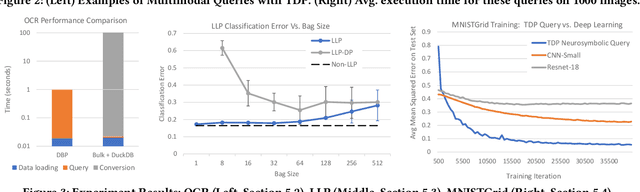
Database engines have historically absorbed many of the innovations in data processing, adding features to process graph data, XML, object oriented, and text among many others. In this paper, we make the case that it is time to do the same for AI -- but with a twist! While existing approaches have tried to achieve this by integrating databases with external ML tools, in this paper we claim that achieving a truly AI-centric database requires moving the DBMS engine, at its core, from a relational to a tensor abstraction. This allows us to: (1) support multi-modal data processing such as images, videos, audio, text as well as relational; (2) leverage the wellspring of innovation in HW and runtimes for tensor computation; and (3) exploit automatic differentiation to enable a novel class of "trainable" queries that can learn to perform a task. To support the above scenarios, we introduce TDP: a system that builds upon our prior work mapping relational queries to tensors. Thanks to a tighter integration with the tensor runtime, TDP is able to provide a broader coverage of new emerging scenarios requiring access to multi-modal data and automatic differentiation.
End-to-end Optimization of Machine Learning Prediction Queries
May 31, 2022
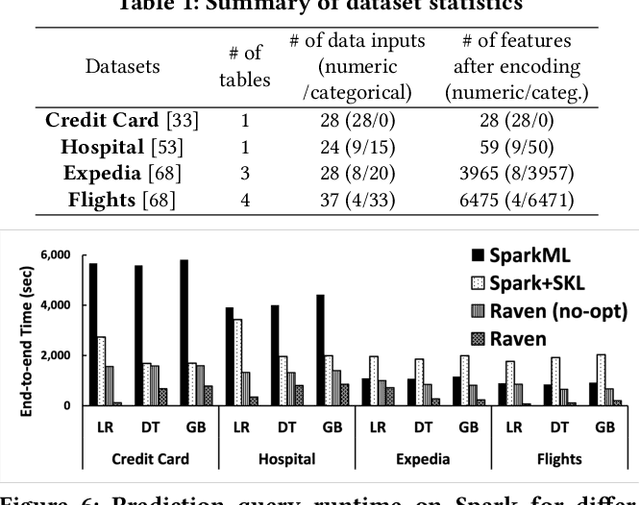
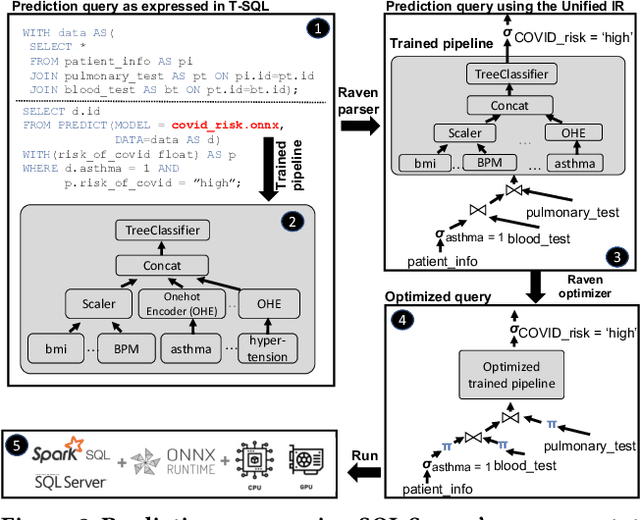
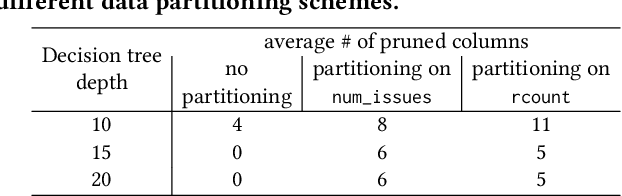
Prediction queries are widely used across industries to perform advanced analytics and draw insights from data. They include a data processing part (e.g., for joining, filtering, cleaning, featurizing the datasets) and a machine learning (ML) part invoking one or more trained models to perform predictions. These parts have so far been optimized in isolation, leaving significant opportunities for optimization unexplored. We present Raven, a production-ready system for optimizing prediction queries. Raven follows the enterprise architectural trend of collocating data and ML runtimes. It relies on a unified intermediate representation that captures both data and ML operators in a single graph structure to unlock two families of optimizations. First, it employs logical optimizations that pass information between the data part (and the properties of the underlying data) and the ML part to optimize each other. Second, it introduces logical-to-physical transformations that allow operators to be executed on different runtimes (relational, ML, and DNN) and hardware (CPU, GPU). Novel data-driven optimizations determine the runtime to be used for each part of the query to achieve optimal performance. Our evaluation shows that Raven improves performance of prediction queries on Apache Spark and SQL Server by up to 13.1x and 330x, respectively. For complex models where GPU acceleration is beneficial, Raven provides up to 8x speedup compared to state-of-the-art systems.
