 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Language Models for Harmful Manipulation
Mar 26, 2026Interest in the concept of AI-driven harmful manipulation is growing, yet current approaches to evaluating it are limited. This paper introduces a framework for evaluating harmful AI manipulation via context-specific human-AI interaction studies. We illustrate the utility of this framework by assessing an AI model with 10,101 participants spanning interactions in three AI use domains (public policy, finance, and health) and three locales (US, UK, and India). Overall, we find that that the tested model can produce manipulative behaviours when prompted to do so and, in experimental settings, is able to induce belief and behaviour changes in study participants. We further find that context matters: AI manipulation differs between domains, suggesting that it needs to be evaluated in the high-stakes context(s) in which an AI system is likely to be used. We also identify significant differences across our tested geographies, suggesting that AI manipulation results from one geographic region may not generalise to others. Finally, we find that the frequency of manipulative behaviours (propensity) of an AI model is not consistently predictive of the likelihood of manipulative success (efficacy), underscoring the importance of studying these dimensions separately. To facilitate adoption of our evaluation framework, we detail our testing protocols and make relevant materials publicly available. We conclude by discussing open challenges in evaluating harmful manipulation by AI models.
Online Covariance Estimation in Nonsmooth Stochastic Approximation
Feb 07, 2025
We consider applying stochastic approximation (SA) methods to solve nonsmooth variational inclusion problems. Existing studies have shown that the averaged iterates of SA methods exhibit asymptotic normality, with an optimal limiting covariance matrix in the local minimax sense of H\'ajek and Le Cam. However, no methods have been proposed to estimate this covariance matrix in a nonsmooth and potentially non-monotone (nonconvex) setting. In this paper, we study an online batch-means covariance matrix estimator introduced in Zhu et al.(2023). The estimator groups the SA iterates appropriately and computes the sample covariance among batches as an estimate of the limiting covariance. Its construction does not require prior knowledge of the total sample size, and updates can be performed recursively as new data arrives. We establish that, as long as the batch size sequence is properly specified (depending on the stepsize sequence), the estimator achieves a convergence rate of order $O(\sqrt{d}n^{-1/8+\varepsilon})$ for any $\varepsilon>0$, where $d$ and $n$ denote the problem dimensionality and the number of iterations (or samples) used. Although the problem is nonsmooth and potentially non-monotone (nonconvex), our convergence rate matches the best-known rate for covariance estimation methods using only first-order information in smooth and strongly-convex settings. The consistency of this covariance estimator enables asymptotically valid statistical inference, including constructing confidence intervals and performing hypothesis testing.
Stochastic Optimization Algorithms for Instrumental Variable Regression with Streaming Data
May 29, 2024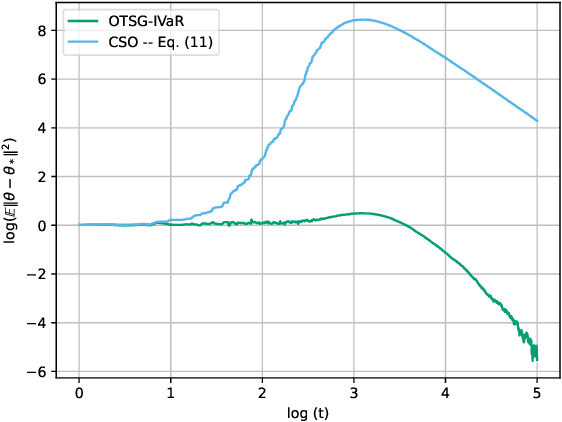

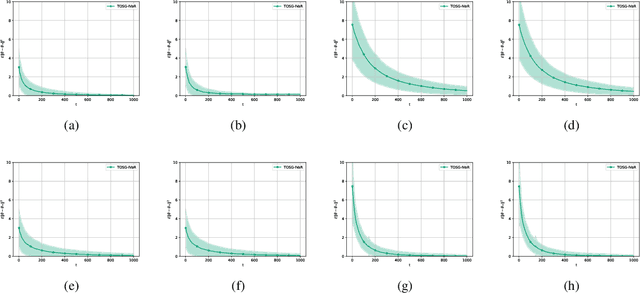
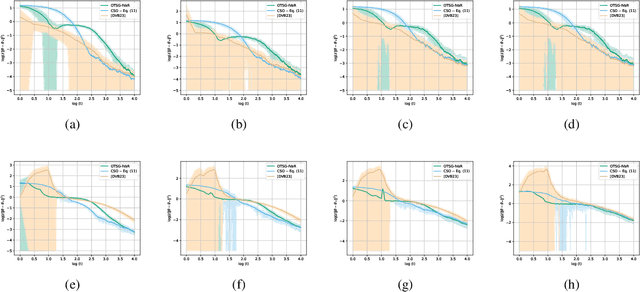
We develop and analyze algorithms for instrumental variable regression by viewing the problem as a conditional stochastic optimization problem. In the context of least-squares instrumental variable regression, our algorithms neither require matrix inversions nor mini-batches and provides a fully online approach for performing instrumental variable regression with streaming data. When the true model is linear, we derive rates of convergence in expectation, that are of order $\mathcal{O}(\log T/T)$ and $\mathcal{O}(1/T^{1-\iota})$ for any $\iota>0$, respectively under the availability of two-sample and one-sample oracles, respectively, where $T$ is the number of iterations. Importantly, under the availability of the two-sample oracle, our procedure avoids explicitly modeling and estimating the relationship between confounder and the instrumental variables, demonstrating the benefit of the proposed approach over recent works based on reformulating the problem as minimax optimization problems. Numerical experiments are provided to corroborate the theoretical results.
