 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Price-Performance Optimization for Serverless Query Processing
Paper and Code
Dec 16, 2021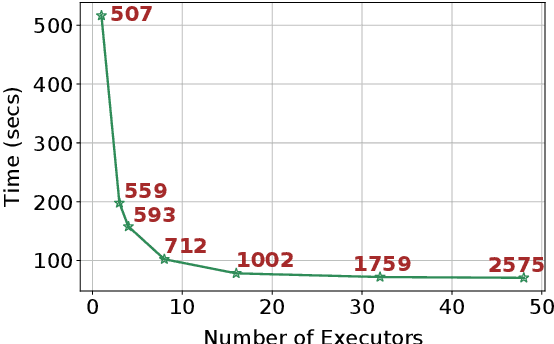
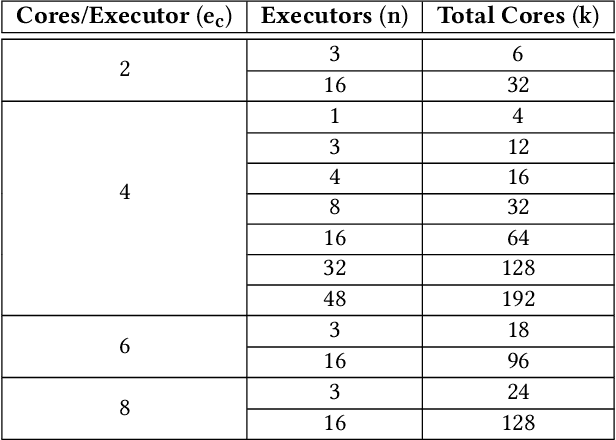
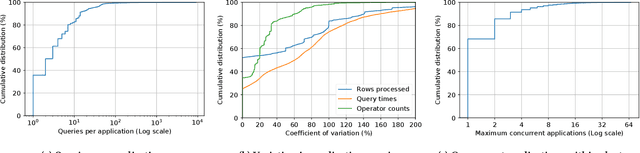
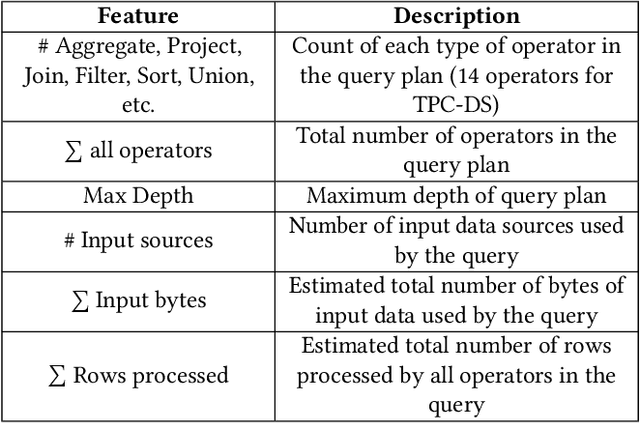
We present an efficient, parametric modeling framework for predictive resource allocations, focusing on the amount of computational resources, that can optimize for a range of price-performance objectives for data analytics in serverless query processing settings. We discuss and evaluate in depth how our system, AutoExecutor, can use this framework to automatically select near-optimal executor and core counts for Spark SQL queries running on Azure Synapse. Our techniques improve upon Spark's in-built, reactive, dynamic executor allocation capabilities by substantially reducing the total executors allocated and executor occupancy while running queries, thereby freeing up executors that can potentially be used by other concurrent queries or in reducing the overall cluster provisioning needs. In contrast with post-execution analysis tools such as Sparklens, we predict resource allocations for queries before executing them and can also account for changes in input data sizes for predicting the desired allocations.