Query Processing on Tensor Computation Runtimes
Mar 03, 2022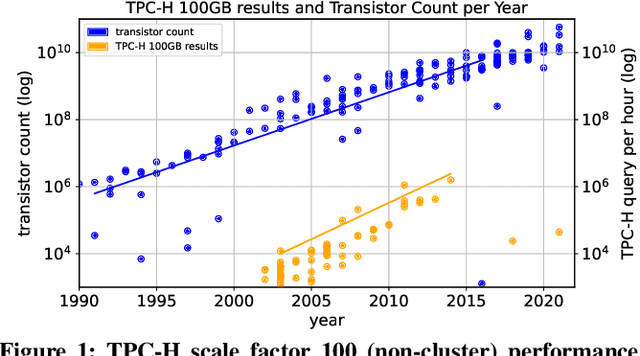

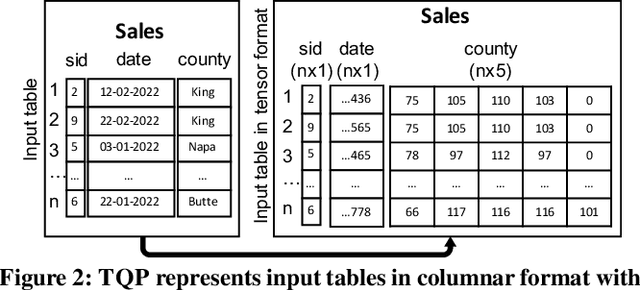
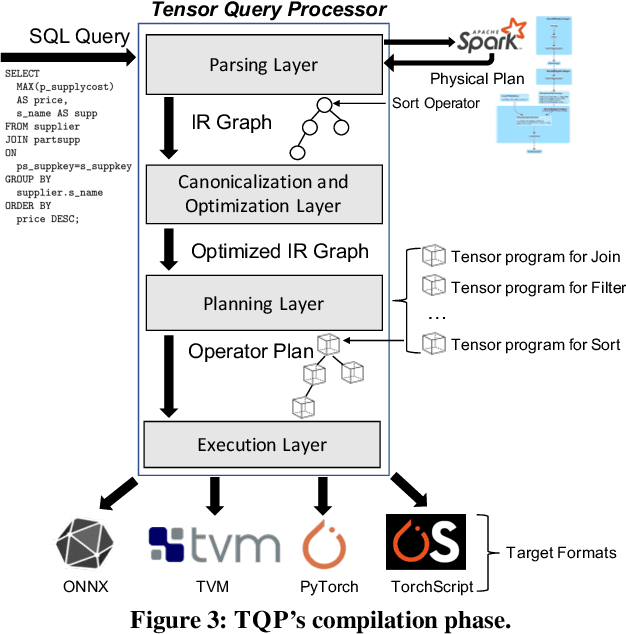
The huge demand for computation in artificial intelligence (AI) is driving unparalleled investments in new hardware and software systems for AI. This leads to an explosion in the number of specialized hardware devices, which are now part of the offerings of major cloud providers. Meanwhile, by hiding the low-level complexity through a tensor-based interface, tensor computation runtimes (TCRs) such as PyTorch allow data scientists to efficiently exploit the exciting capabilities offered by the new hardware. In this paper, we explore how databases can ride the wave of innovation happening in the AI space. Specifically, we present Tensor Query Processor (TQP): a SQL query processor leveraging the tensor interface of TCRs. TQP is able to efficiently run the full TPC-H benchmark by implementing novel algorithms for executing relational operators on the specialized tensor routines provided by TCRs. Meanwhile, TQP can target various hardware while only requiring a fraction of the usual development effort. Experiments show that TQP can improve query execution time by up to 20x over CPU-only systems, and up to 5x over specialized GPU solutions. Finally, TQP can accelerate queries mixing ML predictions and SQL end-to-end, and deliver up to 5x speedup over CPU baselines.