Optimization on Pareto sets: On a theory of multi-objective optimization
Aug 04, 2023
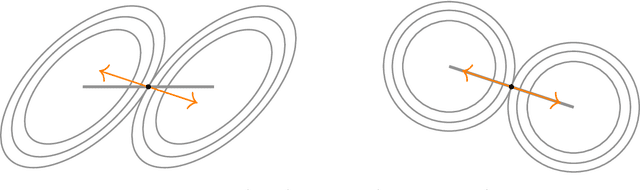
In multi-objective optimization, a single decision vector must balance the trade-offs between many objectives. Solutions achieving an optimal trade-off are said to be Pareto optimal: these are decision vectors for which improving any one objective must come at a cost to another. But as the set of Pareto optimal vectors can be very large, we further consider a more practically significant Pareto-constrained optimization problem, where the goal is to optimize a preference function constrained to the Pareto set. We investigate local methods for solving this constrained optimization problem, which poses significant challenges because the constraint set is (i) implicitly defined, and (ii) generally non-convex and non-smooth, even when the objectives are. We define notions of optimality and stationarity, and provide an algorithm with a last-iterate convergence rate of $O(K^{-1/2})$ to stationarity when the objectives are strongly convex and Lipschitz smooth.
Online covariance estimation for stochastic gradient descent under Markovian sampling
Aug 03, 2023We study the online overlapping batch-means covariance estimator for Stochastic Gradient Descent (SGD) under Markovian sampling. We show that the convergence rates of the covariance estimator are $O\big(\sqrt{d}\,n^{-1/8}(\log n)^{1/4}\big)$ and $O\big(\sqrt{d}\,n^{-1/8}\big)$ under state-dependent and state-independent Markovian sampling, respectively, with $d$ representing dimensionality and $n$ denoting the number of observations or SGD iterations. Remarkably, these rates match the best-known convergence rate previously established for the independent and identically distributed ($\iid$) case by \cite{zhu2021online}, up to logarithmic factors. Our analysis overcomes significant challenges that arise due to Markovian sampling, leading to the introduction of additional error terms and complex dependencies between the blocks of the batch-means covariance estimator. Moreover, we establish the convergence rate for the first four moments of the $\ell_2$ norm of the error of SGD dynamics under state-dependent Markovian data, which holds potential interest as an independent result. To validate our theoretical findings, we provide numerical illustrations to derive confidence intervals for SGD when training linear and logistic regression models under Markovian sampling. Additionally, we apply our approach to tackle the intriguing problem of strategic classification with logistic regression, where adversaries can adaptively modify features during the training process to increase their chances of being classified in a specific target class.
Fairness Uncertainty Quantification: How certain are you that the model is fair?
Apr 27, 2023Fairness-aware machine learning has garnered significant attention in recent years because of extensive use of machine learning in sensitive applications like judiciary systems. Various heuristics, and optimization frameworks have been proposed to enforce fairness in classification \cite{del2020review} where the later approaches either provides empirical results or provides fairness guarantee for the exact minimizer of the objective function \cite{celis2019classification}. In modern machine learning, Stochastic Gradient Descent (SGD) type algorithms are almost always used as training algorithms implying that the learned model, and consequently, its fairness properties are random. Hence, especially for crucial applications, it is imperative to construct Confidence Interval (CI) for the fairness of the learned model. In this work we provide CI for test unfairness when a group-fairness-aware, specifically, Disparate Impact (DI), and Disparate Mistreatment (DM) aware linear binary classifier is trained using online SGD-type algorithms. We show that asymptotically a Central Limit Theorem holds for the estimated model parameter of both DI and DM-aware models. We provide online multiplier bootstrap method to estimate the asymptotic covariance to construct online CI. To do so, we extend the known theoretical guarantees shown on the consistency of the online bootstrap method for unconstrained SGD to constrained optimization which could be of independent interest. We illustrate our results on synthetic and real datasets.