Predictive Price-Performance Optimization for Serverless Query Processing
Dec 16, 2021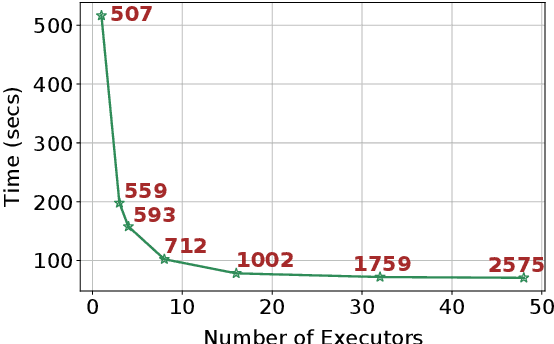
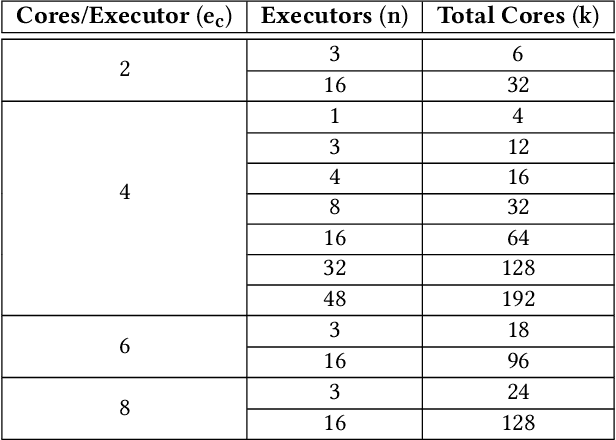
We present an efficient, parametric modeling framework for predictive resource allocations, focusing on the amount of computational resources, that can optimize for a range of price-performance objectives for data analytics in serverless query processing settings. We discuss and evaluate in depth how our system, AutoExecutor, can use this framework to automatically select near-optimal executor and core counts for Spark SQL queries running on Azure Synapse. Our techniques improve upon Spark's in-built, reactive, dynamic executor allocation capabilities by substantially reducing the total executors allocated and executor occupancy while running queries, thereby freeing up executors that can potentially be used by other concurrent queries or in reducing the overall cluster provisioning needs. In contrast with post-execution analysis tools such as Sparklens, we predict resource allocations for queries before executing them and can also account for changes in input data sizes for predicting the desired allocations.
Optimal Resource Allocation for Serverless Queries
Jul 19, 2021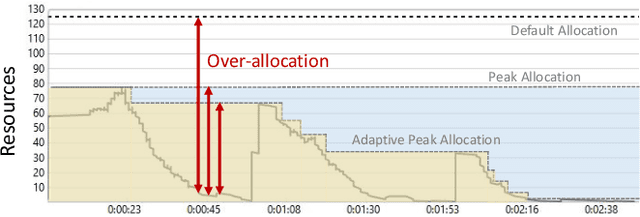
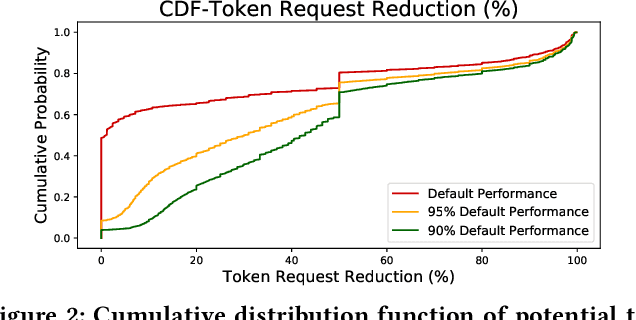

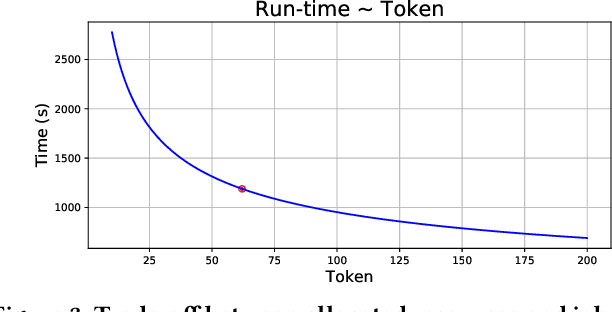
Optimizing resource allocation for analytical workloads is vital for reducing costs of cloud-data services. At the same time, it is incredibly hard for users to allocate resources per query in serverless processing systems, and they frequently misallocate by orders of magnitude. Unfortunately, prior work focused on predicting peak allocation while ignoring aggressive trade-offs between resource allocation and run-time. Additionally, these methods fail to predict allocation for queries that have not been observed in the past. In this paper, we tackle both these problems. We introduce a system for optimal resource allocation that can predict performance with aggressive trade-offs, for both new and past observed queries. We introduce the notion of a performance characteristic curve (PCC) as a parameterized representation that can compactly capture the relationship between resources and performance. To tackle training data sparsity, we introduce a novel data augmentation technique to efficiently synthesize the entire PCC using a single run of the query. Lastly, we demonstrate the advantages of a constrained loss function coupled with GNNs, over traditional ML methods, for capturing the domain specific behavior through an extensive experimental evaluation over SCOPE big data workloads at Microsoft.
Extending Relational Query Processing with ML Inference
Nov 01, 2019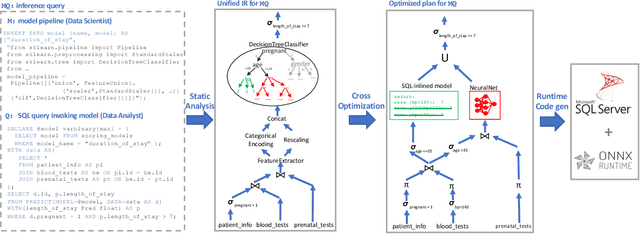

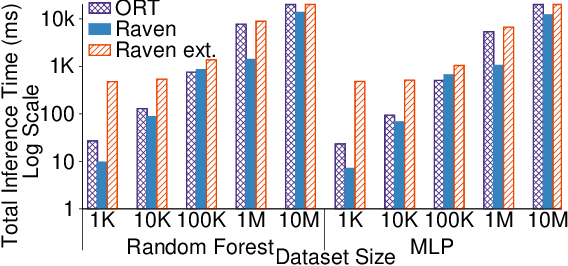
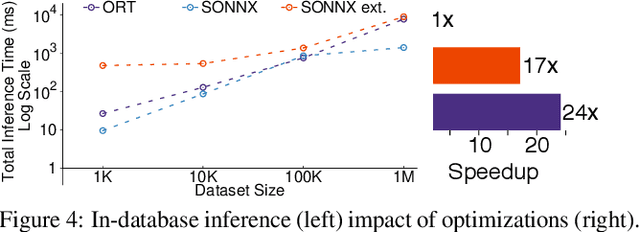
The broadening adoption of machine learning in the enterprise is increasing the pressure for strict governance and cost-effective performance, in particular for the common and consequential steps of model storage and inference. The RDBMS provides a natural starting point, given its mature infrastructure for fast data access and processing, along with support for enterprise features (e.g., encryption, auditing, high-availability). To take advantage of all of the above, we need to address a key concern: Can in-RDBMS scoring of ML models match (outperform?) the performance of dedicated frameworks? We answer the above positively by building Raven, a system that leverages native integration of ML runtimes (i.e., ONNX Runtime) deep within SQL Server, and a unified intermediate representation (IR) to enable advanced cross-optimizations between ML and DB operators. In this optimization space, we discover the most exciting research opportunities that combine DB/Compiler/ML thinking. Our initial evaluation on real data demonstrates performance gains of up to 5.5x from the native integration of ML in SQL Server, and up to 24x from cross-optimizations--we will demonstrate Raven live during the conference talk.