Sketch2FullStack: Generating Skeleton Code of Full Stack Website and Application from Sketch using Deep Learning and Computer Vision
Nov 26, 2022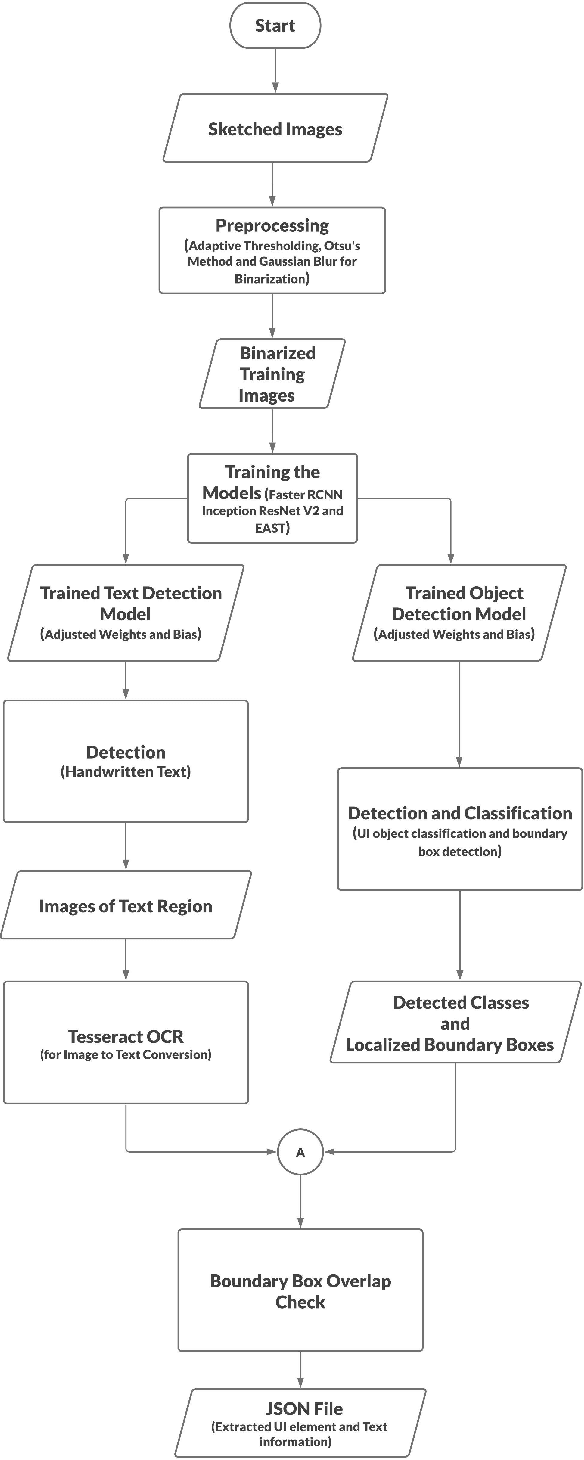

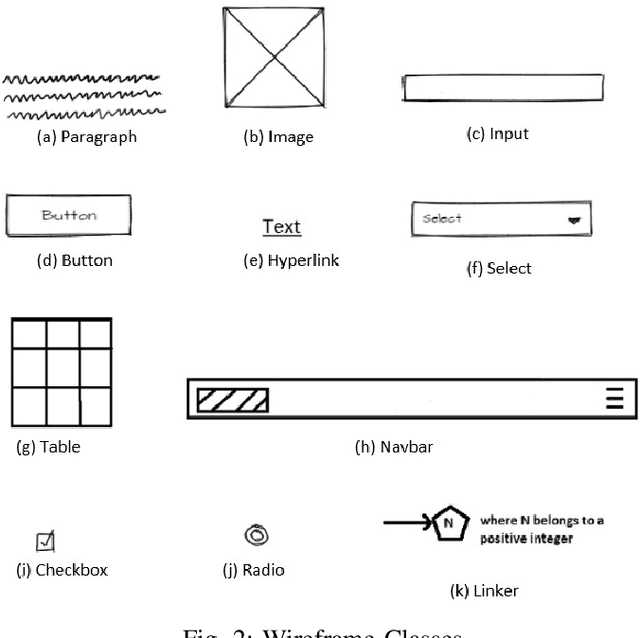
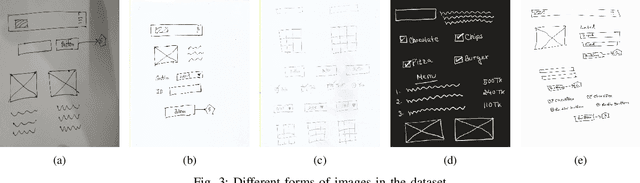
For a full-stack web or app development, it requires a software firm or more specifically a team of experienced developers to contribute a large portion of their time and resources to design the website and then convert it to code. As a result, the efficiency of the development team is significantly reduced when it comes to converting UI wireframes and database schemas into an actual working system. It would save valuable resources and fasten the overall workflow if the clients or developers can automate this process of converting the pre-made full-stack website design to get a partially working if not fully working code. In this paper, we present a novel approach of generating the skeleton code from sketched images using Deep Learning and Computer Vision approaches. The dataset for training are first-hand sketched images of low fidelity wireframes, database schemas and class diagrams. The approach consists of three parts. First, the front-end or UI elements detection and extraction from custom-made UI wireframes. Second, individual database table creation from schema designs and lastly, creating a class file from class diagrams.
Projection-free Constrained Stochastic Nonconvex Optimization with State-dependent Markov Data
Jun 22, 2022

We study a projection-free conditional gradient-type algorithm for constrained nonconvex stochastic optimization problems with Markovian data. In particular, we focus on the case when the transition kernel of the Markov chain is state-dependent. Such stochastic optimization problems arise in various machine learning problems including strategic classification and reinforcement learning. For this problem, we establish that the number of calls to the stochastic first-order oracle and the linear minimization oracle to obtain an appropriately defined $\epsilon$-stationary point, are of the order $\mathcal{O}(1/\epsilon^{2.5})$ and $\mathcal{O}(1/\epsilon^{5.5})$ respectively. We also empirically demonstrate the performance of our algorithm on the problem of strategic classification with neural networks.
Plagiarism Detection in the Bengali Language: A Text Similarity-Based Approach
Mar 25, 2022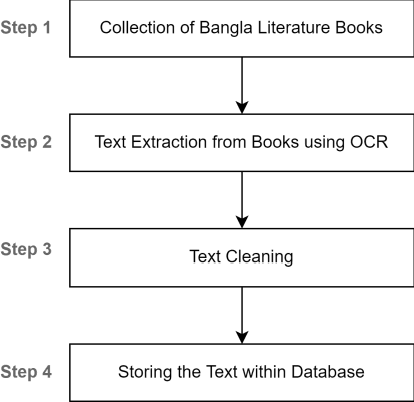
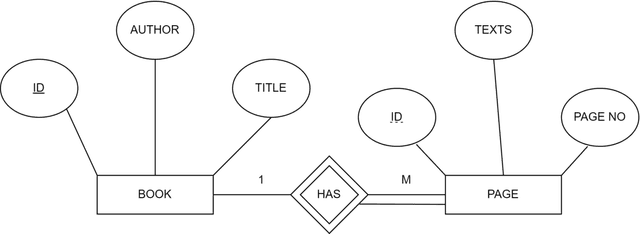


Plagiarism means taking another person's work and not giving any credit to them for it. Plagiarism is one of the most serious problems in academia and among researchers. Even though there are multiple tools available to detect plagiarism in a document but most of them are domain-specific and designed to work in English texts, but plagiarism is not limited to a single language only. Bengali is the most widely spoken language of Bangladesh and the second most spoken language in India with 300 million native speakers and 37 million second-language speakers. Plagiarism detection requires a large corpus for comparison. Bengali Literature has a history of 1300 years. Hence most Bengali Literature books are not yet digitalized properly. As there was no such corpus present for our purpose so we have collected Bengali Literature books from the National Digital Library of India and with a comprehensive methodology extracted texts from it and constructed our corpus. Our experimental results find out average accuracy between 72.10 % - 79.89 % in text extraction using OCR. Levenshtein Distance algorithm is used for determining Plagiarism. We have built a web application for end-user and successfully tested it for Plagiarism detection in Bengali texts. In future, we aim to construct a corpus with more books for more accurate detection.