Cloudy with high chance of DBMS: A 10-year prediction for Enterprise-Grade ML
Aug 30, 2019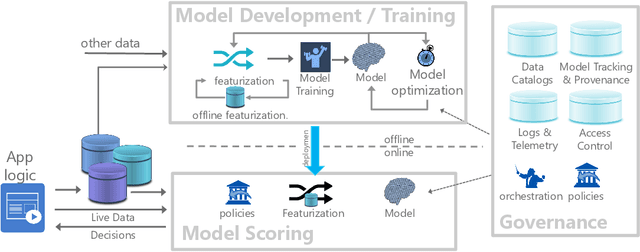
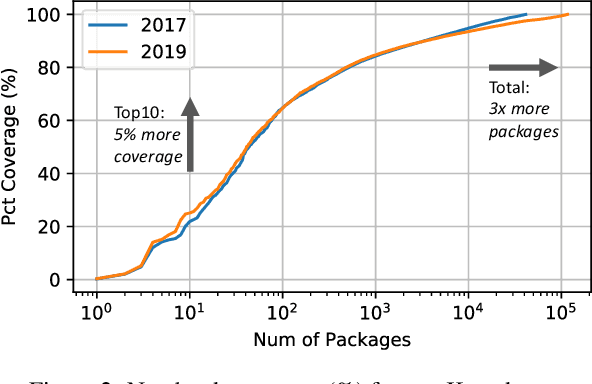
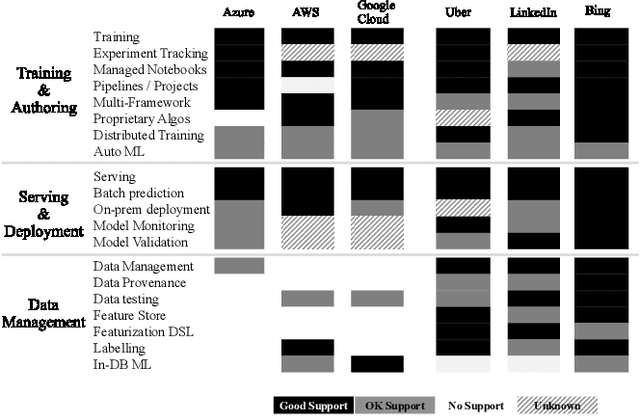
Machine learning (ML) has proven itself in high-value web applications such as search ranking and is emerging as a powerful tool in a much broader range of enterprise scenarios including voice recognition and conversational understanding for customer support, autotuning for videoconferencing, inteligent feedback loops in largescale sysops, manufacturing and autonomous vehicle management, complex financial predictions, just to name a few. Meanwhile, as the value of data is increasingly recognized and monetized, concerns about securing valuable data and risks to individual privacy have been growing. Consequently, rigorous data management has emerged as a key requirement in enterprise settings. How will these trends (ML growing popularity, and stricter data governance) intersect? What are the unmet requirements for applying ML in enterprise settings? What are the technical challenges for the DB community to solve? In this paper, we present our vision of how ML and database systems are likely to come together, and early steps we take towards making this vision a reality.