Predictive Closed-Loop Service Automation in O-RAN based Network Slicing
Feb 04, 2022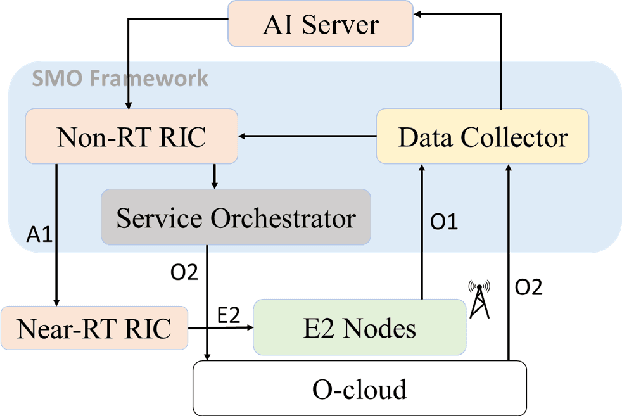
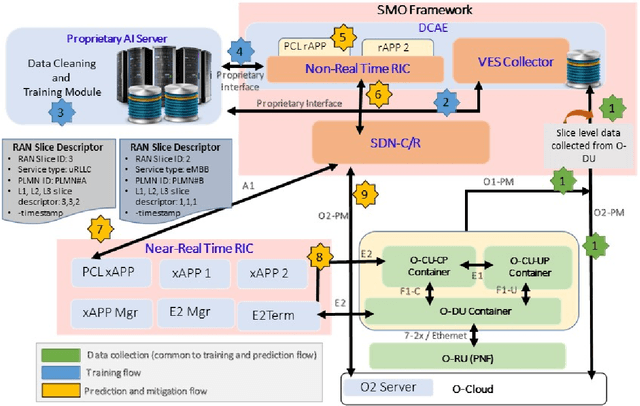
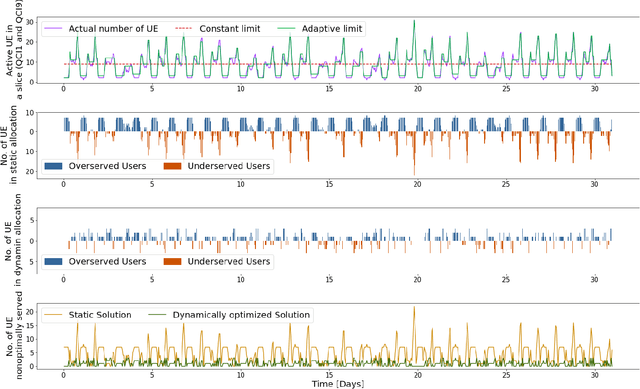
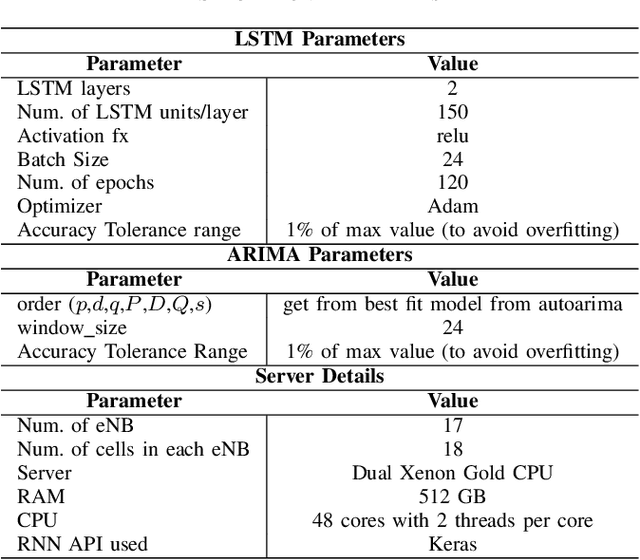
Network slicing provides introduces customized and agile network deployment for managing different service types for various verticals under the same infrastructure. To cater to the dynamic service requirements of these verticals and meet the required quality-of-service (QoS) mentioned in the service-level agreement (SLA), network slices need to be isolated through dedicated elements and resources. Additionally, allocated resources to these slices need to be continuously monitored and intelligently managed. This enables immediate detection and correction of any SLA violation to support automated service assurance in a closed-loop fashion. By reducing human intervention, intelligent and closed-loop resource management reduces the cost of offering flexible services. Resource management in a network shared among verticals (potentially administered by different providers), would be further facilitated through open and standardized interfaces. Open radio access network (O-RAN) is perhaps the most promising RAN architecture that inherits all the aforementioned features, namely intelligence, open and standard interfaces, and closed control loop. Inspired by this, in this article we provide a closed-loop and intelligent resource provisioning scheme for O-RAN slicing to prevent SLA violations. In order to maintain realism, a real-world dataset of a large operator is used to train a learning solution for optimizing resource utilization in the proposed closed-loop service automation process. Moreover, the deployment architecture and the corresponding flow that are cognizant of the O-RAN requirements are also discussed.